处理多重共线性:案例分析与方差扩大因子法
82 浏览量
更新于2024-08-29
收藏 408KB PDF 举报
在第五章中,我们探讨了数据分析中的一个重要假设——多重共线性(Multicollinearity),它是指在统计模型中两个或多个自变量之间高度相关,可能导致估计量不稳定、标准误差增大以及回归系数的解释困难。本节通过Python编程实践来学习如何检测和处理这个问题。
首先,章节开始部分介绍了数据的导入和加载流程。利用`os`, `tarfile`, `urllib`, 和 `urllib.request` 等库,定义了下载和解压数据集的函数`fetch_housing_data`。数据集来源于`handson-ml2`项目,存储在一个名为`housing`的CSV文件中,通过调用`load_housing_data`函数读取并预览数据,确保数据已经正确加载。
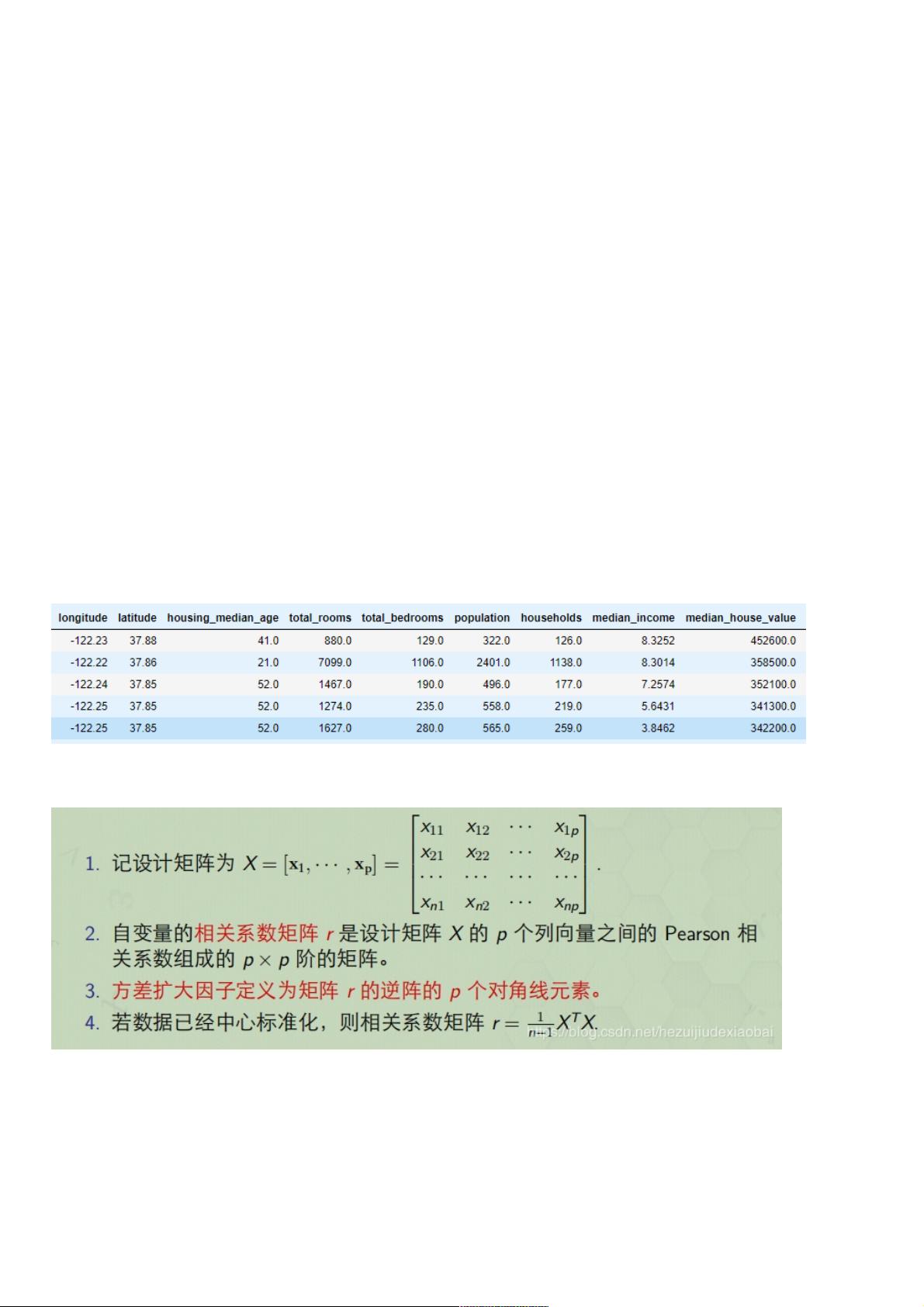
接下来,作者计算了各特征之间的皮尔逊相关系数(`r_xy`),这是一个衡量变量间线性关系强度的指标。如果发现存在较高的相关性(通常阈值设置在0.7或0.8以上),则可能存在多重共线性问题。为了识别哪些特征可能造成这一问题,列出了所有特征(除了目标变量`median_house_value`)。
方差扩大因子(Variance Inflation Factor, VIF)是用于检测多重共线性的一个常用工具。VIF值越大,表示两个特征之间的关联度越高,可能对模型的估计造成困扰。通过计算每个特征的VIF值,可以确定需要进一步分析或调整的变量。VIF的计算通常涉及到统计软件或特定库中的函数,例如在R语言中使用`vif()`函数。
处理多重共线性的方法有:
1. **删除相关性强的特征**:如果发现两个或多个特征之间高度相关,可以选择其中一个作为代表,或者根据领域知识和业务理解进行删除。
2. **主成分分析(PCA)或因子分析(Factor Analysis)**:这些降维技术可以将相关特征转化为不相关的因子,从而减少多重共线性。
3. **正则化(如岭回归或LASSO)**:通过引入惩罚项,模型会倾向于选择具有更小权重的特征,有助于缓解共线性的影响。
4. **模型改进**:在回归模型中,可以尝试使用更复杂的模型结构,如逐步回归或模型融合,以减少共线性带来的问题。
本章的核心内容围绕着在实际数据分析过程中如何通过实例操作识别和解决多重共线性的问题,这对于建立稳定且可解释的模型至关重要。掌握这些技巧,可以帮助避免模型性能下降,并提高预测的准确性和可靠性。
第五章第五章 违背基本假设的情况违背基本假设的情况
多重共线性的检验与处理多重共线性的检验与处理
0 导入导入&加载数据加载数据
import os
