无监督学习:探索数据中的隐藏模式
需积分: 10 126 浏览量
更新于2024-07-17
收藏 1.78MB PDF 举报
"无监督学习模式检测 - 通过Dammnn探讨如何在没有标签的数据中发现模式"
无监督学习模式检测是一种机器学习方法,它在没有预先标记的训练数据的情况下构建模型。这种方法的关键在于,它允许算法从数据本身中学习结构和潜在的模式,而无需依赖人为指定的目标变量。Dammnn的这篇文章深入浅出地介绍了这一概念。
在有监督学习中,我们通常拥有带有标签的训练数据,算法可以通过这些标签学习如何对新数据进行分类或预测。然而,在现实世界中,获取大量带标签的数据可能非常困难或者成本高昂。此时,无监督学习就显得尤为重要,因为它能够处理未标记的数据,并帮助我们从中发现隐藏的模式或结构。
无监督学习算法主要致力于在给定的数据集中寻找相似性的子组,这一过程称为聚类。它们利用某种相似性度量(如欧氏距离、余弦相似性等)来确定数据点之间的关系,进而将数据分为不同的类别。例如,在市场细分中,无监督学习可以找出具有相似购买行为的消费者群体;在自然语言处理中,它可以识别文档的主题;在计算机视觉领域,它能检测图像中的特征或对象。
在无监督学习中,学习问题的设定通常是这样的:当我们有一组无标签数据时,我们假设数据是由一些潜在的变量生成的,这些变量以某种方式影响了数据的分布。学习过程就是去揭示这些隐藏的变量或结构,从而理解和解释数据的内在规律。常用的技术包括聚类算法(如K-means、DBSCAN)、降维技术(如主成分分析PCA、t-SNE)以及自编码器等。
无监督学习的一个挑战是评估模型的性能,因为没有明确的标签作为基准。常见的评估方法包括可视化聚类结果、使用外部信息验证聚类质量,或者使用一些度量标准(如轮廓系数)来量化聚类的紧密性和分离性。
无监督学习模式检测是数据科学中不可或缺的一部分,它提供了探索和理解大规模无标签数据的强大工具。通过Dammnn的文章,读者可以更深入地了解如何在实际问题中应用无监督学习,以及如何从无标签数据中提取有价值的信息。

