信息安全领域实体共指消解技术的应用与挑战
版权申诉
77 浏览量
更新于2024-07-03
收藏 261KB DOCX 举报
"该文档研究了信息安全领域中的实体共指消解技术,这是自然语言处理的关键环节,对于提升机器翻译、情感分析、关系提取和摘要生成等任务的性能至关重要。尽管通用领域的研究较为丰富,但在信息安全领域,相关研究尚属空白。实体共指消解在该领域具有实际应用价值,例如能准确提取实体属性关系,增强知识图谱的完备性,进而提升威胁预警的精度。主要的共指消解技术包括基于规则、基于统计和基于深度学习三种方法,各有优缺点。"
在信息安全领域,实体共指消解技术是一种解决文本中实体重复引用问题的技术,对提高信息处理效率和准确性有着重要作用。自然语言处理是这一技术的基础,它涉及到多种NLP任务,如机器翻译,其目标是使计算机能够理解并生成人类语言;情感分析,用于识别和提取文本中的情绪色彩;关系提取,是从文本中抽取出实体之间的关系,如人物、地点和事件的关系;以及摘要自动生成,即自动生成文本的精简版。这些任务的性能提升都需要实体共指消解作为支撑。
当前,通用领域的实体共指消解研究已经积累了大量经验和数据,如ACE、CoNLL2012和Parcor等公开语料库提供了丰富的训练资源。然而,信息安全领域的相关研究还相对匮乏,这是一个有待探索的领域。以Stuxnet病毒为例,通过共指消解可以明确不同名称(如"Stuxnet"、"thevirus"、"thenewvirus"和"it")所指的同一实体,从而揭示实体间的“is-a”关系,这对构建和完善信息安全知识图谱,提升威胁预警能力具有实际意义。
实体共指消解的技术主要包括三个方面:一是基于规则的方法,依靠人工编写的规则进行消解,但覆盖范围有限,对复杂语言现象处理能力较弱;二是基于统计的方法,利用大量数据进行训练,通过概率模型来决定实体的共指关系,适应性较强,但可能因数据不足或噪声而影响效果;三是基于深度学习的方法,借助神经网络模型学习和理解上下文信息,表现出强大的表示学习能力和泛化能力,但需要大量的标注数据和计算资源。
未来的研究应着重于如何将这些技术应用于信息安全领域,解决该领域特有的挑战,如专业术语的丰富性、攻击模式的多样性以及数据的敏感性和隐私保护问题。同时,开发适应信息安全场景的特定模型和算法,以及建立相应的专门语料库,将是推动这一领域共指消解技术发展的关键。
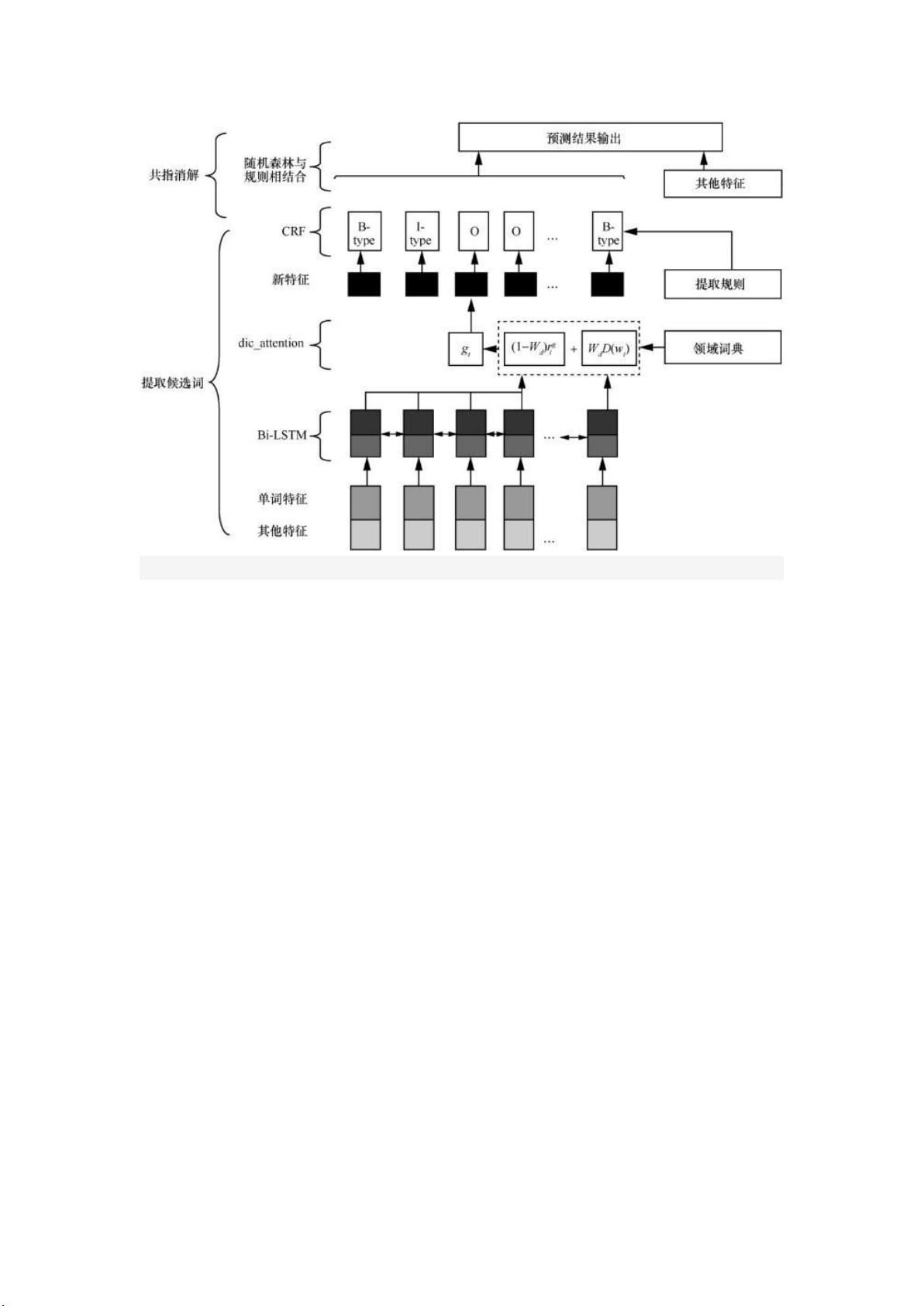
图 1方法框架
3.1.1 名词短语和嵌套短语的提取规则
通常情况下,名词短语是由名词以及它的修饰语组成,中心词为名词。名
词的修饰语与名词有 2 种位置关系:一是放在被修饰名词的前面,叫作前置定
