




Spark Summit 2014: Scalable Distributed Decision Trees in Spark ...
下载需积分: 10 | PDF格式 | 3.98MB |
更新于2024-07-20
| 107 浏览量 | 举报
在2014年的Spark Summit上,一场关于Scalable Distributed Decision Trees in Spark MLlib的讨论引起了广泛关注。这次会议汇集了来自各方的专业人士,包括Manish Amde from OrigamiLogic,Hirakendu Das from Yahoo! Labs,以及Evan Sparks和Ameet Talwalkar,两位分别来自UC Berkeley的研究人员。Ameet Talwalkar拥有加州大学圣地亚哥分校的电子与计算机工程博士学位,专注于数据科学,在OrigamiLogic工作,该公司提供基于搜索的营销智能平台,处理大量且结构复杂的营销数据。
主题涵盖了决策树的基本概念(Decision Tree 101),尤其是如何将这一经典机器学习算法扩展到Spark MLlib的分布式环境。Spark作为一个强大的大数据处理框架,使得在大规模数据集上构建和训练决策树变得高效可行。参与者分享了实验结果,探讨了如何通过集成(Ensembles)来提升模型性能,如随机森林或梯度提升等方法。
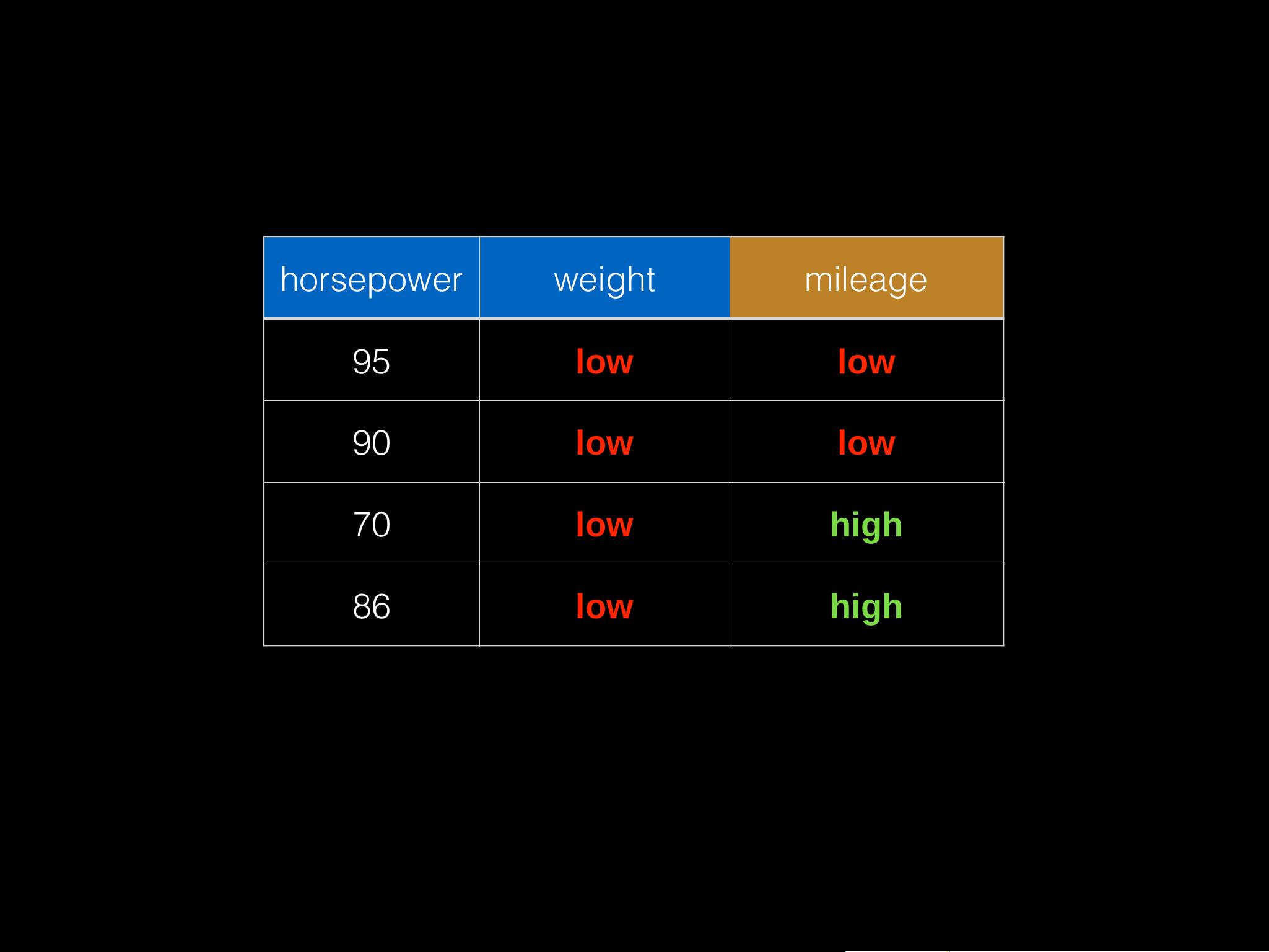
