




大数据面试必备:Spark, Hadoop, Flink等框架解析
需积分: 5 34 浏览量
更新于2024-06-20
收藏 6.5MB PDF 举报
"大数据面试题目大全,涵盖了包括Hadoop、Spark、Hive、Flink在内的关键框架,适合求职面试者参考。"
本文将详细介绍在大数据领域面试中可能会遇到的重要知识点,按照不同层次进行划分,帮助你更好地准备面试。
第一梯度的知识点包括Spark、Hive、Flink、数据仓库的Kimball建模、Java(特别是Web开发)、Linux命令、SpringMvc、SpringBoot和Mybatis。这些是大数据处理和应用开发的基础,需要深入理解和掌握。
1. Spark:
- Spark的核心特性是快速数据处理,它提供了DataFrame和DataSet API,支持SQL查询,并且在内存计算上具有优势。
- Spark的主要组件包括Spark Core、Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图形处理)。
2. Hive:
- Hive是基于Hadoop的数据仓库工具,用于处理和管理大规模数据。它允许使用类SQL语法(HQL)进行查询和分析。
- Hive的工作流程包括将HQL转换为MapReduce任务,执行在Hadoop集群上。
3. Flink:
- Flink是一个流处理和批处理的框架,强调实时处理和低延迟。
- Flink的关键特性包括状态管理和检查点,用于容错;DataStream和DataSet API支持流和批处理。
4. 数据仓库Kimball建模:
- Kimball方法论是一种事实-维度数据仓库设计方法,强调易于理解和使用的星型或雪花型模式。
