Hadoop入门与实战:从部署到理解
需积分: 10 15 浏览量
更新于2024-07-23
收藏 859KB PDF 举报
"Hadoop入门实战手册"
Hadoop是一种开源的分布式计算框架,由Apache基金会开发,主要用于处理和存储海量数据。这个笔记将带你逐步了解Hadoop的核心概念、部署方式以及实际操作。
### 1. 概述
1.1 **什么是Hadoop?**
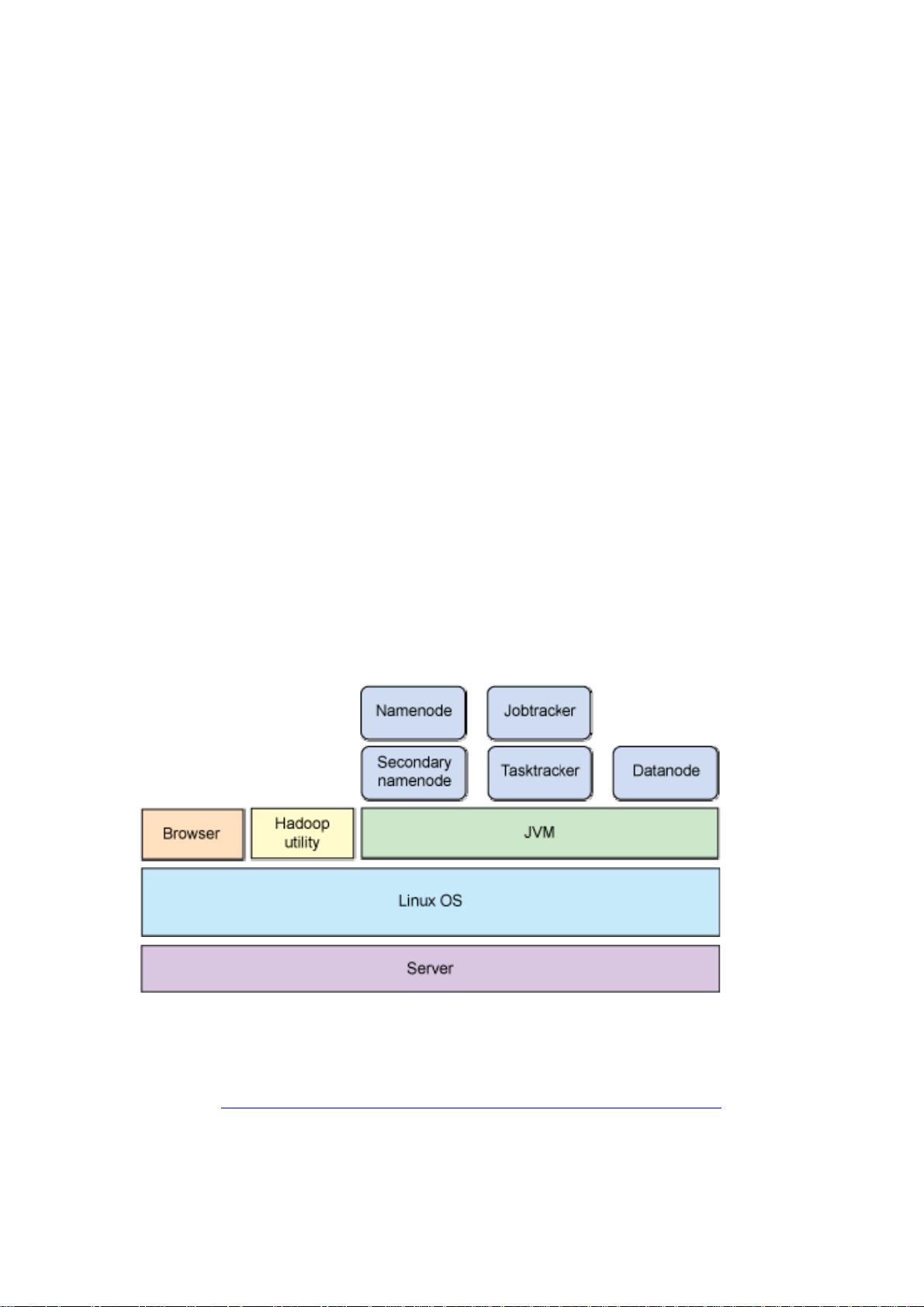
Hadoop是一个基于Java的开源框架,它允许在大规模集群中对数据进行分布式存储和处理。Hadoop的核心组件包括Hadoop Distributed File System (HDFS)和MapReduce,它们共同提供了高容错性和可扩展性,使得处理PB级别的数据变得可能。
1.2 **为什么要选择Hadoop?**
1.2.1 **系统特点**
- 分布式:Hadoop能够将大任务分解成小任务,分配到多台机器上并行处理,提高效率。
- 扩展性:通过添加更多节点,Hadoop集群可以轻松地扩展处理能力。
- 高容错性:数据在多个节点间备份,即使部分节点故障,系统仍能正常运行。
- 成本效益:利用普通硬件构建大规模集群,降低了硬件成本。
1.2.2 **使用场景**
- 大数据处理:如日志分析、推荐系统、社交媒体分析等。
- 数据挖掘:通过分布式算法进行模式识别和预测。
- 实时分析:结合流处理工具,如Apache Storm或Spark Streaming,实现快速响应的数据分析。
### 2. 术语
在学习Hadoop之前,了解以下基本术语很重要:
- **NameNode**: HDFS中的主节点,负责元数据管理。
- **DataNode**: 存储数据的节点,执行数据块的读写操作。
- **MapReduce**: Hadoop的并行计算模型,包含Map阶段和Reduce阶段。
- **JobTracker**: MapReduce作业的调度和监控中心(在Hadoop 2.x版本中被YARN替代)。
- **TaskTracker**: 运行Map和Reduce任务的工作节点(在Hadoop 2.x版本中被NodeManager替代)。
### 3. Hadoop的单机部署
单机部署是学习和测试Hadoop的起点,通常分为单机模式和伪分布式模式。
3.1 **目的**
- 了解Hadoop的基本操作。
- 测试和调试应用程序。
3.2 **先决条件**
- **支持平台**:Hadoop可在多种操作系统上运行,包括Linux、Unix和Windows。
- **所需软件**:Java环境(JDK 1.8或更高版本)、SSH客户端。
- **安装软件**:解压Hadoop二进制包,并配置环境变量。
3.3 **下载**:从Apache官方网站获取最新稳定版本的Hadoop。
3.4 **运行前的准备**:配置Hadoop的配置文件,如`core-site.xml`, `hdfs-site.xml`, `mapred-site.xml`。
3.5 **单机模式**:启动NameNode和DataNode在同一台机器上,适合初学者。
3.6 **伪分布式模式**:模拟分布式环境,每个Hadoop进程在一个单独的Java进程中运行,提供更接近生产环境的体验。
### 4. Hadoop集群搭建
4.x章节详细介绍了集群搭建的过程,包括SSH无密码登录配置、软件安装、各节点配置、集群启动和测试。
### 5. 架构分析
5.x章节深入探讨了Hadoop的两大核心组件:
5.1 **HDFS**:
- **角色**:NameNode、DataNode和Secondary NameNode。
- **特点**:数据复制、块级存储、高度容错。
5.2 **MapReduce**:
- **算法介绍**:将大任务拆分成Map任务和Reduce任务,分别在各个节点上并行处理。
- **Hadoop框架下的MapReduce**:JobTracker(或YARN)负责任务调度,TaskTracker(或NodeManager)执行任务。
5.3 **综合架构分析**:Hadoop生态系统还包括其他组件,如HBase、Hive、Pig等,它们共同构成了大数据处理的完整解决方案。
### 6. 更多内容
该笔记可能还涵盖了更多关于Hadoop的高级主题,如YARN资源管理、Hadoop与其他大数据工具的集成、性能优化等。
通过这份笔记,读者可以全面掌握Hadoop的基本知识,为进一步深入学习和实践打下坚实基础。