import tarfile
import urllib
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing") # 把目录和文件名合成一个路径
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path): # 判断路径是否为目录
os.makedirs(housing_path) # 递归创建目录
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path) # 将URL检索到磁盘上的临时位置
housing_tgz = tarfile.open(tgz_path) # 打开
housing_tgz.extractall(path=housing_path) # 解压
housing_tgz.close() # 关闭
fetch_housing_data()
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path) # 加载数据
housing = load_housing_data()
housing.head()
1 方差扩大因子法方差扩大因子法
概念
下载后可阅读完整内容,剩余3页未读,立即下载
103 浏览量
2021-10-02 上传
118 浏览量
2024-10-14 上传
134 浏览量
2024-12-27 上传
2025-02-18 上传
2025-03-10 上传
2025-01-03 上传

weixin_38713450
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多技术领域源码集锦:园林绿化官网企业项目
- 定制特色井字游戏Tic Tac Toe开源发布
- TechNowHorse:Python 3编写的跨平台RAT生成器
- VB.NET实现程序自动更新的模块设计与应用
- ImportREC:强大输入表修复工具的介绍
- 高效处理文件名后缀:脚本批量添加与移除教程
- 乐phone 3GW100体验版ROM深度解析与优化
- Rust打造的cursive_table_view终端UI组件
- 安装Oracle必备组件libaio-devel-0.3.105-2下载
- 探索认知语言连接AI的开源实践
- 微软SAPI5.4实现的TTSApp语音合成软件教程
- 双侧布局日历与时间显示技术解析
- Vue与Echarts结合实现H5数据可视化
- KataSuperHeroesKotlin:提升Android开发者的Kotlin UI测试技能
- 正方安卓成绩查询系统:轻松获取课程与成绩
- 微信小程序在保险行业的应用设计与开发资源包
