机器学习损失函数解析:MSE与MAE
需积分: 0 6 浏览量
更新于2024-08-05
收藏 1.23MB PDF 举报
"这篇内容主要介绍了机器学习中常用的损失函数,包括它们的概念、关系以及在不同问题中的适用性。"
在机器学习中,损失函数、代价函数和目标函数是优化过程中的核心概念。损失函数(Loss Function)是衡量单个样本预测结果与实际值差异的度量,它给出的是模型输出与真实值之间的偏差。代价函数(Cost Function)是所有样本损失的总和,用于评估整个训练集或小批量样本的性能。目标函数(Objective Function)是一个更为通用的术语,可以表示任何需要被优化的函数,它可能包括损失函数和其他正则化项。
本文主要讨论了几种常见的回归问题损失函数:
1. 均方差损失(MSE,Mean Squared Error):也称为L2 Loss,是最常见的回归问题损失函数。它的计算公式是预测值与真实值差的平方的平均值。MSE倾向于惩罚远离真实值的大误差,因为它是平方项,所以误差越大,损失增加的速度越快。当误差服从高斯分布时,最小化MSE损失函数等同于最大似然估计,使得它在回归问题中表现良好。但在分类问题中,由于误差不是离散的,MSE可能不是一个理想的损失函数。
2. 平均绝对误差损失(MAE,Mean Absolute Error):也被称作L1 Loss,是预测值与真实值之差的绝对值的平均。与MSE相比,MAE对异常值的敏感度较低,因为它不是平方项,所以即使存在大误差,损失也不会无限增加。这种特性使得MAE在处理噪声较大或有离群值的数据时更加稳健。
除了这些,还有其他类型的损失函数,如对数损失(Log Loss)、Huber损失、绝对百分比误差损失(MAPE)等,适用于不同的问题。例如,对数损失通常用于二分类或多分类问题,因为它与交叉熵损失相关,能够更好地捕捉概率预测的准确性。而Huber损失结合了MSE和MAE的优点,对于小误差近似于MSE,而对于大误差接近MAE,因此在噪声和异常值共存的数据中表现出较好的鲁棒性。
在实际应用中,选择合适的损失函数对模型的性能至关重要。不同的损失函数对应着不同的优化目标和数据特性,理解并正确选择损失函数是构建高效机器学习模型的关键步骤。在实践中,还可以根据问题的具体需求,通过调整损失函数的参数或设计自定义损失函数来进一步优化模型。
问
题
机
器
学
习
中
常
⽤
的
损
失
函
数
总
结
前
⾔
我
们
经
常
听
到
损
失
函
数
、
代
价
函
数
和
⽬
标
函
数
这
三
种
说
法
,
这
三
种
说
法
有
什
么
联
系
和
区
别
呢
?
这
⾥
明
确
下
:
损
失
函
数
Loss Function
通
常
是
针
对
单
个
训
练
样
本
⽽
⾔
的
,
给
定
⼀个
模
型
输
出
和
⼀个
真
实
值
,
损
失
函
数
输
出
⼀个
实
值
损
失
代
价
函
数
Cost Function
通
常
是
针
对
整
个
训
练
集
(
或
者
是
在
使
⽤
mini-batch gradient descent
时
的
⼀
个
mini -batch
)
的
总
损
失
⽬
标
函
数
Objective Function
是
⼀个
更
通
⽤
的
术
语
,
表
⽰
任
意
希
望
被
优
化
的
函
数
。
⼀
句
话
总
结
三
者
的
关
系
就
是
:
A loss function is a part of a cost function which is a type of an
objective function.