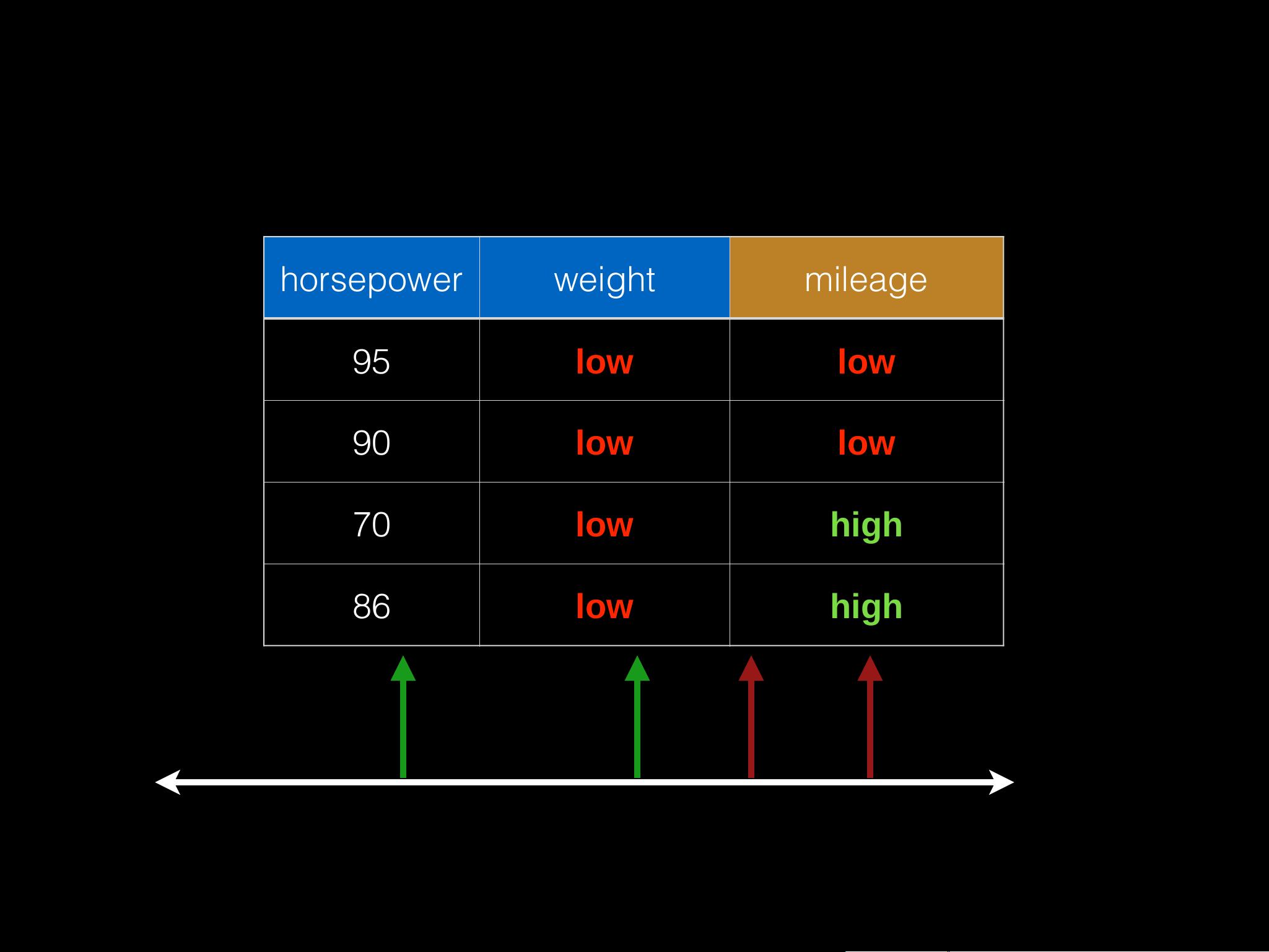
会议上,具体案例被用来说明决策树的应用,比如预测汽车的里程数(一个二元分类问题)。通过分析特征如马力、重量和里程数,参与者展示了如何使用Spark进行预测,将历史数据用于训练模型,并用其规则(例如:马力高和重量轻的车辆可能里程数较高)来指导预测。这个例子展示了如何将决策树应用于实际问题,如汽车维护和性能评估。
此外,讨论还涉及了监督学习的各个方面,包括分类(如二元分类)和回归(预测连续数值),其中标签用于表示类别或数值结果。参与者深入探讨了特征选择、模型训练和预测的过程,以及如何在Spark环境下优化这些步骤,以应对不断增长的数据挑战。
在未来的工作方向中,可能涉及对Spark处理能力和算法效率的进一步提升,以及如何将决策树和其他机器学习技术更好地整合,以适应不断变化的数据科学需求。这次Spark Summit上的分享对于理解和利用Spark进行大规模分布式决策树学习提供了有价值的知识和实践经验。
Find Best Split
labels : {high :4,low :2}
Weight == High
Yes
No
labels : {high :2,low :0}
labels : {high :2,low :2}
(weight, {low,high})
(hp, {70, 76, 86, 88, 90, 95 })
No increase in information gain possible
剩余95页未读,继续阅读
相关推荐
218 浏览量
661 浏览量
2021-04-05 上传
2021-08-04 上传
635 浏览量
2021-04-05 上传
2021-05-15 上传
105 浏览量
152 浏览量

腾讯开发者
- 粉丝: 1495
 我的内容管理
展开
我的内容管理
展开








最新资源
- ASP新闻发布系统重大更新
- 云计算与云存储技术研究:2009-2011英文论文集萃
- NHibernate 1.1 中文版技术文档解析
- JavaScript实例解析:趣味程序导学
- Purple主题:Typecho博客后台的全新视觉体验
- Android沉浸式菜单的实现与应用
- C#游戏编程入门:编程游戏开发必备指南
- DOS命令实用宝典:入门与常用技巧
- MATLAB开发:实现欧拉角度到alpha beta gamma转换
- Windows平台下dd-0.5工具的使用与更新
- Android AsyncTask 实用示例教程详解
- 高效负载均衡工具HAProxy 1.9.5版本发布
- TTALL: 高效 Laravel 前端堆栈预设整合指南
- Windows版dd工具0.6beta3发布详情介绍
- C#在VS2005中实现视频聊天源码分享
- LCD显示技术深度解析及其多样化应用领域






















