多代理AdaBoost算法:利用二级结构预测蛋白质结构类别
169 浏览量
更新于2024-07-15
收藏 601KB PDF 举报
本文介绍了一项创新的多智能体AdaBoost算法,用于预测蛋白质的结构类别,该算法充分利用了蛋白质二级结构的信息。这项研究由Ming Fan、Bin Zheng和Lihua Li三位作者共同完成,他们分别来自杭州电子科技大学的生物医学工程与仪器研究所和湖南机电职业技术学院。
在蛋白质结构预测领域,了解一个特定蛋白质的结构类别对于理解其折叠模式至关重要。然而,仅根据蛋白质序列预测其结构类别仍然是一个具有挑战性的任务。论文的核心关注点在于两个关键问题:蛋白质特征提取和分类。研究人员在此前工作的基础上,对这两个方面进行了扩展。
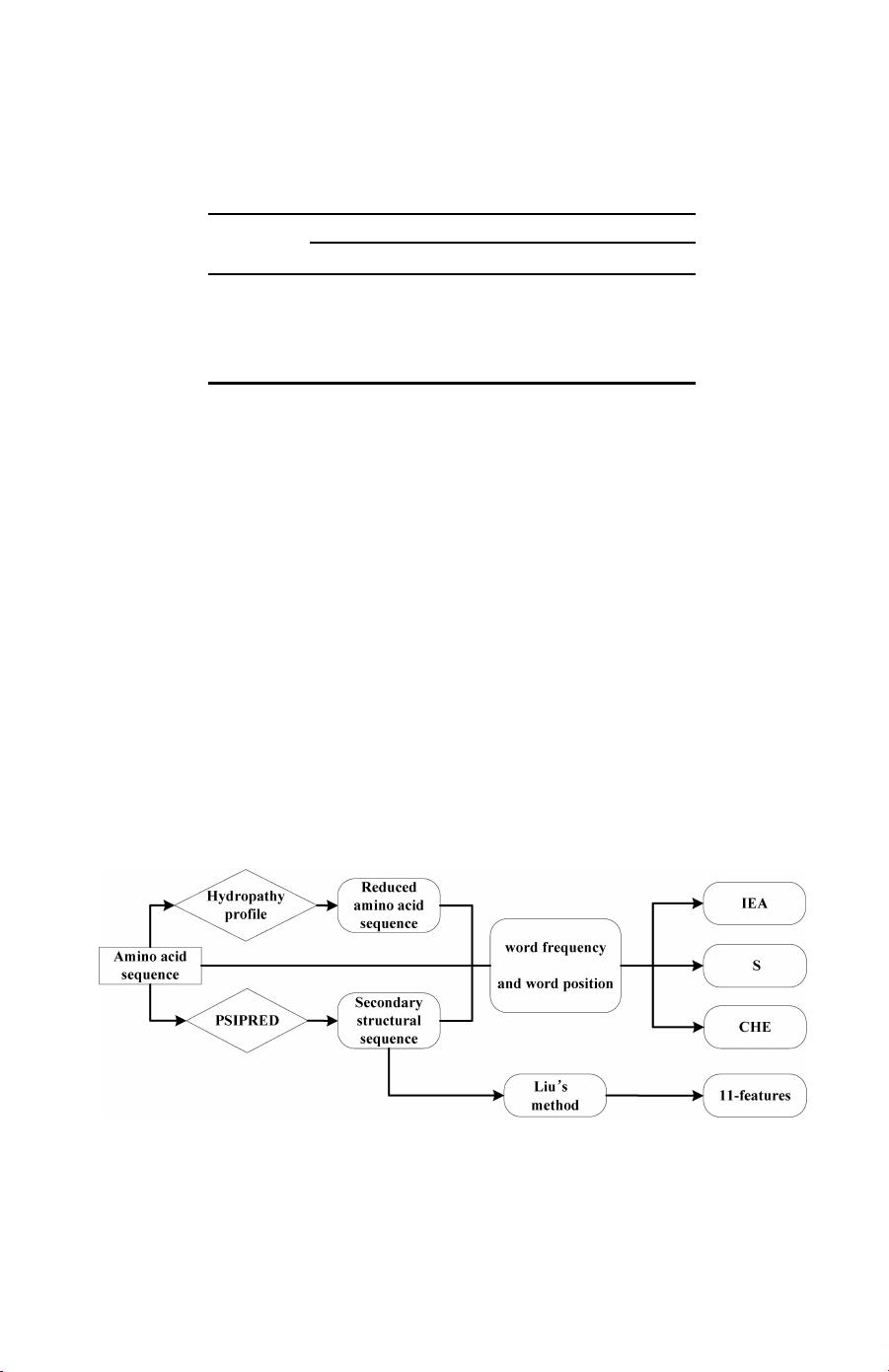
在特征提取方面,他们提出了一种新的方法,通过计算氨基酸序列、缩减后的氨基酸以及二级结构中的词频和词位置来构建特征。这种方法旨在捕捉序列和二级结构之间的关联,以便更准确地反映蛋白质的潜在结构特性。相比于传统的基于单一序列信息的预测,引入二级结构作为额外输入可以提供更为丰富的信息,从而提高预测的精度。
AdaBoost(Adaptive Boosting)算法在此被多智能体化,意味着算法通过集成多个弱分类器形成一个强分类器,每个智能体负责处理部分数据并学习独立的模型。这种分布式和协作的学习方式有助于降低单个模型的过拟合风险,并可能提高整体性能。通过不断迭代,这些智能体协同工作,逐步调整权重分配,优化预测结果。
此外,研究者在2015年3月20日首次接收论文,经过修订后于7月24日接受,最终在同年9月8日发表。这表明他们的工作经过了严谨的同行评审过程,研究成果具有较高的科学价值和实用性。
总结来说,这篇论文创新性地将多智能体AdaBoost技术与蛋白质二级结构信息相结合,解决蛋白质结构预测中的特征提取和分类问题,为该领域的预测准确性提供了新的解决方案。这对于理解蛋白质的功能、进化以及疾病相关的蛋白质结构变化具有重要意义。
ambivalent group, and external group.
30,31
Therefore, a protein sequence S can be
de¯ned according to the following rule:
F ðSðiÞÞ ¼
ISðiÞ¼F ; I; L; M; V
ESðiÞ¼D; E; H; K; N; Q; R
ASðiÞ¼S; T ; Y ; C; W; G; P ; A
8
<
:
; ð1Þ
where SðiÞ is the letter to represent the amino acids on the ith position of protein
primary structure S and F ðSðiÞÞ is the hydropathy type for SðiÞ, grouped into three
types: I (internal), E (external), and A (ambivalent). Therefore, a reduced amino
acid sequence composed of I, E, and A can be derived from a given protein sequenc e