由
于
损
失
函
数
和
代
价
函
数
只
是
在
针
对
样
本
集
上
有
区
别
,
因
此
本
⽂
中
统
⼀
使
⽤
损
失
函
数
这
个
术
语
。
下
⾯
⾸
先
介
绍
⼏
种
适
⽤
于
回
归
问
题
的
损
失
函
数
均
⽅
差
损
失
(MSE)
Mean Squared Error (MSE
,
得
记
住
这
个
缩
写
,
很
多
地
⽅
都
直
接
⽤
缩
写
的
)
损
失
是
回
归
任
务
中
最
常
⽤
的
⼀
种
损
失
函
数
了
,
也
叫
L2 Loss
。
其
基
本
形
式
如
下
:
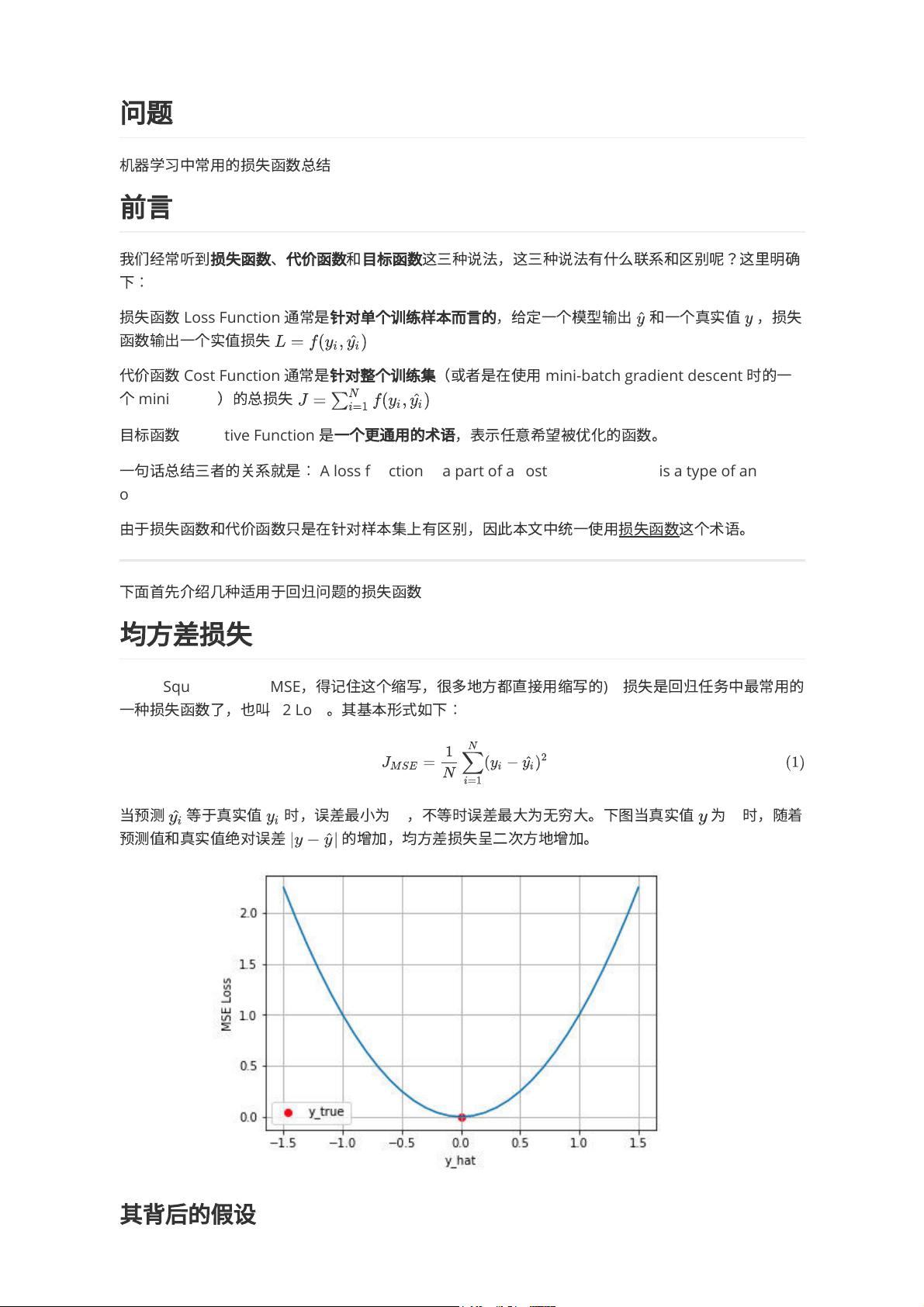
当
预
测
等
于
真
实
值
时
,
误
差
最
⼩
为
0
,
不
等
时
误
差
最
⼤
为
⽆
穷
⼤
。
下
图
当
真
实
值
为
0
时
,
随
着
预
测
值
和
真
实
值
绝
对
误
差
的
增
加
,
均
⽅
差
损
失
呈
⼆
次
⽅
地
增
加
。
其
背
后
的
假
设
下载后可阅读完整内容,剩余8页未读,立即下载
163 浏览量
426 浏览量
2023-07-28 上传
342 浏览量
135 浏览量
140 浏览量
228 浏览量
158 浏览量

坑货两只
- 粉丝: 1061
 我的内容管理
展开
我的内容管理
展开







最新资源
- Subclipse 1.8.2版:Eclipse IDE的Subversion插件下载
- Spring框架整合SpringMVC与Hibernate源码分享
- 掌握Excel编程与数据库连接的高级技巧
- Ubuntu实用脚本合集:提升系统管理效率
- RxJava封装OkHttp网络请求库的Android开发实践
- 《C语言精彩编程百例》:学习C语言必备的PDF书籍与源代码
- ASP MVC 3 实例:打造留言簿教程
- ENC28J60网络模块的spi接口编程及代码实现
- PHP实现搜索引擎技术详解
- 快速香草包装技术:速度更快的新突破
- Apk2Java V1.1: 全自动Android反编译及格式化工具
- Three.js基础与3D场景交互优化教程
- Windows7.0.29免安装Tomcat服务器快速部署指南
- NYPL表情符号机器人:基于Twitter的图像互动工具
- VB自动出题题库系统源码及多技术项目资源
- AndroidHttp网络开发工具包的使用与优势
