Python NLTK:文本数据分析入门与分词详解
104 浏览量
更新于2024-08-30
收藏 173KB PDF 举报
在本期Python数据分析的第六集中,我们重点探讨了如何利用Python中的Natural Language Toolkit (NLTK) 进行文本数据分析。NLTK是自然语言处理领域中最常用的Python库之一,它是一个开源项目,内置了丰富的功能,包括分词、分类以及强大的社区支持,对于文本挖掘和理解具有重要的作用。
首先,我们讨论了如何安装NLTK。通过pip工具,可以轻松地执行`pip install nltk`命令来安装。安装过程中,如果网络连接不稳定,可能需要离线下载所需的资源。在导入nltk库后,可以使用`nltk.download()`函数下载所需的语料库,如布朗语料库(Brown Corpus),它包含了多种类型的文本样本,用于后续的分析和研究。
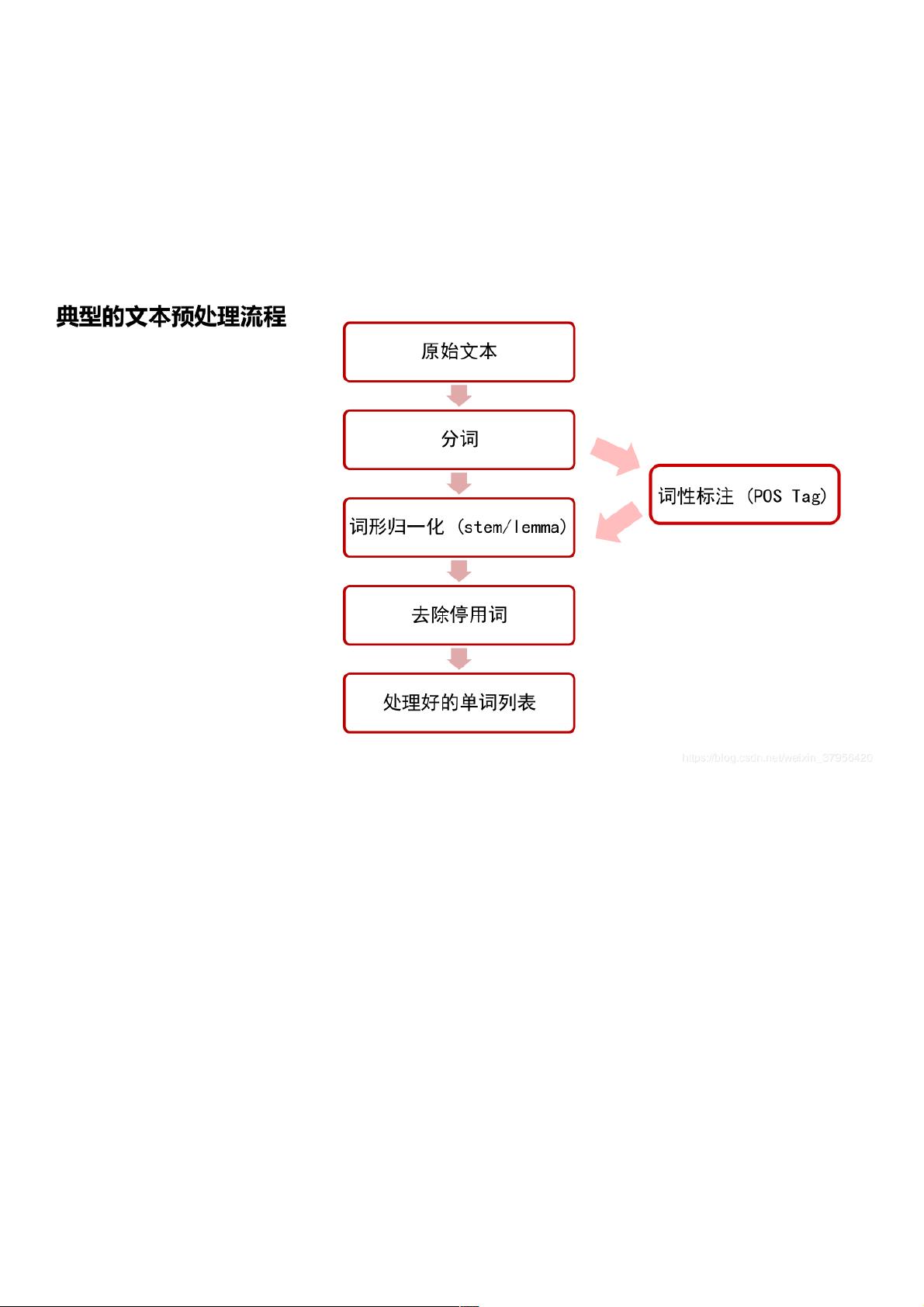
文本预处理是数据分析的关键步骤,其中分词是基础任务。在英文中,通常使用空格作为分隔符,例如在提供的例子中,`nltk.word_tokenize()`函数被用来对句子"Python is a widely used high-level programming language for general-purpose programming."进行分词,结果得到一个单词列表:['Python', 'is', 'a', 'widely', 'used', 'high-level', 'programming', 'language', 'for', 'general-purpose', 'programming', '.']。
然而,中文分词相对复杂,因为没有空格作为天然的分隔。这时可以借助专门的中文分词工具,比如jieba分词。对于特殊字符的处理,可以利用正则表达式进行规范化或移除,确保数据的一致性和准确性。
此外,NLTK还提供了其他文本预处理功能,如去除停用词(常见但无实际含义的词汇)、词干提取(将词还原到其基本形式)、词性标注(识别每个词的语法角色)等。这些步骤有助于减少噪音,提取更有价值的信息,为后续的文本分析和机器学习模型训练做准备。
Python和NLTK为文本数据分析提供了强大的工具和方法,通过安装、数据预处理和利用丰富的语料库,我们可以对文本进行深入理解和挖掘,从而在诸如情感分析、主题建模、文本分类等领域取得显著成果。无论是初学者还是专业人员,掌握这些技能都是提高数据科学能力的关键。
Python 数据分析第六期数据分析第六期–文本数据分析文本数据分析
Python 数据分析第六期数据分析第六期–文本数据分析文本数据分析
1. Python 文本分析工具文本分析工具 NLTK
NLTK (Natural Language Toolkit)