3.6.2 免密码ssh设置
现在确认能否不输入口令就用ssh登录localhost:
$ ssh localhost
如果不输入口令就无法用ssh登陆localhost,执行下面的命令:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3.6.3 执行
首先使用 hadoop 命令对 Hadoop File System (HDFS) 进行格式化。
首先,请求 namenode 对 DFS 文件系统进行格式化。在安装过程中完成了这个步骤,但是了解是否需
要生成干净的文件系统是有用的。
[hadoop@TEST085 hadoop-0.20.203.0]$ bin/hadoop namenode –format
注:在确认请求之后,文件系统进行格式化并返回一些信息:
11/07/12 17:47:12 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = TEST085/202.102.110.206
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 0.20.203.0
STARTUP_MSG: build =
http://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20-security-203 -r
1099333; compiled by 'oom' on Wed May 4 07:57:50 PDT 2011
************************************************************/
11/07/12 17:47:12 INFO util.GSet: VM type = 32-bit
11/07/12 17:47:12 INFO util.GSet: 2% max memory = 19.33375 MB
11/07/12 17:47:12 INFO util.GSet: capacity = 2^22 = 4194304 entries
11/07/12 17:47:12 INFO util.GSet: recommended=4194304, actual=4194304
www.linuxidc.com
Linux公社(LinuxIDC.com) 是包括Ubuntu,Fedora,SUSE技术,最新IT资讯等Linux专业类网站。

剩余52页未读,继续阅读
2017-10-29 上传
2023-12-19 上传
2023-08-10 上传
2023-09-22 上传
2023-05-27 上传
2024-01-13 上传
2023-09-27 上传

muigh
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
