残差编解码器与通道自适应超声图像去噪新方法
版权申诉
162 浏览量
更新于2024-06-27
1
收藏 1.44MB DOCX 举报
"超声图像去噪是医学图像处理领域的一个关键问题,旨在消除图像中的噪声,提高图像质量和诊断准确性。传统的滤波方法如中值滤波和双边滤波虽然简单易行,但往往导致图像细节的损失,特别是在保留边缘和纹理信息方面表现不足。低秩张量近似方法虽然降低了计算复杂度,但可能无法完全捕捉图像的复杂结构。后处理技术虽然在斑点噪声抑制上有一定成效,但可能牺牲部分图像细节。
随着深度学习的发展,尤其是卷积神经网络(CNN)的应用,图像去噪技术有了显著进步。文献中提到的残差编码解码框架,通过跳跃连接保留原始输入信息,有效减少了训练难度,提高了图像恢复的质量。Chen等人利用浅层残差编解码模型在CT图像去噪中取得了突破,但这些方法并不直接适用于超声图像,因为超声图像的噪声特性更为复杂,具有空间变异性和组织依赖性。
为此,本文提出了一个创新的去噪模型——基于残差编解码器的通道自适应去噪模型(Residual Encoder-decoder with Squeeze-and-Excitation Network, RED-SENet)。这个模型结合了残差学习的思想,确保编码器能够捕获图像的主要信息并去除噪声,同时解码器部分引入了注意力机制。这里的注意力机制,即squeeze-and-excitation network(SENet),能够对特征通道之间的相互依赖进行建模,动态调整不同通道的重要性,从而更精确地聚焦于图像的关键信息,增强超声图像的特征表达。
在超声图像中,噪声通常与有用信号混杂在一起,使得去噪任务成为一个非稳定问题。RED-SENet通过通道自适应机制,能够更好地识别并分离噪声,保持图像的组织结构和纹理细节。此外,模型的训练和优化过程也是针对超声图像的特性进行定制的,以适应其独特的噪声模式和空间变化。
本文提出的RED-SENet模型通过深度学习的残差结构和注意力机制,提供了一种针对超声图像噪声特性的高效解决方案,旨在提升图像的清晰度,支持医生做出更准确的诊断。这一方法不仅在理论上具有创新性,而且在实际应用中有望改善医疗成像的质量,对超声诊断技术的进步具有积极的推动作用。"
