Gradient-based Hyperparameter Optimization through Reversible Learning
the missing steps of the training procedure (forwards) as
needed during the backward pass. However, this would re-
quire too much memory to be practical for large neural nets
trained for thousands of minibatches.
3. Experiments
In typical machine learning applications, only a few hyper-
parameters (less than 20) are optimized. Since each ex-
periment only yields a single number (the validation loss),
the search rapidly becomes more difficult as the dimen-
sion of the hyperparameter vector increases. In contrast,
when hypergradients are available, the amount of informa-
tion gained from each training run grows along with the
number of hyperparameters, allowing us to optimize thou-
sands of hyperparameters. How can we take advantage of
this new ability?
This section shows several proof-of-concept experiments in
which we can more richly parameterize training and regu-
larization schemes in ways that would have been previously
impractical to optimize.
3.1. Gradient-based optimization of gradient-based
optimization
Modern neural net training procedures often employ var-
ious heuristics to set learning rate schedules, or set their
shape using one or two hyperparameters set by cross-
validation (Dahl et al., 2014; Sutskever et al., 2013). These
schedule choices are supported by a mixture of intuition,
arguments about the shape of the objective function, and
empirical tuning.
To more directly shed light on good learning rate schedules,
we jointly optimized separate learning rates for every sin-
gle learning iteration of training of a deep neural network,
as well as separately for weights and biases in each layer.
Each meta-iteration trained a network for 100 iterations of
SGD, meaning that the learning rate schedules were spec-
ified by 800 hyperparameters (100 iterations ⇥ 4 layers ⇥
2 types of parameters). To avoid learning an optimization
schedule that depended on the quirks of a particular random
initialization, each evaluation of hypergradients used a dif-
ferent random seed. These random seeds were used both to
initialize network weights and to choose mini batches. The
network was trained on 10,000 examples of MNIST, and
had 4 layers, of sizes 784, 50, 50, and 50.
Because learning schedules can implicitly regularize net-
works (Erhan et al., 2010), for example by enforcing early
stopping, for this experiment we optimized the learning rate
schedules on the training error rather than on the validation
set error. Figure 2 shows the results of optimizing learning
rate schedules separately for each layer of a deep neural
network. When Bayesian optimization was used to choose
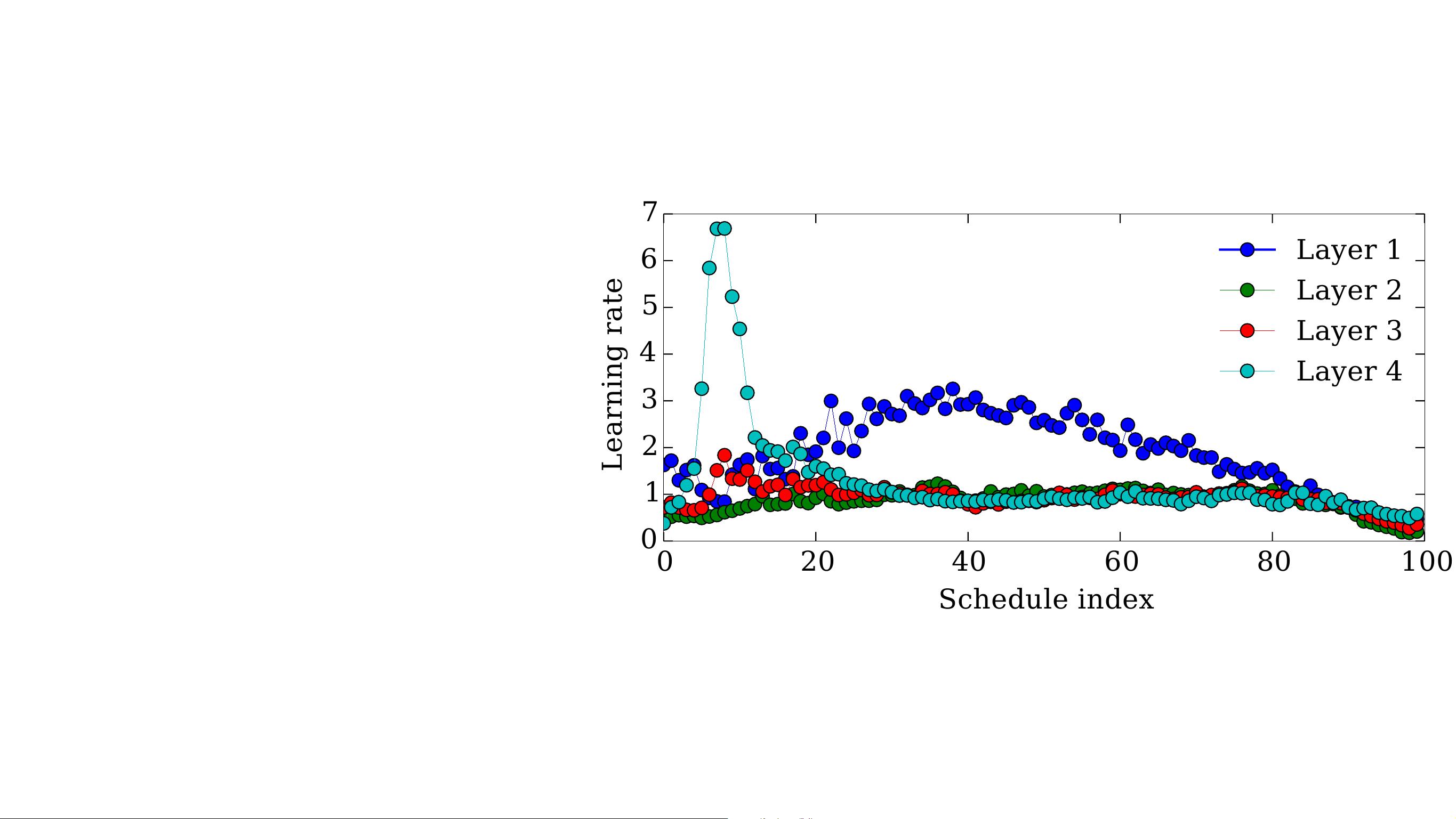
Optimized learning rate schedule
Figure 2. A learning-rate training schedule for the weights in each
layer of a neural network, optimized by hypergradient descent.
The optimized schedule starts by taking large steps only in the
topmost layer, then takes larger steps in the first layer. All layers
take smaller step sizes in the last 10 iterations. Not shown are
the schedules for the biases or the momentum, which showed less
structure.
Elementary learning curves Meta-learning curve
Figure 3. Elementary and meta-learning curves. The meta-
learning curve shows the training loss at the end of each elemen-
tary iteration.
a fixed learning rate for all layers and iterations, it chose a
learning rate of 2.4.
Meta-optimization strategies We experimented with
several standard stochastic optimization methods for meta-
optimization, including SGD, RMSprop (Tieleman & Hin-
ton, 2012), and minibatch conjugate gradients. The results
in this section used Adam (Kingma & Ba, 2014), a variant
of RMSprop that includes momentum. We typically ran for
50 meta-iterations, and used a meta-step size of 0.04. Fig-
ure 3 shows the elementary and meta-learning curves that
generated the hyperparameters shown in Figure 2.
How smooth are hypergradients? To demonstrate that
the hypergradients are smooth with respect to time steps
in the training schedule, Figure 4 shows the hypergradient
with respect to the step size training schedule at the begin-
ning of training, averaged over 100 random seeds.


 我的内容管理
展开
我的内容管理
展开