Overlay input data points on top of these coloured regions:
# Overlay input points
plt.scatter(X[:,0], X[:,1], marker='o',
facecolors='none',
edgecolors='black', s=80)
Plot the centres of the clusters obtained using the K-Means
algorithm:
# Plot the centers of clusters
cluster_centers = kmeans.cluster_centers_
plt.scatter(cluster_centers[:,0],
cluster_centers[:,1],
marker='o', s=210, linewidths=4,
color='black',
zorder=12, facecolors='black')
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
plt.title('Boundaries of clusters')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
The full code is given in the kmeans.py file. If you run the code, you
will see two screenshots. The first screenshot is the input data:
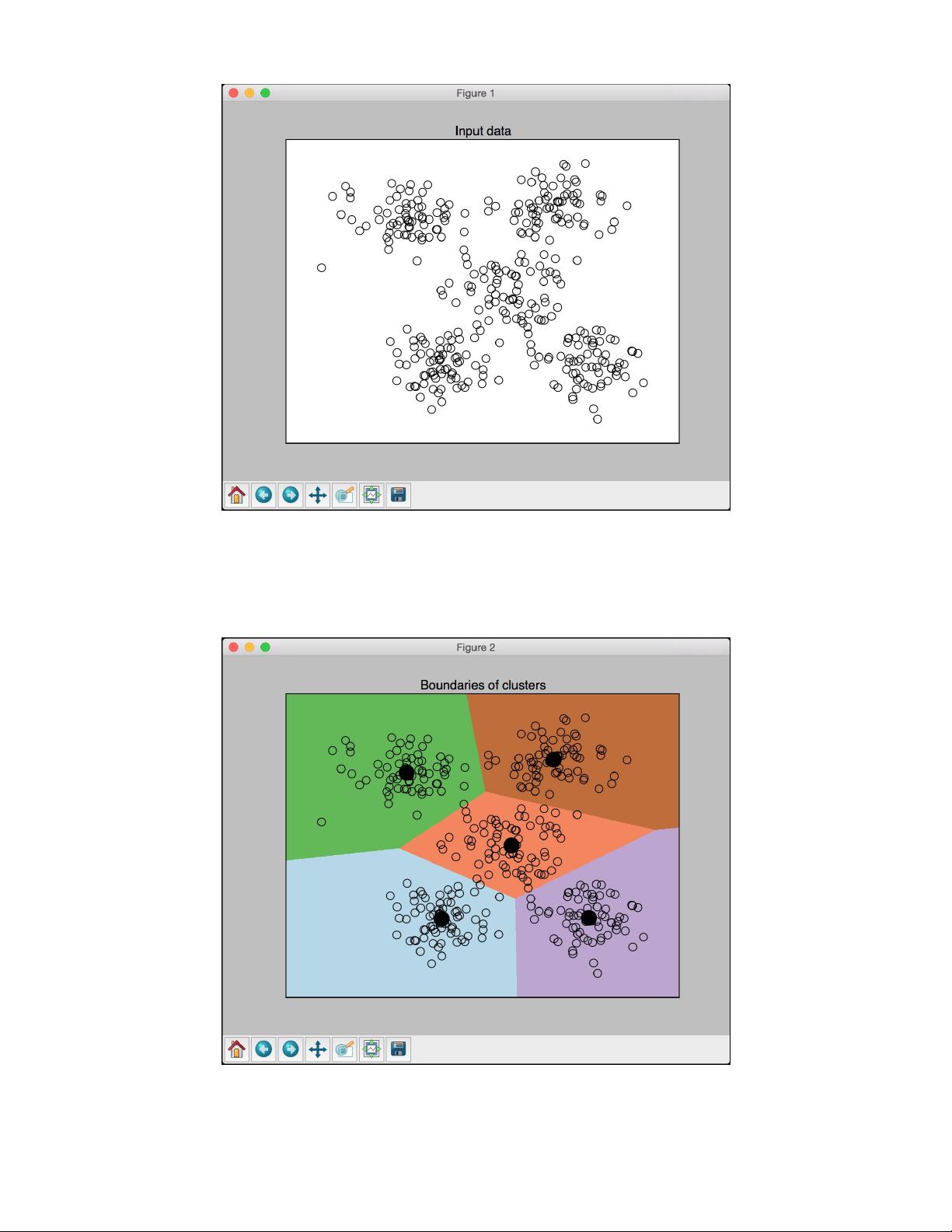
剩余30页未读,继续阅读
1239 浏览量
2021-02-05 上传
2587 浏览量
2022-12-01 上传
2024-09-22 上传
276 浏览量
123 浏览量
点击了解资源详情
196 浏览量

tox33
- 粉丝: 64
- 资源: 304
 我的内容管理
展开
我的内容管理
展开







最新资源
- p3270:一个用于控制远程IBM主机的python库
- magic-iswbm-com-zh-latest.zip
- deeplearning-js:JavaScript中的深度学习框架
- 易语言控制台时钟源码.zip
- 完整的AXURE原型系列1-6季的全部作品rp源文件
- RC4-Cipher:CSharp中的RC4算法
- 测试
- 威客互动主机管理系统 v1.3.0.5
- metrics-js:一个向Graphite等聚合器提供数据点信息(度量和时间序列)的报告框架
- Kubernetes的声明式连续部署。-Golang开发
- IsEarthStillWarming.com::fire:全球变暖信息和数据
- Ajedrez-开源
- 社区:Rust社区的临时在线聚会。 欢迎所有人! :globe_showing_Americas::rainbow::victory_hand:
- Algo-ScriptML:Scratch的机器学习算法脚本。 机器学习模型和算法的实现只使用NumPy,重点是可访问性。 旨在涵盖从基础到高级的所有内容
- 支持Google的协议缓冲区-Golang开发
- 手写体数字识别界面程序.rar_图片数字识别_手写数字识别_手写识别_模糊识别_识别图片数字