语或定语;二是放在被修饰名词的后面,叫作后置定语。通过对信息安全领域
内语料的分析发现,需要进行共指消解的名词短语通常为前置定语名词短语,
因此这里只考虑第一种位置关系的情况。
一般来说,作为前置定语的词类有 2 种:其一是限定词,用来限定名词所
指范围,例如 these、three、a、the、my 等;其二是形容词,用来表示名词的
性质和特征,比如 red、close、new、small 等。因此,可以通过如下规则来获
取名词性短语。
假设 U
1
表示冠词集合,U
2
表示形容词性物主代词集合,U
3
表示名词性物主
代词集合,U
4
表示指示限定词集合,U
5
表示数量词集合, U
6
表示基数词集合,
N 表 示 名 词 集 合 , NP 表 示 名 词 短 语 集 合 , AD 表 示 形 容 词 集 合 , 集 合 U
=U
1
∪U
2
∪U?
3
∪U
4
∪U
5
∪U
6
。
1) 如果单词 a 属于冠词、形容词性物主代词、名词性物主代词、指示限定
词、数词、量词、基数词等集合中的任意一个单词,单词 b 属于名词集合,则
ab 构成名词性短语。
2) 如果单词 c 属于形容词,单词 b 属于名词集合,则 cb 构成名词短语。
3)acb 属于名词短语。
可表示为
(
∀a)(∀c)(∀b)(BEL(a,U)∧BEL(c,AD)∧(∀a)(∀c)(∀b)
(BEL(a,U)∧BEL(c,AD)∧
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-08-16 上传
2023-07-23 上传
2022-07-11 上传

罗伯特之技术屋
- 粉丝: 4495
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- OO Principles.doc
- Keil C51程序设计中几种精确延时方法.doc
- 基于单片机的智能遥控小汽车
- 利用asp.net Ajax和sqlserver2005实现电子邮件系统
- 校友会网站需求说明书
- Microsoft Windows Internals (原版PDF)
- 软件测试工具的简单介绍
- 2009年上半年软件评测师下午题
- 2009年上半年软件评测师上午题
- linux编程从入门到提高-国外经典教材
- 2009年上半年网络管理员下午题
- 2009年上半年系统集成项目管理师下午题
- 2009年上半年系统集成项目管理师上午题
- 数据库有关的中英文翻译
- 2009年上半年系统分析师下午题II
- 2009年上半年系统分析师上午题
