分布式文件系统详解:优缺点与发展趋势
需积分: 9 180 浏览量
更新于2024-07-23
收藏 1.85MB PDF 举报
"分布式文件系统(Distributed FileSystem, DFS)是一种超越本地存储局限,通过网络将存储资源连接在多个节点上的文件系统。随着互联网的发展,本地文件系统无法满足大规模数据存取的需求,分布式文件系统应运而生。传统的分布式文件系统如NFS采用带内模式,数据和元数据集中于单一服务器,导致性能瓶颈。为了克服这些问题,新型DFS引入了存储区域网络(SAN)技术,使应用服务器能直接连接存储设备,提高数据传输效率并减少延迟。元数据处理则由元数据服务器负责,降低了系统瓶颈。"
分布式文件系统是现代大数据处理和云计算基础设施的核心组成部分,它们能够处理和存储海量数据,支持高并发访问,具备容错和扩展性。DFS的基本思想是将大文件分割成小块,分布在不同的服务器节点上,这样可以同时在多个节点上进行读写操作,提升整体性能。
DFS的关键特性包括:
1. **分布式存储**:文件被分割成多个数据块,分散存储在网络中的不同节点上,提高数据的可用性和容错性。
2. **冗余存储**:通过复制数据块,实现数据备份,防止单点故障导致的数据丢失。
3. **元数据管理**:元数据服务器负责文件的路径信息、权限控制等,确保数据的正确访问。