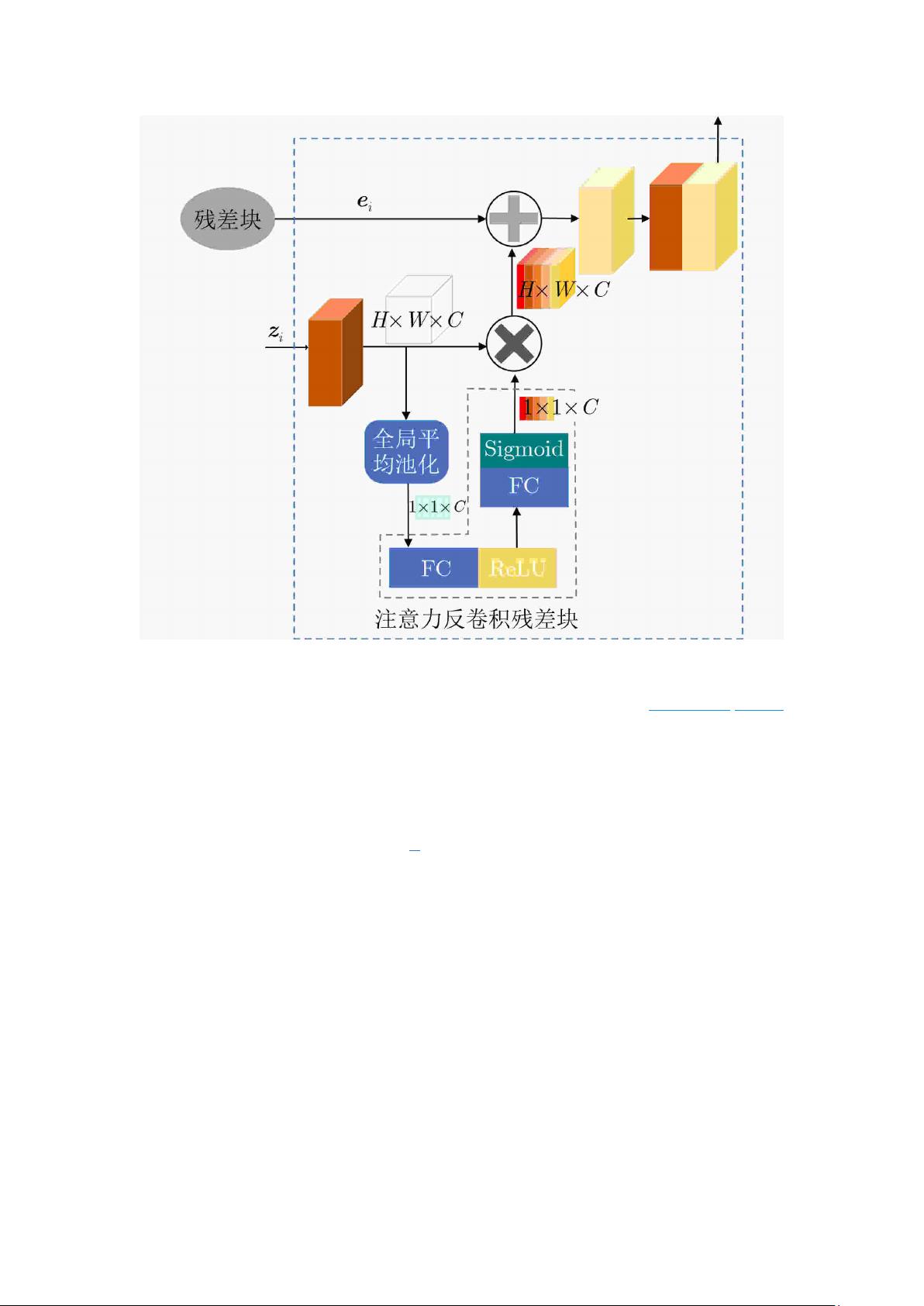
图 2 注意力反卷积残差(ADR)块
下载: 全尺寸图片 幻灯片
2.2.3 注意力解码器
本文方法中的注意力解码器用于增强有用信息的敏感度,更有针对性地恢复图像结构
的细节,卷积操作有噪声过滤的作用,但仍会减少输入信号的细节信息。因此,将 2 个
ADR 块和 1 个反卷积层整合到网络中
[10]
可以增强解码器恢复结构细节和保持纹理信息的能
力。通过卷积层和 ADR 块的跳跃连接残差数据遵循“先进后出”原则,即输入图像跳跃连接
到对应的最后一个反卷积层,第 2 个卷积层跳跃连接到对应的倒数第 1 个 ADR 块。注意
力解码器是由 ADR 块、反卷积层和 ReLU 单元组成的。ADR 块描述如下:
在 ADR 块中,首先,经过第 1 个反卷积运算后输出的 C 个通道特征图的计算为
$$ {{\boldsymbol{z}}_1} = {\boldsymbol{{w}}_0}^\prime \odot {{\boldsymbol{z}}_0} + {b_0}^\prime $$
(6)
其中,$ {b_0}^\prime $和${{\boldsymbol{w}}_0}^\prime$分别为反卷积中的偏差和反
卷积核,$ \odot $为反卷积运算$ {{\boldsymbol{z}}_0} $是第 5 个卷积重建后的特征向量。
$ {{\boldsymbol{z}}_1} $经过全局平均池化层得到长度为 C 的特征向量
${\boldsymbol{V}}$
剩余20页未读,继续阅读
2010-10-25 上传
2022-05-31 上传
2023-02-23 上传
2023-02-23 上传
2021-09-25 上传
2021-08-18 上传
2021-09-25 上传

罗伯特之技术屋
- 粉丝: 4501
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







