决策树、随机森林与Adaboost算法详解
需积分: 29 14 浏览量
更新于2024-07-18
收藏 1.1MB PDF 举报
"这篇文档是关于机器学习中决策树、随机森林和adaboost的教程,由七月算法龙老师在2016年5月28日分享。内容包括信息熵、互信息、决策树的基本概念、ID3、C4.5、CART算法、Bagging与随机森林的介绍,以及提升方法如Adaboost和GDBT的讲解。"
在机器学习领域,决策树是一种常用且直观的分类和回归模型。决策树以树状结构表示,其中每个内部节点代表一个特征或属性测试,每个分支代表一个测试输出,而每个叶节点则代表一个类别决定。决策树学习过程通常采用自顶向下的递归方式,从根节点开始,通过不断选择最佳特征来划分数据,直到满足停止条件,例如达到预设的深度或者纯度。
信息熵是衡量数据集中不确定性的度量。熵越大,数据集的不确定性越高。互信息是衡量两个随机变量之间相互依赖程度的指标,表示得知一个变量的信息可以减少另一个变量的不确定性。在决策树中,选择最佳分割特征时,信息增益是一个重要的度量标准,它是数据集的熵减去特征给定条件下的条件熵,即特征划分后的信息熵总和。信息增益越大,意味着特征对数据集的划分能力越强。
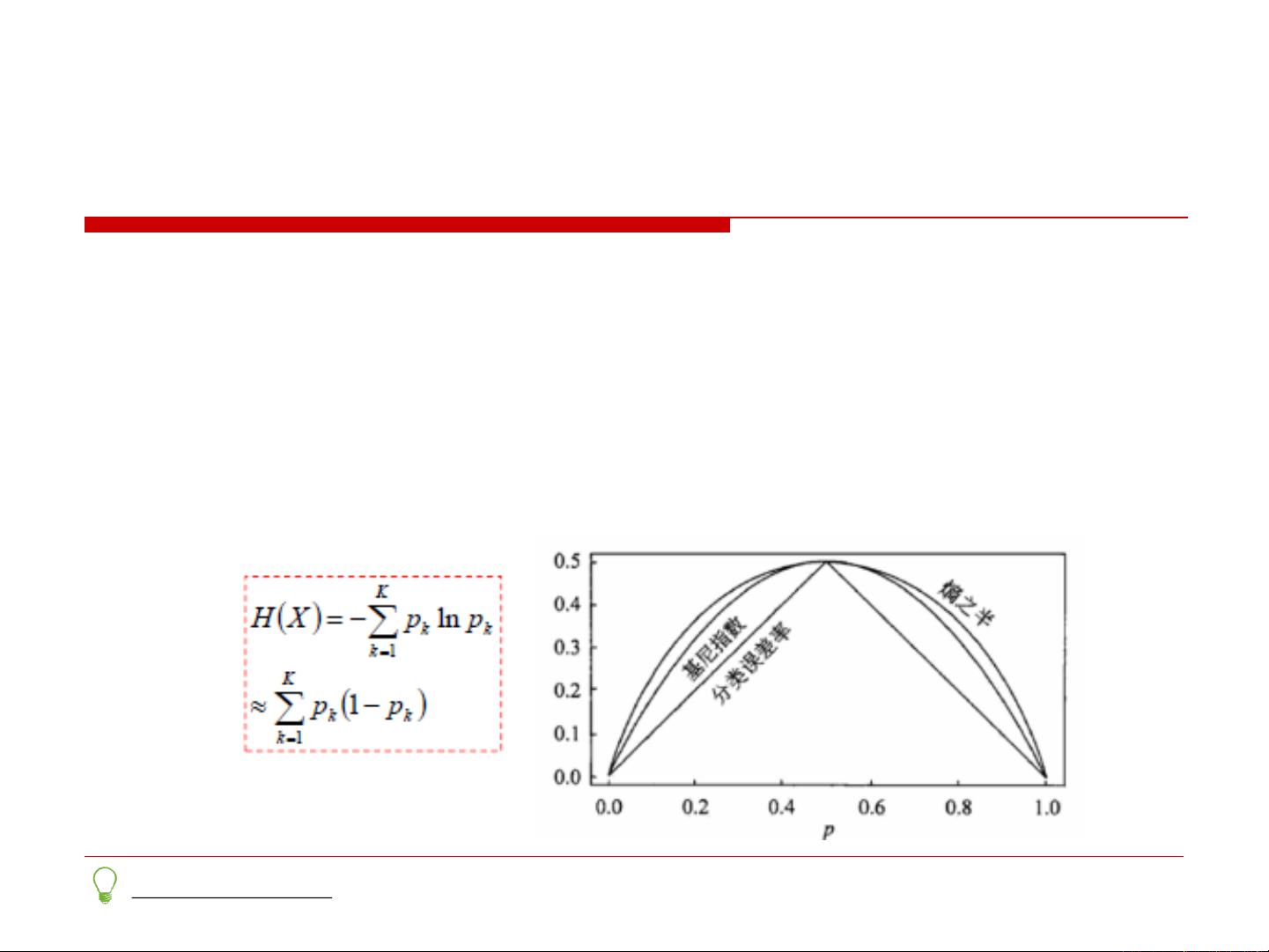
然而,信息增益有时会偏向于选择具有大量值的特征,因此出现了信息增益率(C4.5)和基尼系数(CART)作为替代选择。信息增益率通过除以特征的信息熵来惩罚大值特征,而基尼系数则基于样本不纯度的度量,更适合处理连续或非均衡的数据。
Bagging(Bootstrap Aggregating)是一种集成学习方法,通过从原始数据集中抽样生成多个子集,然后训练多个决策树,最后将这些树的预测结果综合起来,以提高模型的稳定性和准确性。随机森林是Bagging的一个变种,它在每个节点选择特征时引入了随机性,进一步减少了过拟合的风险。