NLP 领域最常用的一个 Python 库 , NLP(natural language process), 开源项目 , 自带分词,分类功能,强大的社区支持。
1.1 NLTK 安装安装
pip install nltk
语料库的安装,在命令行里安装,如果安装不成功,可离线下载。
import nltk
nltk.download()
1.2 文本预处理文本预处理
1.2.1 分词分词
将句子拆分成具有语言语义学上意义的词 , 英文可用空格区分,而中文没有,较复杂,可用中文分词工具,如 “ 结巴分词 ” , 特殊字符的处理,可用正则表达式进行
处理。
import nltk
from nltk.corpus import brown
# 需要下载brown语料库
# 引用布朗大学的语料库
# 查看语料库包含的类别
print(brown.categories())
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
# 查看brown语料库
print('共有{}个句子'.format(len(brown.sents())))
print('共有{}个单词'.format(len(brown.words())))
共有57340个句子
共有1161192个单词
sentence = "Python is a widely used high-level programming language for general-purpose programming."
tokens = nltk.word_tokenize(sentence) # 需要下载punkt分词模型
print(tokens)
['Python', 'is', 'a', 'widely', 'used', 'high-level', 'programming', 'language', 'for', 'general-purpose', 'programming', '.']
结巴分词结巴分词
# 安装 pip install jieba
import jieba
seg_list = jieba.cut("欢迎进入大学", cut_all=True)
print("全模式: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("欢迎进入大学", cut_all=False)
print("精确模式: " + "/ ".join(seg_list)) # 精确模式
1.2.2 词形归一化词形归一化
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-04-24 上传
2023-06-29 上传
2022-03-08 上传
2023-06-11 上传

weixin_38625448
- 粉丝: 8
- 资源: 956
 我的内容管理
展开
我的内容管理
展开







