"使用flink将数据从kafka导入mysql的详细教程及maven依赖配置"
版权申诉
78 浏览量
更新于2024-04-05
收藏 373KB PDF 举报
本文主要介绍了如何将 Apache Flink 与 Kafka 以及 MySQL 结合使用,实现数据流的处理和存储。首先需要在 Maven 项目中添加相关依赖,如 org.springframework.kafka 和 org.apache.flink 的相应版本。接着介绍了如何使用 Flink 的 Kafka Connector 来连接 Kafka,将 Kafka 中的数据流引入到 Flink 中进行处理。在 Flink 中可以对数据进行各种转换、过滤、聚合等操作,然后通过 Flink 的 MySQL Connector 将最终处理结果写入到 MySQL 数据库中。
整个流程主要分为以下几个步骤:首先要创建一个 Kafka 生产者,将数据发送到 Kafka Topic 中,然后通过 Flink 的 Kafka Consumer 消费 Kafka 中的数据。在 Flink 中可以定义一系列的数据处理操作,在处理完数据后,再通过 Flink 的 MySQL Sink 将处理结果写入到 MySQL 数据库表中。
在代码示例中,展示了如何配置 Flink 中的 Kafka Connector 和 MySQL Connector。对于 Kafka Connector,需要指定 Kafka 的连接地址、Topic 名称以及消费组等信息;对于 MySQL Connector,需要指定 MySQL 的连接信息、表名称以及字段映射等配置信息。此外,还介绍了如何设置并行度、检查点间隔等相关参数以及如何启动 Flink 作业来执行数据处理任务。
总的来说,通过本文的介绍,读者可以了解到如何利用 Apache Flink、Kafka 和 MySQL 这三个强大的工具来构建一个端到端的大数据处理和存储系统。这种架构可以应用在各种场景下,如实时数据分析、数据清洗、实时监控等领域,为企业提供更加高效和可靠的数据处理解决方案。希望本文能够帮助到读者,让大家更加熟悉和掌握这些流行的大数据处理技术,带来更多的应用和创新。
Connection con = null;
try {
con = dataSource.getConnection();
} catch (Exception e) {
System.out.println("msg:" + e.getMessage());
}
return con;
}
}
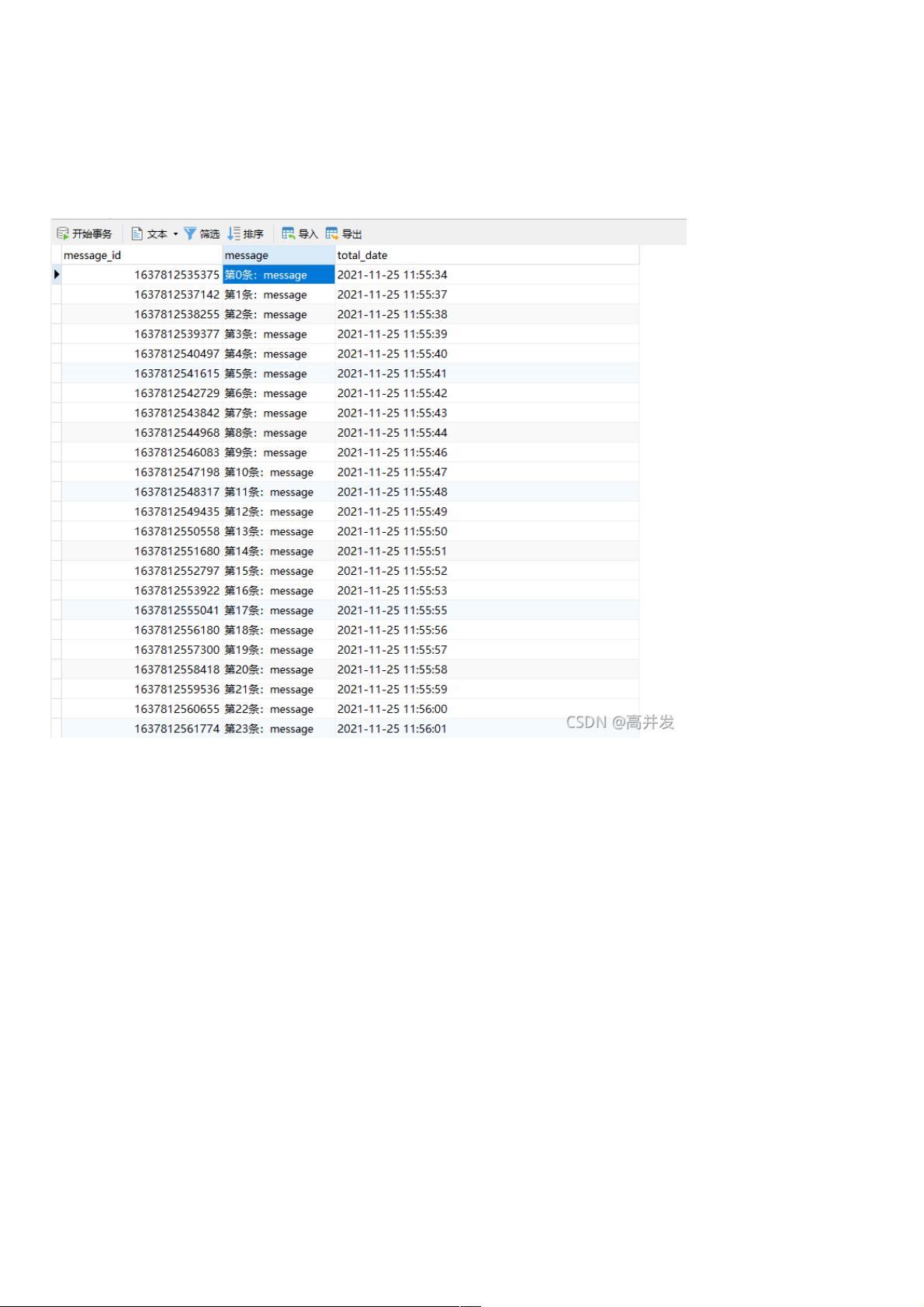
运行效果:
1 maven依赖依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.1.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
剩余15页未读,继续阅读
2023-04-23 上传
2024-01-04 上传
2023-08-01 上传
2021-12-27 上传
2024-04-11 上传
2023-06-14 上传
2023-06-14 上传

一诺网络技术
- 粉丝: 0
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- target-deep-learning:正在进行中的有关神经网络以进行图像异常检测的项目
- 易语言-置托盘图标和弹出托盘菜单程序
- 基于三菱PLC的煤质采样程序.rar
- FunAdmin V1.0 开源管理系统
- 自动CAR-Amit-
- describe-number:在Emacs中任意描述任意数量的数字
- simple_dashboard
- react-parallax:一个用于视差效果的React组件
- SaveVSUMLDiagramsToImageFile:针对Visual Studio 2013 Ultimate和Visual Studio 2015 Enterprise的MSDN“如何:将UML图导出到图像文件”的实现
- CS323-CollinEthanProject:Collin Umphrey和Ethan Monnin-CS323类项目
- 367DataScience
- qa-form-helper:用于 Web 表单 QA 的自动填充书签
- 马丁-福勒-分解第二
- LiteMap Toolbar-crx插件
- 经典三菱PLC带两伺服用于焊接机器程序.rar
- zipkin-rabbit-swagger
