TensorFlow深度学习:图像修复的步骤与感知损失
171 浏览量
更新于2024-08-31
收藏 1.1MB PDF 举报
在TensorFlow中利用深度学习进行图像修复是一个实用且有趣的话题,特别是在处理如人脸图像修复这类任务时。本文基于Raymond Yeh和Chen Chen等人在2016年提出的"Semantic Image Inpainting with Perceptual and Contextual Losses"论文,展示了如何通过深度生成对抗网络(DCGAN)实现这一技术。该研究专注于利用深度学习模型结合感知信息和上下文损失,以生成自然、连贯的修复图像。
文章分为三个步骤来解释这一过程:
1. **图像解析成概率分布**:首先,将原始图像转换为概率分布中的样本点,这一步骤是通过深度学习模型捕捉图像的统计特性,以便于模型理解和生成。这涉及到了解图像数据的内在结构和模式,特别是环境信息(相邻像素的特征)和知觉信息(基于人类视觉习惯的预测)。
2. **伪造图像生成**:接下来,模型通过学习已有的训练数据,生成伪造图像。DCGANs在此过程中扮演关键角色,它们由生成器和判别器组成,生成器尝试创建逼真的图像以欺骗判别器,而判别器则试图区分真实图像和生成的图像。通过这样的对抗训练,模型学会了生成与输入图像背景相符的缺失区域的假象。
3. **寻找最佳修复图像**:最后,通过比较生成的伪造图像和原始图像,选择最符合上下文和知觉信息的图像作为修复结果。这一步依赖于损失函数,如感知损失和上下文损失,以确保修复后的图像在视觉上尽可能自然,同时保持与原图的连贯性。
文章强调了环境信息和知觉信息在图像修复中的重要性,因为它们帮助模型生成更符合现实的修复内容。尽管目前尚无通用的算法能够完美解决所有情况,但通过深度学习,我们已经取得了显著的进步,能够为设计师和摄影师提供强大的工具来处理图像中的缺失或不想要的部分。
总结起来,本文介绍了如何在TensorFlow中运用深度学习技术,通过概率分布、生成对抗网络以及损失函数,实现对图像进行内容自动填补、完善和修复的过程。这项技术不仅适用于人脸图像,也可扩展到其他类型的图像修复,展示了人工智能在图像处理领域的强大潜力。
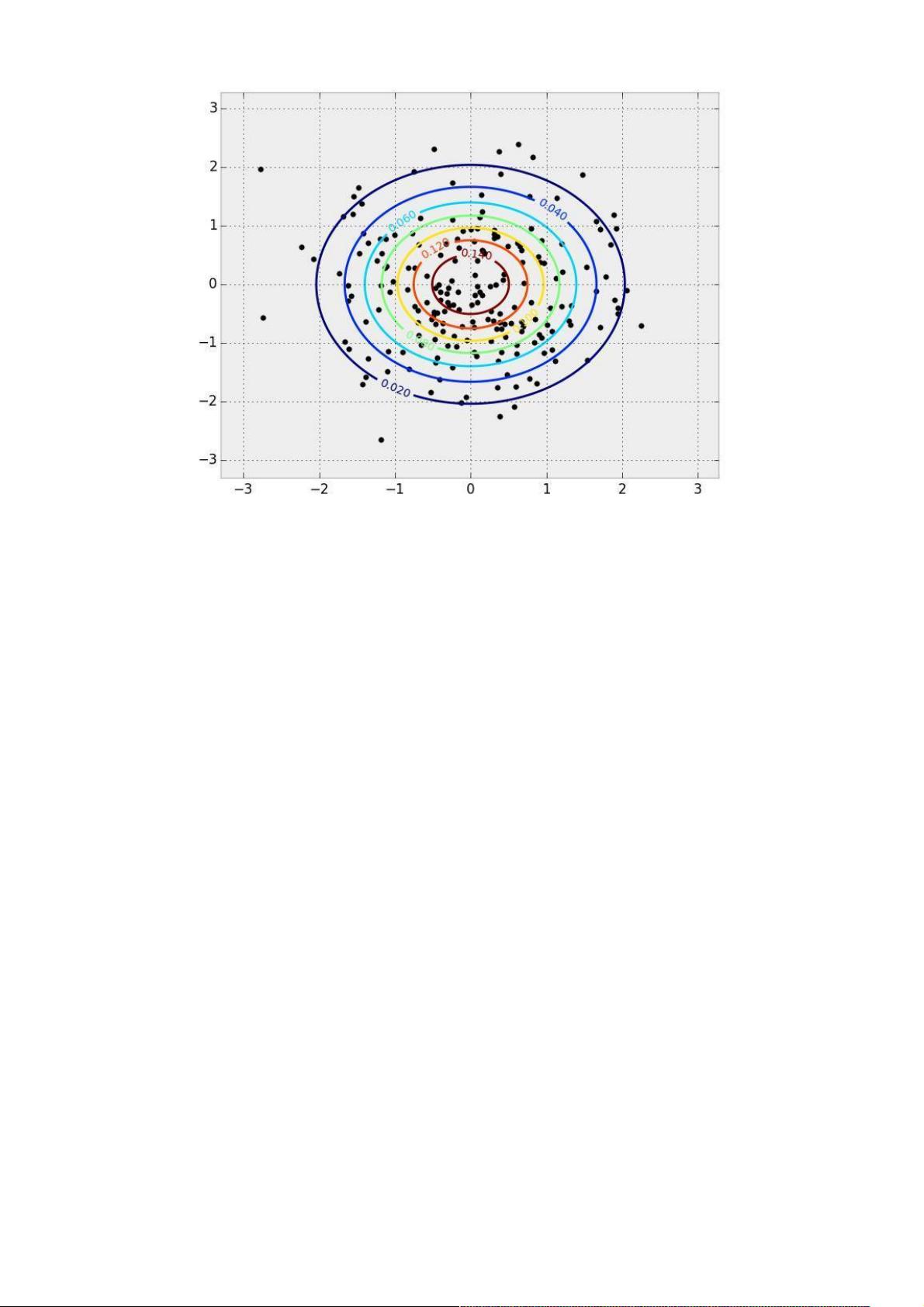
一个二维正态分布的 PDF 和样本。PDF 用等值线表示,样本覆盖在它上方。
图像和统计学之间的关键联系在于,我们可以把图像解析成一个高维概率分布中的样本点。想象一下你正拿着相机拍照。这张
照片上有数量有限的像素点。你可以认为你刚拍下的这张照片上的像素点的概率组成了一个概率分布。当你用相机拍这张照片
时,你就是在从这个复杂的概率分布中取样。这种分布就是我们用来判断什么样的内容正常或不正常的依据。在本文中,我们
要用的是用 RGB 颜色模式表示的彩色图片。我们的图像宽度为64像素,高度也为64像素,因此我们的概率分布有 64?64?
3≈12k 个维度。图片不像正态分布,我们不知道真正的概率分布,我们只能收集样本点。
那么该怎样修复图片呢?
让我们首先考虑下之前的多元动态分布。对于 x=1 ,最有可能的 y 值是多少?我们可以通过 x=1 固定时在所有可能的 y 值上最
大化 PDF 的值来找到这个 y 。
剩余13页未读,继续阅读
2020-11-18 上传
点击了解资源详情
点击了解资源详情
2021-03-04 上传
2020-12-21 上传
2023-12-28 上传
2021-01-29 上传

weixin_38502292
- 粉丝: 5
- 资源: 965
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
