k-means算法详解与评估指标:F1-score、Accuracy与NMI
需积分: 5 24 浏览量
更新于2024-06-16
收藏 992KB PPTX 举报
标题:"k-means学习:深入理解k-means算法及评估指标"
k-means是一种常用的无监督聚类算法,用于将数据集分为预设数量的簇。本文主要关注于如何利用k-means算法对数据进行聚类,并重点介绍了评估k-means聚类结果的关键指标。
**k-means算法核心**
k-means通过迭代过程,将每个数据点分配到与其最接近的簇中心(质心),然后更新簇中心的位置,直到达到收敛或达到预设的迭代次数。其基本步骤包括初始化质心、分配数据点到最近的簇、更新簇中心位置和重复这些步骤直到收敛。
**评判指标理解**
1. **F-measure (F1-score)**:
F1-score,又称为F1分数,是精确率(precision)和召回率(recall)的调和平均数。精确率表示预测为某类的样本中有多少是真正属于该类的,而召回率则是实际属于该类的样本中有多少被正确识别。F1-score用于评估分类性能,当类别不平衡时尤其重要,因为它综合考虑了误判的两种情况。
2. **Accuracy (ACC)**:
ACC是分类准确率,即正确分类的样本占总样本的比例。然而,当数据集中各类别的样本数量严重不平衡时,准确率可能会失真,因为它对错误分类的敏感性较低。例如,在广告点击率问题中,若负样本远多于正样本,预测所有样本为负类,尽管总体上准确率很高,但模型的实际价值可能很低。
3. **Normalized Mutual Information (NMI)**:
NMI是另一种衡量数据集划分与真实类别关系的指标,它量化了两个分类方案的相似性,范围从0到1,1表示完全一致。
4. **Random Index (RI)** 和 **Adjusted Random Index (ARI)**:
RI是随机分配相同数量的簇能得到的期望值与实际结果之间的比例,反映聚类效果是否优于随机猜测。ARI是对RI的调整,考虑了类别平衡性,适用于处理类别不均衡的数据。
**评估指标选择与应用**
在实际应用中,根据数据特点和任务需求,需要综合考虑这些指标。如果数据类别平衡,可以选择准确率;若类别不平衡,F1-score更为合适,因为它能更全面地反映分类性能。NMI和ARI对于评估聚类质量非常有用,尤其是在数据簇有明确类别结构的情况下。在k-means算法评估过程中,除了这些指标,还可以观察簇的形状、大小和内部一致性等直观信息。
总结,理解并合理运用这些评估指标可以帮助我们更好地评估k-means聚类结果的有效性和性能,从而优化算法参数或尝试其他更适合的聚类方法。
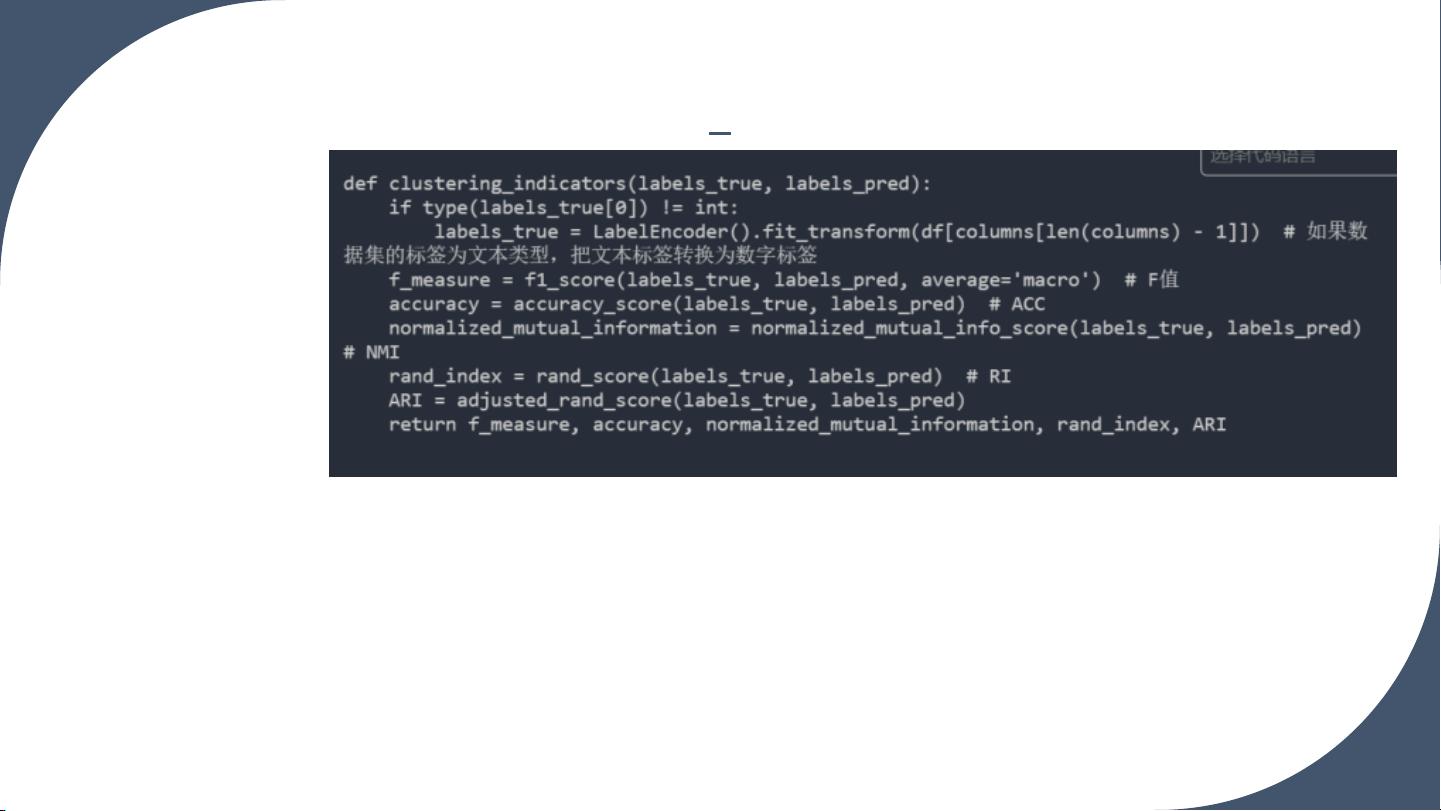
F_measure
f_measure=f1_score(labels_true,
labels_pred,average='macro')#F值.
ACC
accuracy=accuracy_score(labels_true,
labels_pred)#ACC
NMI
normalized_mutual_information=
normalized_mutual_info_score(label
s_true,labels_pred)#NMI
RI, ARI
rand_index=rand_score(labels_true,
labels_pred)#RI
ARI=
adjusted_rand_score(labels_true,
labels_pred)
指标理解
这里理解我用到
的是原本的代码
内容,查找了相
关函数介绍和指
标含义解析
剩余18页未读,继续阅读
2022-07-14 上传
2021-09-29 上传
2022-07-09 上传
2021-09-30 上传
2021-09-10 上传

菜包咕咕嘎嘎
- 粉丝: 0
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
