Seaborn高级教程:数据可视化分析
版权申诉
82 浏览量
更新于2024-07-08
收藏 1021KB PDF 举报
seaborn库是Python数据分析和可视化的一个重要工具,它提供了高级接口来创建美观且具有洞察力的统计图形。在机器学习领域,数据可视化是至关重要的一步,它可以帮助我们理解数据的特性和分布,从而做出更好的分析决策。seaborn库在matplotlib的基础上提供了更丰富的图表类型和更易用的接口。
在资源摘要中的"6.机器学习-高级绘图工具seaborn-简单、快捷(csdn)——程序"中,主要讨论了如何使用seaborn进行数据分布的可视化,包括单变量和双变量的情况。
1. 单变量数据分布可视化:
- **直方图**:seaborn的`distplot()`函数可以用来绘制直方图,它同时支持直方图、核密度估计(KDE)和rug plot。例如,`sns.distplot(arr, bins=10, hist=True, kde=True, rug=True)`。在这个例子中,`arr`是待分析的一维数据,`bins`定义了直方图的条形数,`hist`和`kde`分别表示是否绘制直方图和核密度曲线,`rug`表示是否在底部添加rug plot(小线条)来显示原始数据点。直方图可以直观展示数据的集中趋势和分布范围,而核密度估计则可以平滑数据,帮助我们识别潜在的连续分布。
2. **核密度估计(Kernel Density Estimation, KDE)**:KDE是一种非参数方法,用于估计数据的未知概率密度函数。在直方图中,选择合适的bin数量是关键,但KDE避免了这个问题,通过加权邻近数据点来估计分布,可以更准确地描绘数据的形状。
3. 双变量数据分布可视化:
- **联合分布图(Joint Plot)**:seaborn的`jointplot()`函数可以绘制双变量数据的分布,例如`sns.jointplot(x="x", y="y", data=df, kind="scatter", color="r")`。在这个例子中,`x`和`y`是DataFrame中对应的列名,`data`是包含这些列的DataFrame,`kind`指定了图形类型(这里选择了散点图)。`jointplot()`还可以绘制其他类型的图形,如核密度图('kde')、二维直方图('hex')等,以不同方式展示两个变量之间的关系。此外,`stat_func`可以指定统计函数来计算相关性,`color`用于设置颜色,`ratio`调整中心图与侧面图的比例,`space`控制它们之间的间距。
通过这些可视化工具,我们可以深入理解数据的特性,例如变量间的关联性、数据的集中程度以及异常值的存在。在机器学习中,这样的洞察对于特征工程、模型选择和结果解释都至关重要。使用seaborn,我们可以快速、高效地完成这些任务,使得数据分析过程更加直观和有效。