提升方法,如Adaboost和GDBT(Gradient Boosting Decision Tree),是另一种集成学习策略。Adaboost逐次迭代地训练弱分类器,每次迭代中重视前一轮被错误分类的样本,从而使得后续的弱分类器专注于改进之前的错误。GDBT则通过最小化残差或梯度来构建一系列决策树,每棵树的目标是修正前一棵树的预测误差,最终形成一个强大的预测模型。
总结来说,这个文档涵盖了决策树学习的基础理论,包括信息熵和互信息等基本概念,以及如何选择最优特征进行划分,同时扩展到了集成学习方法如随机森林和Adaboost,这些都是机器学习中不可或缺的重要组成部分。
11/51
关于Gini系数的讨论
julyedu.com
4 月机器学习算法班
考察Gini系数的图像、熵、分类误差率三者
之间的关系
将f(x)=-lnx在x=1处一阶展开,忽略高阶无穷小
,得到f(x)≈1-x


剩余60页未读,继续阅读
591 浏览量
113 浏览量
1293 浏览量
381 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

rblmmm
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Drools 4.0中文手册:重大更新与新特性概览
- C++实现的职工工资管理系统设计
- VHDL实现:电子密码锁设计与电路解析
- C#完全手册:从入门到精通
- Linux Shell:输入输出与重定向详解
- Linux高手之路:全面掌握必备技巧
- Word 2003域应用详览与快捷操作指南
- Unix Shell编程:文件名匹配与元字符应用
- Unix shell:后台执行与cron任务调度
- Unix shell深度解析:find与xargs的强大应用
- C#.NET图书管理系统详解
- DOS下C++学员管理系统源码实现
- Apache配置管理教程:红旗Linux下的实践
- 东软C方向笔试精华:选择题+编程+翻译详解
- 详解OSI七层网络结构:从物理到应用的全面解析
- Windows 2003+iis6环境下JSP Resin 2.1.16配置教程
