构建交互式Spark服务的REST作业服务器
需积分: 5 84 浏览量
更新于2024-07-19
收藏 3.61MB PDF 举报
本文档探讨了构建一个用于交互式Spark as a Service的REST Job Server的过程。该服务器旨在提供一种便捷的方式,使用户能够在任何地方轻松访问Spark环境,支持多种编程语言(如Scala、Java、Python和R),并且独立于Hue平台。以下是主要讨论点:
1. **需求背景**:
- 需求推动因素:由于Spark Notebook的流行,以及远程协作和共享Spark上下文和RDD的需求,构建一个服务化的Spark解决方案变得必要。
- 功能目标:提供易用的访问方式,允许用户提交交互式Shell会话或批处理作业。
2. **历史演进**:
- **V1: Oozie**:
- 初始尝试是通过Oozie进行Spark作业调度,它支持提交和监控,但速度较慢且局限于批处理作业,不支持交互式Shell。
- 优点:提交和控制简单,缺点是缺乏交互式功能和对Python、R的支持,且安全性方面有局限性。
- **V2: Spark Igniter**:
- 进一步的改进,提供了编译器支持和更安全的批处理作业,但仅限于Scala,且不支持Python和R。
- 优点:提高了性能和安全性,缺点是功能较为有限。
- **V3: Notebook**:
- Spark Notebook引入了类似`spark-submit`和Spark Shell的功能,支持Scala、Python和R,以及jar包和批处理作业,但当时仍处于beta阶段。
- 亮点:提供了更丰富的交互体验,但可能存在不稳定性和扩展性挑战。
3. **现代解决方案:Livy + Spark Server**:
- **Livy**:是现代架构的核心,它是一个基于REST API的交互式Spark执行服务,允许跨语言(Scala、Java、Python和R)的作业提交和管理。
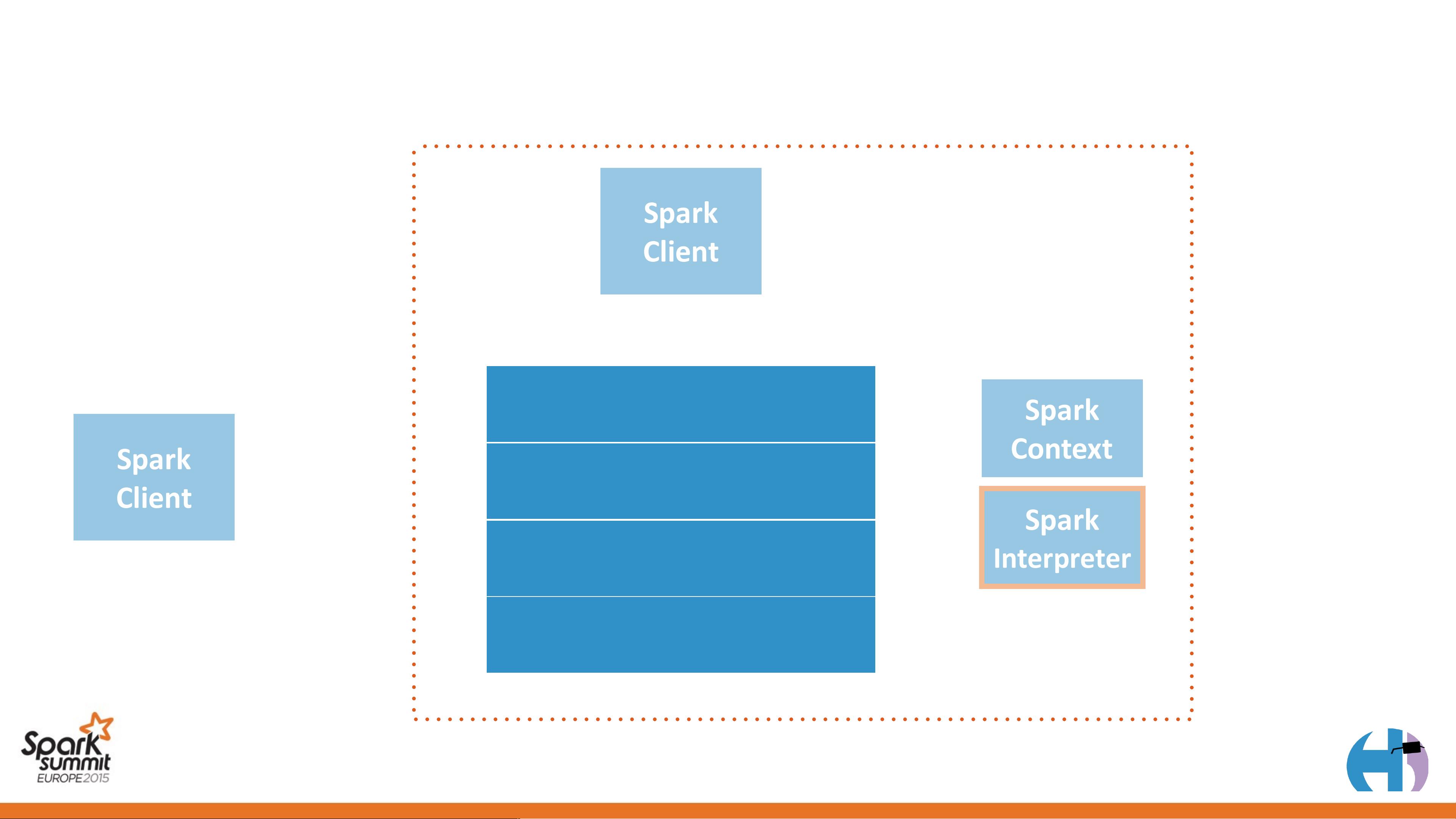
- **Spark Server**:
- 实现了一个Scala编写的RESTful web服务器,专注于接收Spark作业请求,包括交互式Shell会话和批处理作业。
- 优势:提供统一的接口,无需依赖Hue,增强了灵活性和兼容性。
- 架构组件:
- Livy作为核心服务,负责执行Spark任务并返回结果。
- Spark Server作为前端,与用户交互并调用Livy API。
- YARN(Yet Another Resource Negotiator)作为资源管理系统,确保Spark任务在集群上高效运行。
总结:
构建一个REST Job Server是为了满足用户对灵活、跨语言的Spark访问需求,尤其在分布式环境下。Livy的引入极大地简化了交互式Spark服务的部署和使用,使得Spark不仅仅局限于批处理,还可以支持实时分析和开发。通过与Spark Server集成,用户可以在任何地方使用多种编程语言进行数据处理和开发,提升了Spark as a Service的整体用户体验和生产力。

ARCHITECTURE
•
/#8,*8&*!$+1!(+&R-9+S!$&8..+&!8&%0,*!(.8&'J(012-#! K!/. 8&'!(3+77(!
•
LMFD!2%*+C!/.8&'!*&-R+&(!&0,!-, (-* +!#3+!970(#+&!U(0..%&#(!9&8(3+(V!
•
D%!,++*!#%!-,3+&-#!8,<!-,#+&>89+!%&!9%2.-7+!9%*+!
•
O@#+,*+*!#%!$%&'!$-#3!8**-#-%,87!189'+,*(

剩余82页未读,继续阅读
115 浏览量
131 浏览量
231 浏览量
136 浏览量
2022-09-21 上传
127 浏览量
2009-12-27 上传
2024-07-21 上传
106 浏览量

闪耀之星AK
- 粉丝: 35
- 资源: 36
 我的内容管理
展开
我的内容管理
展开