- 这种模型便于数据分析,通常包括事实表和维度表,用于报告和OLAP操作。
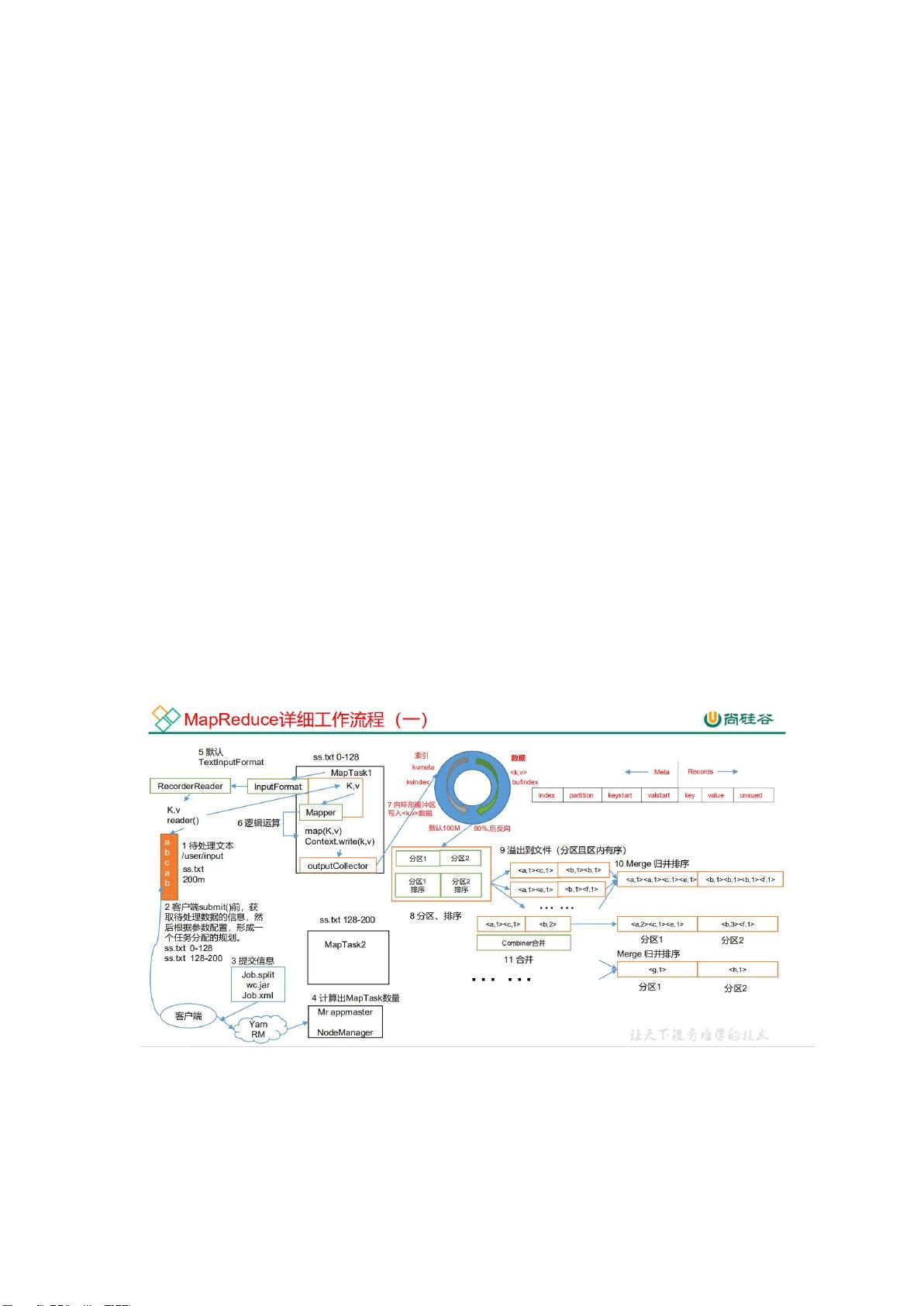
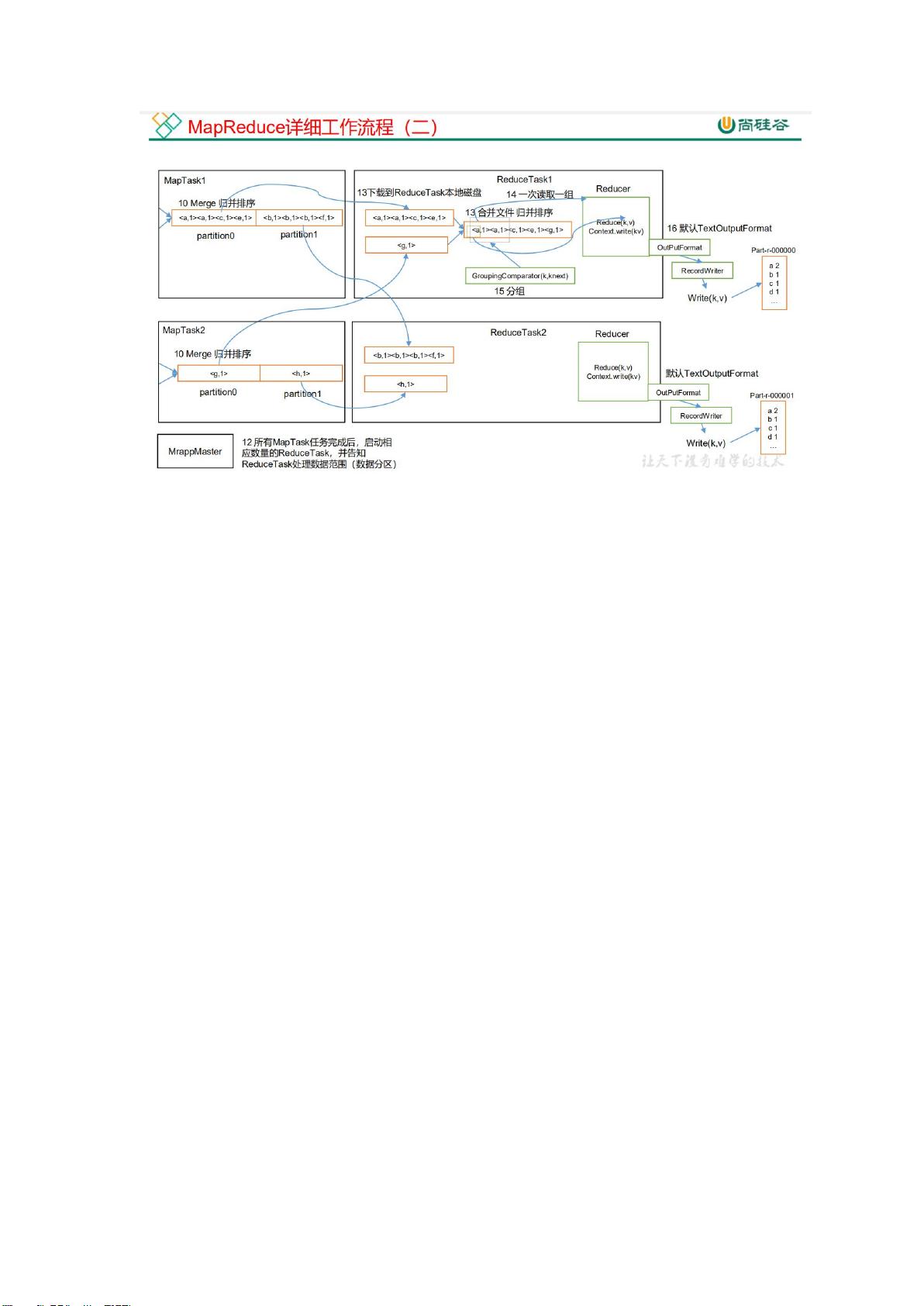
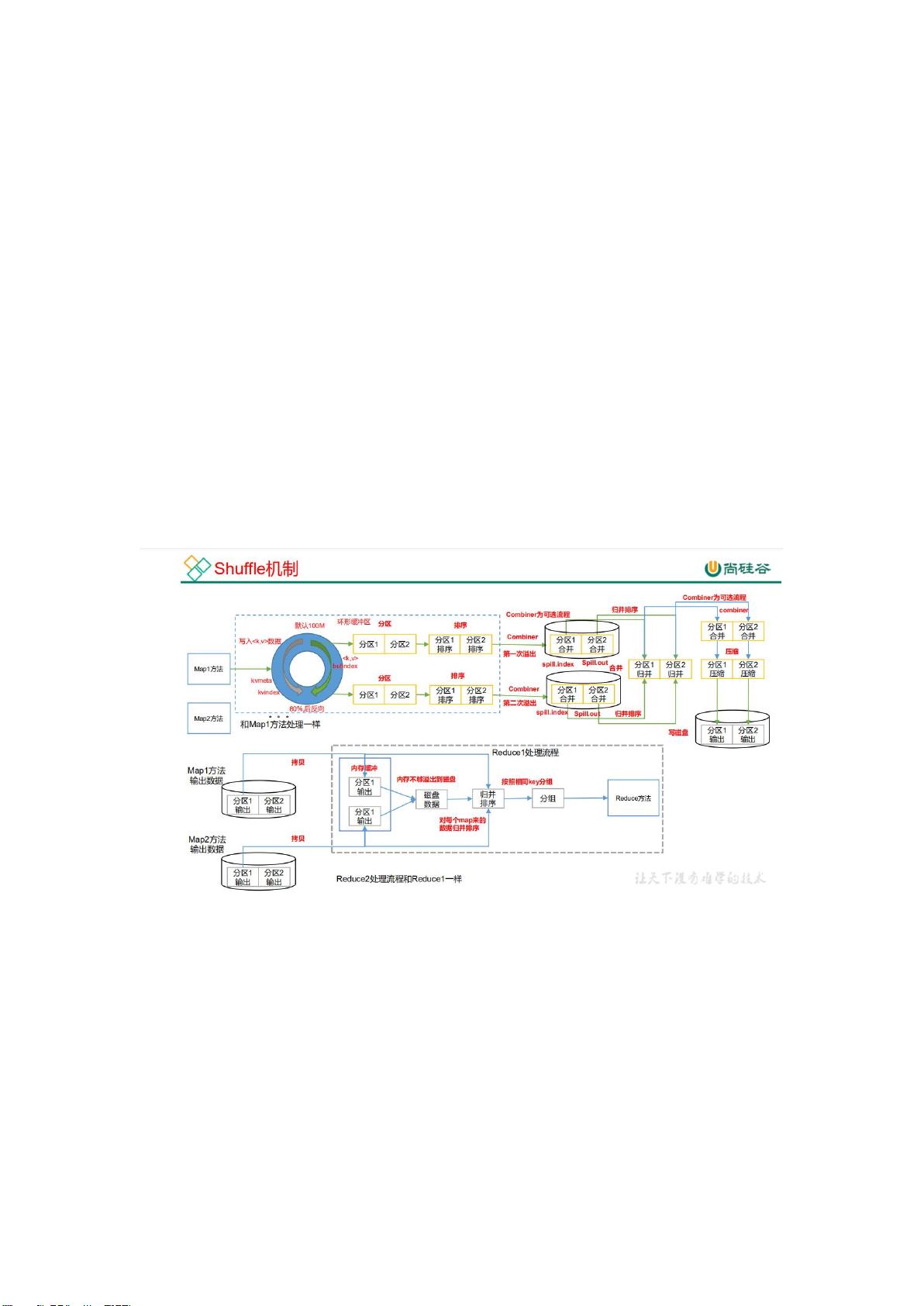
第二梯度深入到Hadoop生态系统,包括Hadoop本身,以及YARN、MapReduce、HDFS,还有Kafka、Hbase和Azkaban(了解程度)。
1. Hadoop:
- Hadoop是大数据处理的基石,由HDFS、MapReduce和YARN组成。
- MapReduce是分布式计算模型,而YARN负责集群资源管理和任务调度。
- HDFS提供了高容错性的分布式文件系统,适合大规模数据存储。
5. Kafka:
- Kafka是一个高吞吐量的分布式消息队列,常用于构建实时数据管道和流处理应用程序。
- 它支持发布/订阅模型,可以作为数据集成和事件驱动架构的关键组件。
6. Hbase:
- Hbase是基于Hadoop的NoSQL数据库,提供实时读写访问大型分布式表。
- 它是列族存储模型,适用于半结构化数据。
第三梯度涉及更高级的主题,如Zookeeper、机器学习和联邦学习。
1. Zookeeper:
- Zookeeper是一个分布式协调服务,用于管理分布式系统的配置信息、命名服务和分布式同步等。
- 在Hadoop生态中,Zookeeper常用于协调HBase、Hadoop和其他服务的节点。
2. 机器学习和联邦学习:
- 机器学习是让计算机通过数据自动学习的过程,涵盖监督学习、非监督学习和强化学习。
