MySQL与Redis一致性实现策略详解
版权申诉
107 浏览量
更新于2024-08-05
收藏 701KB DOCX 举报
本文主要探讨如何实现 MySQL 和 Redis 之间的数据一致性问题,特别是在高并发场景下。首先,作者指出了一些不理想的解决方案:
1. **顺序写入问题**:
- **不建议的方案**:传统做法是先写 MySQL 再写 Redis,如果 MySQL 更新操作较慢,可能会导致 Redis 数据与 MySQL 数据不一致。例如,请求 A 先写 MySQL(10->11),然后请求 B 写入(同样10->11),若请求 A 在 Redis 上卡住,请求 B 可能已写入新的数据,造成数据冲突。
2. **另一个不建议的方案**:相反,先写 Redis 后写 MySQL,虽然避免了更新顺序问题,但如果Redis写入后 MySQL 更新失败,仍然可能导致数据不一致。
3. **部分情况下可行的方案**:先删除 Redis 再写 MySQL,然后立即删除Redis(缓存双删)。但这种方法存在风险,如删除操作耗时导致一致性问题,以及低效的等待策略(如延迟500ms)。
为了解决这些问题,作者提出了更好的一致性控制方法:
4. **推荐的异步串行化删除方案**:
- **双删操作优化**:通过将删除请求异步放入队列,确保删除操作按照顺序执行,避免了并发时的不确定性。这样可以保证 Redis 数据在 MySQL 更新后被正确地删除,提高了数据一致性。
5. **应对失败的策略**:当双删操作可能失败时,推荐使用重试机制,利用消息队列的特性进行自动重试,而非依赖于Redis的过期时间,以提高系统的鲁棒性。
本文重点关注了在高并发环境中如何通过合理的逻辑设计和系统架构优化,如异步操作和错误处理机制,来确保 MySQL 和 Redis 数据的一致性,减少潜在的不一致性和数据丢失风险。对于开发者来说,理解和实施这些策略是提高系统稳定性和性能的关键。
同“先写 MySQL,再写 Redis”,看图可秒懂。
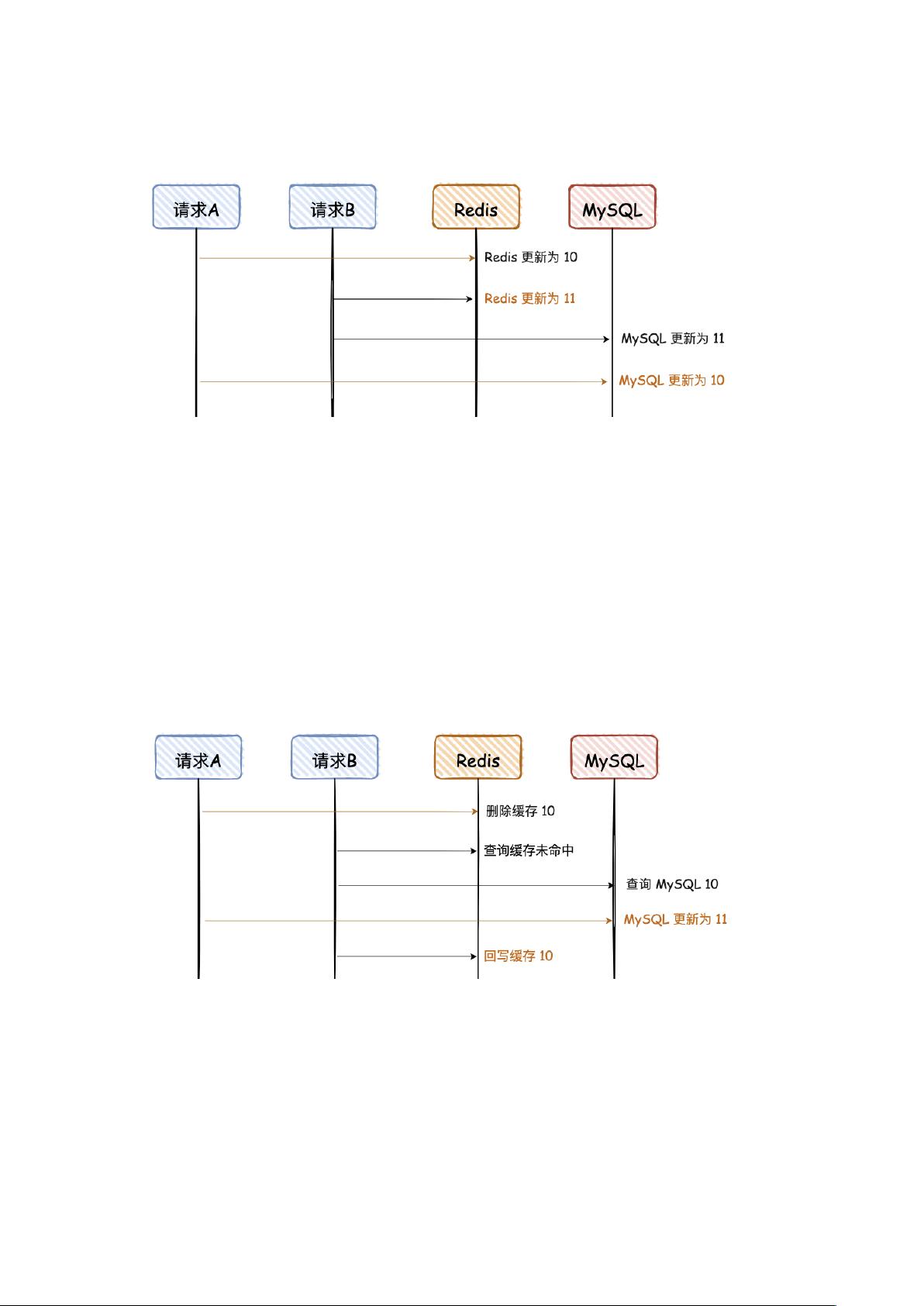
3. 先删除 Redis,再写 MySQL
这幅图和上面有些不一样,前面的请求 A 和 B 都是更新请求,这里的请求 A 是更新
请求,但是请求 B 是读请求,且请求 B 的读请求会回写 Redis。
请求 A 先删除缓存,可能因为卡顿,数据一直没有更新到 MySQL,导致两者数
据不一致。
剩余11页未读,继续阅读
点击了解资源详情
838 浏览量
485 浏览量
2023-09-05 上传
155 浏览量
103 浏览量
108 浏览量
2022-03-02 上传
2024-03-13 上传

HappyGirl快乐女孩
- 粉丝: 1w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 虚拟存储:技术演进与企业IT系统革新
- PowerDesigner数据库建模实用指南
- Oracle9i RMAN全面指南:备份、恢复与管理详解
- 从SOAP到Web服务:Visual Basic 6.0与.NET的转型指南
- MyEclipse 6 Java EE 开发中文手册-刘长炯
- Visual C++ MFC 入门教程:探索面向对象的Windows应用开发
- 快速配置Solaris 10的Samba服务:详解步骤与必备文件
- C语言指针完全解析
- Seam 2.0:简化Web开发的革命性框架
- Eclipse中配置与使用JUnit详细教程
- 新手指南:ACL配置实验与访问控制详解
- VLAN选择实验总结:考点解析与常见问题
- ModelSim详细使用教程及设计流程解析
- Windows 2003 DNS服务器备份与恢复指南
- RTXServer应用开发详解:VB实现短信平台模拟网关
- Windows Hook技术:拦截与控制