4. **负载均衡**:通过智能调度策略,将数据读写请求分发到合适的节点,避免节点过载。
5. **扩展性**:随着硬件资源的增加,DFS能够线性扩展其存储和处理能力。
6. **容错性**:即使部分节点失效,系统仍能正常运行,保证服务连续性。
DFS的典型代表有Google的GFS(Google File System)、Hadoop的HDFS(Hadoop Distributed File System)以及Amazon的S3(Simple Storage Service)。这些系统在设计时都考虑到了大规模数据处理的需求,比如GFS和HDFS支持大规模数据的批处理,S3则更侧重于云存储服务。
在实际应用中,DFS广泛应用于大数据分析、云计算平台、流媒体服务、社交网络和搜索引擎等领域。例如,Hadoop HDFS被许多公司用于处理和分析日志数据,发现用户行为模式。同时,DFS也是机器学习和人工智能算法的基础,因为它能高效地存储和处理大量训练数据。
然而,分布式文件系统也存在挑战,如数据一致性、网络延迟、安全性及复杂性等问题。为了解决这些问题,研究人员和工程师不断优化DFS的设计,引入诸如RAID(Redundant Array of Independent Disks)技术、多版本控制、安全认证和加密等机制。
分布式文件系统是应对大数据时代挑战的关键技术,它通过分布式的架构和智能的管理策略,实现了高效、可靠的数据存储和访问。随着技术的持续发展,DFS将在未来的数据密集型应用中扮演更加重要的角色。
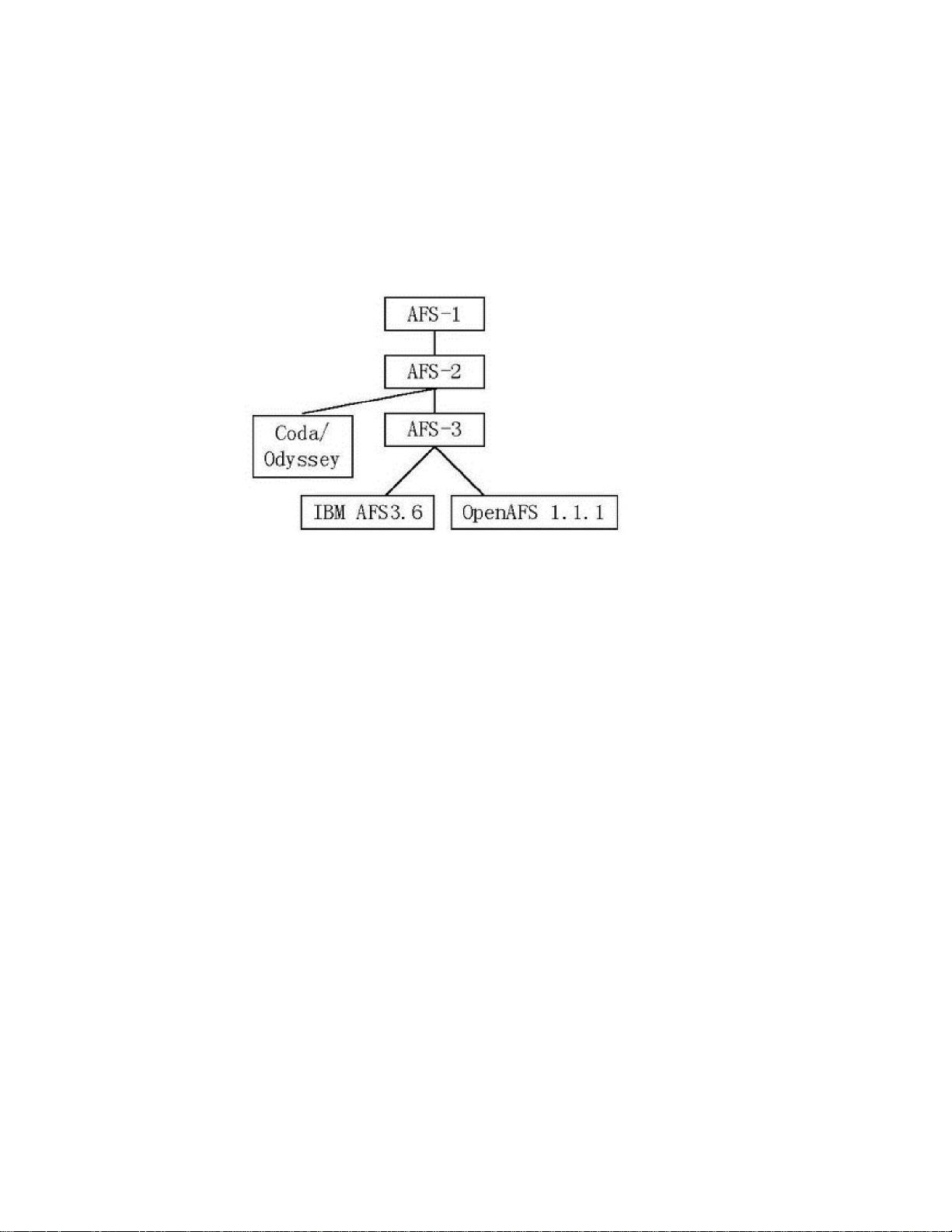
到 Transarc公司,AFS演变为 OSF的分布式计算环境(DCE)的分布式系统(DFS)组成
部分。1998 年 IBM 收购了 Transarc,并使 AFS 成为一个开放源码产品,叫做
OpenAFS。同时, OpenAFS 衍生了其他的分布式文件系统,如 Coda 和 Arla。其版本
发展如下图所示:
AFS的版本演化
基本概念
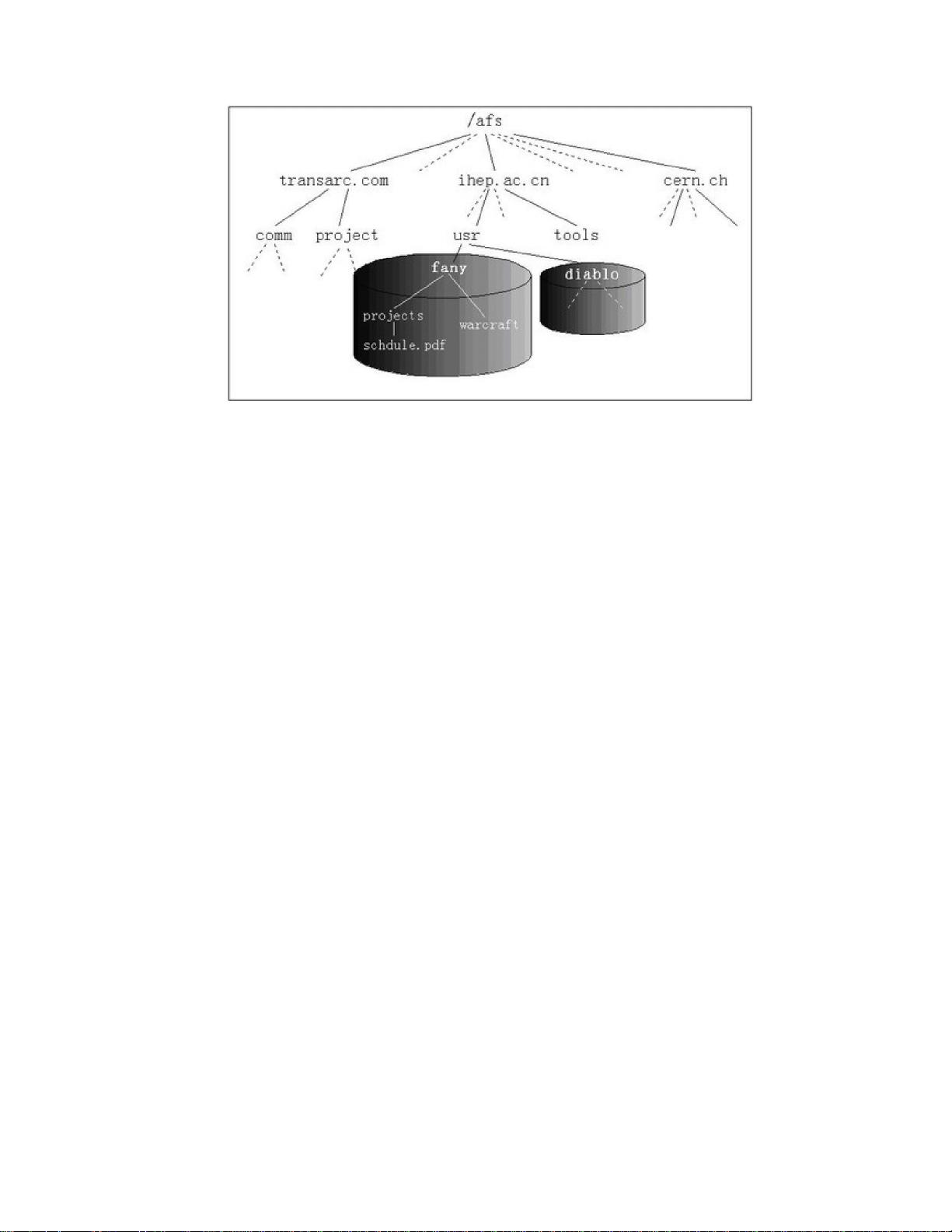
AFS是专门为在大型分布式环境中提供可靠的文件服务而设计的。AFS扩展性好,能
够扩展到几千个节点,提供一个统一的位置无关的名字空间。AFS规定了以"/afs/cellname"
为第一级目录的基本结构,使用户能够在任何地方都能够使用同一个目录地址对自已的文件
进行透明访问。
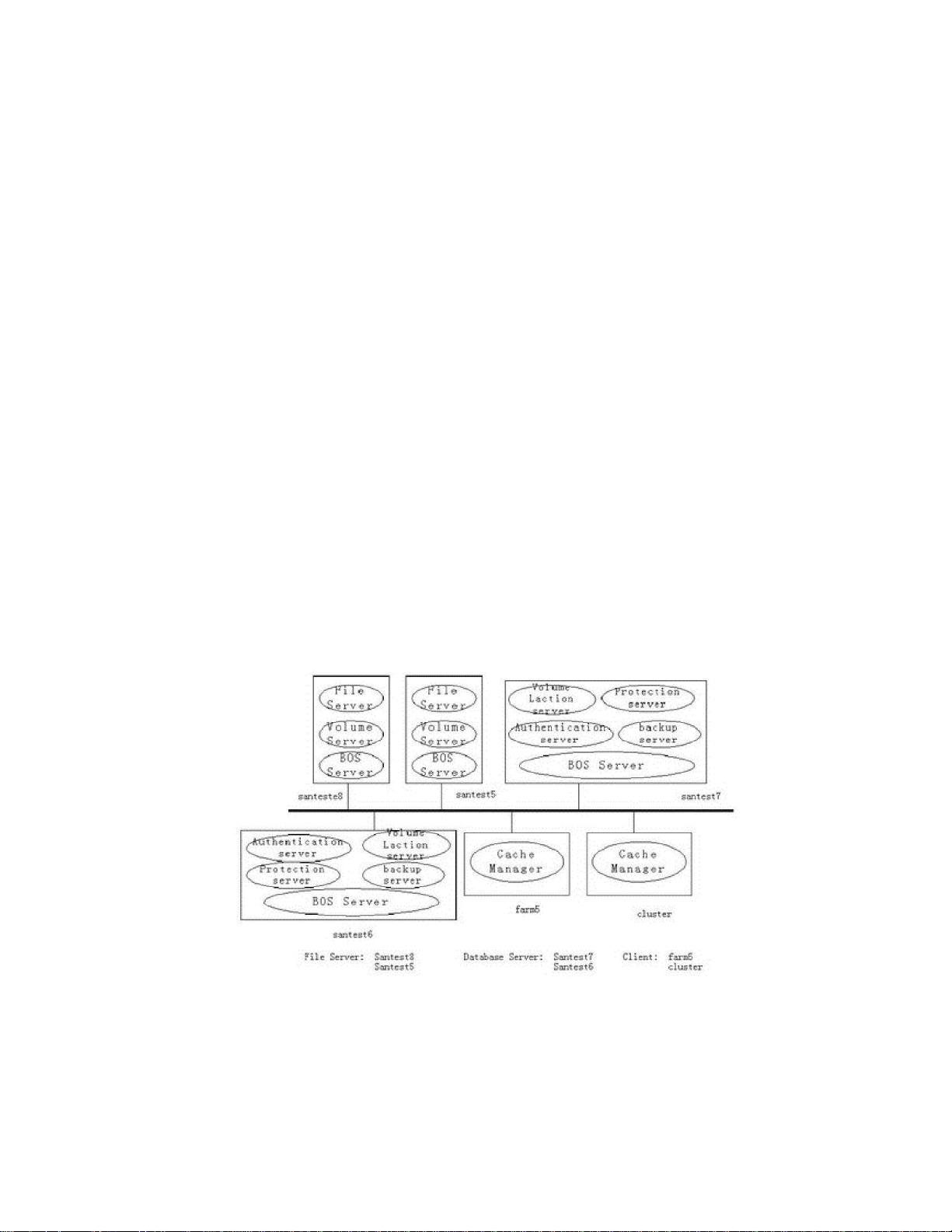
剩余62页未读,继续阅读
2015-03-16 上传
2011-02-11 上传
2021-09-30 上传
2021-08-10 上传
2021-08-09 上传
2021-08-08 上传
2021-05-12 上传
2022-03-05 上传
点击了解资源详情

strongtec
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | python-gitlab-0.14.tar.gz
- bmed-4460-6460:生物图像分析课程的源代码(BMED 44606460)
- rpgit-system:rpgit系统
- ListBox.zip源码Labview个人项目资料程序资源下载
- sympathetic-synth:交感合成器系统Mk1
- launch-extension-context-data-tools:提供操作和一些工具,使您可以使用contextData变量进行跟踪
- Look4:基于MVI,附近连接API和Hilt的约会应用
- TWB:TWB 网络应用程序
- fps沙箱
- Python库 | python-ftx-0.1.0.tar.gz
- GenGen:通用的世代系统
- 感言
- lunchlady:一个基于NodeJS的愚蠢,简单的无后端CMS
- 资源fastjson-get-post.zip
- sssnap-api:已弃用 - 用于 sssnap 的 REST JSON API
- Excel模板开票申请单模板.zip