- 联邦学习是分布式机器学习的一种形式,允许在本地设备上训练模型,保护数据隐私。
理解并熟练掌握这些知识点,不仅有助于你在面试中表现出色,也能在实际工作中提升处理大数据问题的能力。确保对每个框架和概念都有深入的理解,包括其工作原理、用例和最佳实践。同时,熟悉Linux命令和Java Web开发基础,对于大数据工程师来说同样重要,因为它们是实现和部署大数据解决方案的常见工具。

<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>1048576</value>
</property>
如果集群规模较大,为了防止负载均衡对正常的业务读写造成影响,应当在
集群空闲的时候,手动执行负载均衡。
手动命令如下:
# 任意两个节点之间的存储百分比不超过 10%
sbin/start-balancer.sh -t 10%
1.1.12. HDFS 的安全模式
何时进入安全模式?
集群启动时进入
手动进入
节点丢失块多的时候进入
安全模式有什么特点?
文件只能做读取工作,不能修改,写入,追加等操作
在安全模式下集群在做什么?
DataNode 向 NameNode 做汇报
集群恢复上一次关机时状态
如何进入/退出安全模式?
进入 hdfs dfsadmin -safemode enter
退出
hdfs dfsadmin -safemode leave
1.1.13. Hadoop 集群中的主要进程和作用?
NameNode
进程,它是
hadoop
中的主服务进程,管理文件系统名
称空间和对集群中存储的文件的访问,保存有 metadate。
SecondaryNameNode 进程,它不是 namenode 的冗余守护进程,
而是提供周期检查点和清理任务。帮助
NN
合并
editslog