according to this hydropathy ¯le.
(2) Secondary structure
Protein secondary structure refers to the local section of the peptide ch ain folding
under certain period of the rules. We predicted the three secondary structural
Fig. 1. Combined feature information. The combined feature information includes four categories, which
are S, IEA, CHE, and 11-features. The features of IEA, S, and CHE are obtained by calculating the word
frequency and word position of the original amino acid sequence, reduced amino acid sequence, and
predicted secondary structure. The 11-dimensionally predicted secondary structural feature vector which
re°ect the spatial arrangement of the secondary structural elements proposed by Liu is calculated based on
secondary structure predicted by using PSI-PRED.
8,32
Table 1. The number of proteins with di®erent structural classes
in datasets.
Number of proteins
Dataset All- All- =
a
þ
b
Total
25PDB 443 443 346 441 1673
FC699 130 269 377 82 858
640 138 154 177 171 640
1189 223 294 334 241 1092
D-B 103 224 268 99 694
a
The = class includes both the helices and mostly parallel strands.
The þ class includes both the helices and mostly antiparallel strands.
M. Fan, B. Zheng & L. Li
1550022-4
剩余16页未读,继续阅读
2020-05-01 上传
2020-01-16 上传
2021-02-20 上传
2021-02-21 上传
2021-02-09 上传
2019-09-17 上传
2018-03-20 上传
2022-07-15 上传
2019-09-17 上传
2023-05-12 上传

weixin_38718434
- 粉丝: 9
- 资源: 929
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