类别内的数据分布
箱形图(boxplot)
又称盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计
图,
能显示出一组数据的最大值、最小值、中位数、及上下四分位数
boxplot(x=None,y=None,hue=None,data=None,orient=None,color=None,stat
uration=0.75,width=0.8)
• palette:用于设置不同级别色相的颜色变量 “r”,“g”,“b”,“y”
• staturation:用于设置数据显示的颜色饱和度。 使用小数
sns.boxplot("day","total_bill",data=data,hue="time",palette=['g','r']
,saturation=0.9)
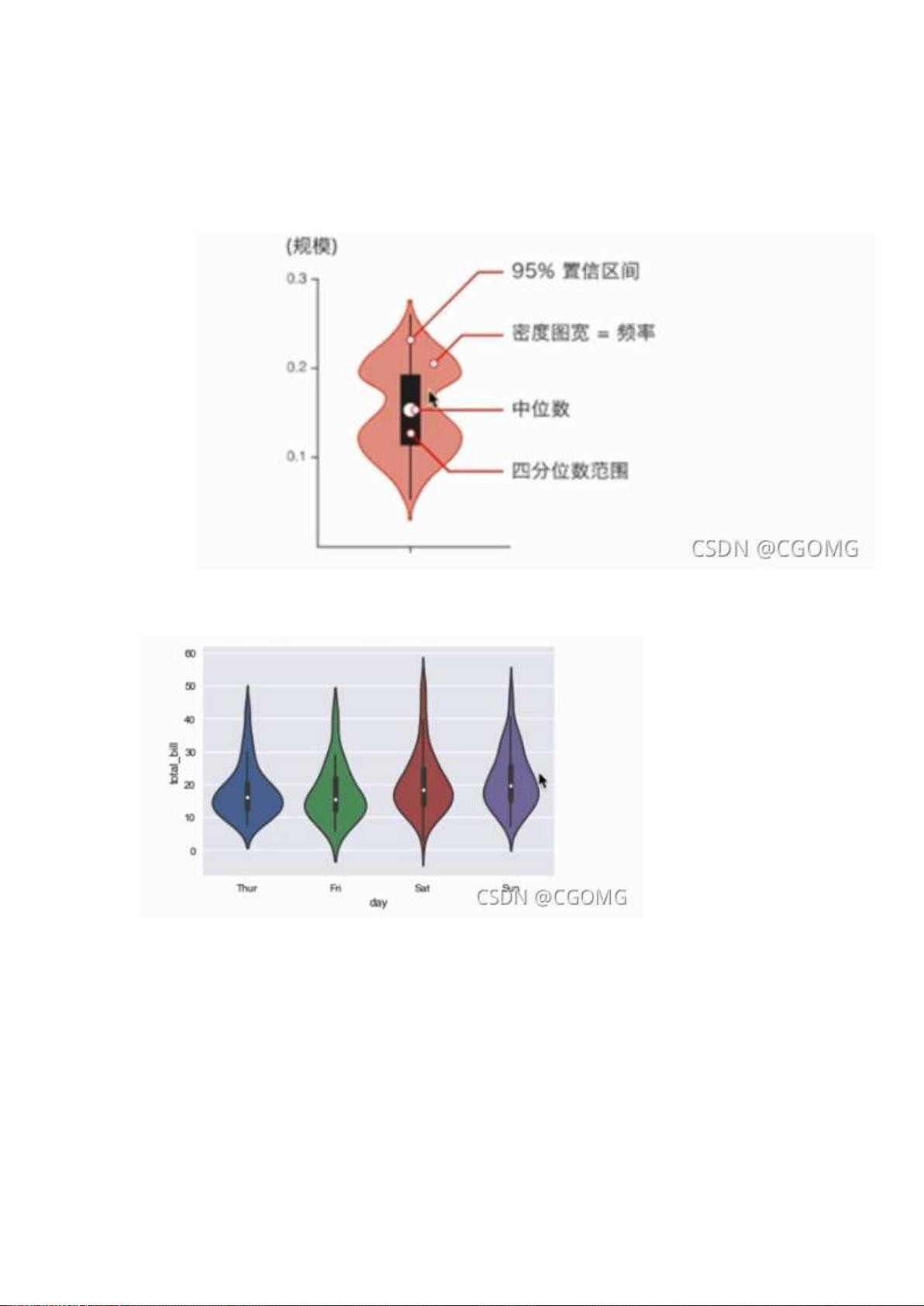
小提琴图(violin Plot):
• 用于显示数据分布及其概率密度
• 结合了箱形图和密度图的特征,主要用来显示数据的分布形状
剩余35页未读,继续阅读
2024-05-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

一诺网络技术
- 粉丝: 0
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- NetDocuments-crx插件
- 更丰富:TypeScript后端框架专注于开发效率,使用专用的反射库来帮助您愉快地创建健壮,安全和快速的API
- bianma.rar_Java编程_Java_
- 简单的editActionsForRowAt功能,写在SWIFTUI上-Swift开发
- 反弹:抛出异常时立即获取堆栈溢出结果的命令行工具
- zap-android:专注于用户体验和易用性的原生android闪电钱包:high_voltage:
- Doc:文献资料
- KobayashiFumiaki
- naapurivahti:赫尔辛基大学课程数据库应用程序项目
- Cura:在Uranium框架之上构建的3D打印机切片GUI
- SwiftUI中的倒计时影片混乱-Swift开发
- Example10.rar_串口编程_Visual_C++_
- GeraIFRelatorio:GeraIFRelatorio项目-自动化以帮助在Eclipse引擎上开发的Cobol语言项目编码
- CyberArk Identity Browser Extension-crx插件
- 智能汽车竞赛:完全模型组学习软件资源
- 键盘:在Windows和Linux上挂钩并模拟全局键盘事件