,减少
NN
启动时
间。
DataNode 进程,它负责管理连接到节点的存储(一个集群中可以有
多个节点)。每个存储数据的节点运行一个
datanode
守护进程。
ResourceManager ( JobTracker ) 进 程 , JobTracker 负 责 调 度
DataNode 上的工作。每个 DataNode 有一个 TaskTracker,它们执行实际
工作。

剩余139页未读,继续阅读
136 浏览量
点击了解资源详情
151 浏览量
258 浏览量
2019-06-24 上传

FlyBeautySky
- 粉丝: 1118
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- PHP and MySQL Web Development (4rd Edition, 第四版)
- Assembly Language Step-by-Step Programming with DOS and Linux, 2nd Edition 英文版 (pdf)
- Visual C++开发工具与调试技巧整理
- Solutions for Introduction to Algorithms(算法导论答案)
- 基于DSP控制的直流电机调速设计
- 智能语音拨号报警系统
- 基于MPX4105芯片的数字气压计设计.pdf
- 《jsp设计》第二版 电子书
- VF人事管理系统课程设计
- 计算机组装与维护论文
- VB学生信息管理系统
- MC9S12XS256RMV1
- c语言程序设计电子课件
- ISE9.01使用教程
- 管理学:原理与方法PPT8
- QTP8_Tutorial_cn










