Hadoop与Spark入门:数据密集系统原理与实践
需积分: 9 123 浏览量
更新于2024-07-17
收藏 2.78MB PDF 举报
《数据密集型系统:Hadoop与Spark原理与基础》是一本由Tomasz Wiktorski撰写的专业书籍,针对大数据和数据科学应用提供核心概念的深入介绍。该书适用于初学者,帮助他们建立对数据密集型系统的基础理解,以便在深入学习时能够独立工作并掌握当前技术领域的高级参考资料。
书中采用问题导向的学习方法,每个章节围绕简化但实际的问题展开,通过数据密集技术解决。读者将跟随一个基于Apache开源数据集的参考场景,逐步了解Hadoop的运用。这本书的起源可以追溯到斯泰万格大学的数据密集型系统硕士课程,部分章节还被用作普渡大学和罗兹理工大学的客座讲座。
书中的内容包括:
1. 引言:概述数据密集型系统的重要性,以及Hadoop和Spark在其中的角色。
2. Hadoop 101及参考场景:对Hadoop的基本概念进行入门级讲解,包括其分布式计算模型、HDFS(Hadoop分布式文件系统)和MapReduce的工作原理。
3. 功能抽象:阐述如何通过抽象层理解和使用Hadoop,简化开发过程。
4. MapReduce:深入研究这种编程模型,包括算法和模式,如Shuffle操作和Combiner优化。
5. Hadoop架构:详细解析Hadoop集群的组成,如NameNode、DataNode和JobTracker等组件。
6. NOSQL数据库:介绍非关系型数据库如何配合Hadoop处理大规模数据,比如Cassandra和HBase。
7. Spark:对比Hadoop,讨论Spark的内存计算模型(Resilient Distributed Dataset, RDD),以及其DataFrame和Spark Streaming等高级特性。
《SpringerBriefs in Advanced Information and Knowledge Processing》系列是Springer出版社推出的一个简洁而前沿的学术平台,本书作为该系列的一部分,旨在为研究人员提供一个发表尚未成熟但超出研讨会论文或期刊文章水平的研究成果的渠道。主题涵盖大数据分析、大数据知识、生物信息学、商业智能、计算机安全、数据挖掘和知识发现、信息质量和隐私保护等领域。
《Data-intensive Systems: Principles and Fundamentals using Hadoop and Spark》不仅提供了一本实用的技术指南,也是探索和理解数据密集型系统核心理论和技术的重要资源,适合那些希望在这个领域深入发展的专业人士。
6 2 Introduction
2.1 Growing Datasets
Data growth is one of the most important trends in the industry nowadays. The same
applies also to science and even to our everyday lives. Eric Schmidt famously said in
2010, as Google’s CEO at that time, that every 2 days we create as much information
as we did up to 2003. This statement underlines a fact that the data growth we observe
is not just linear, but it is accelerating.
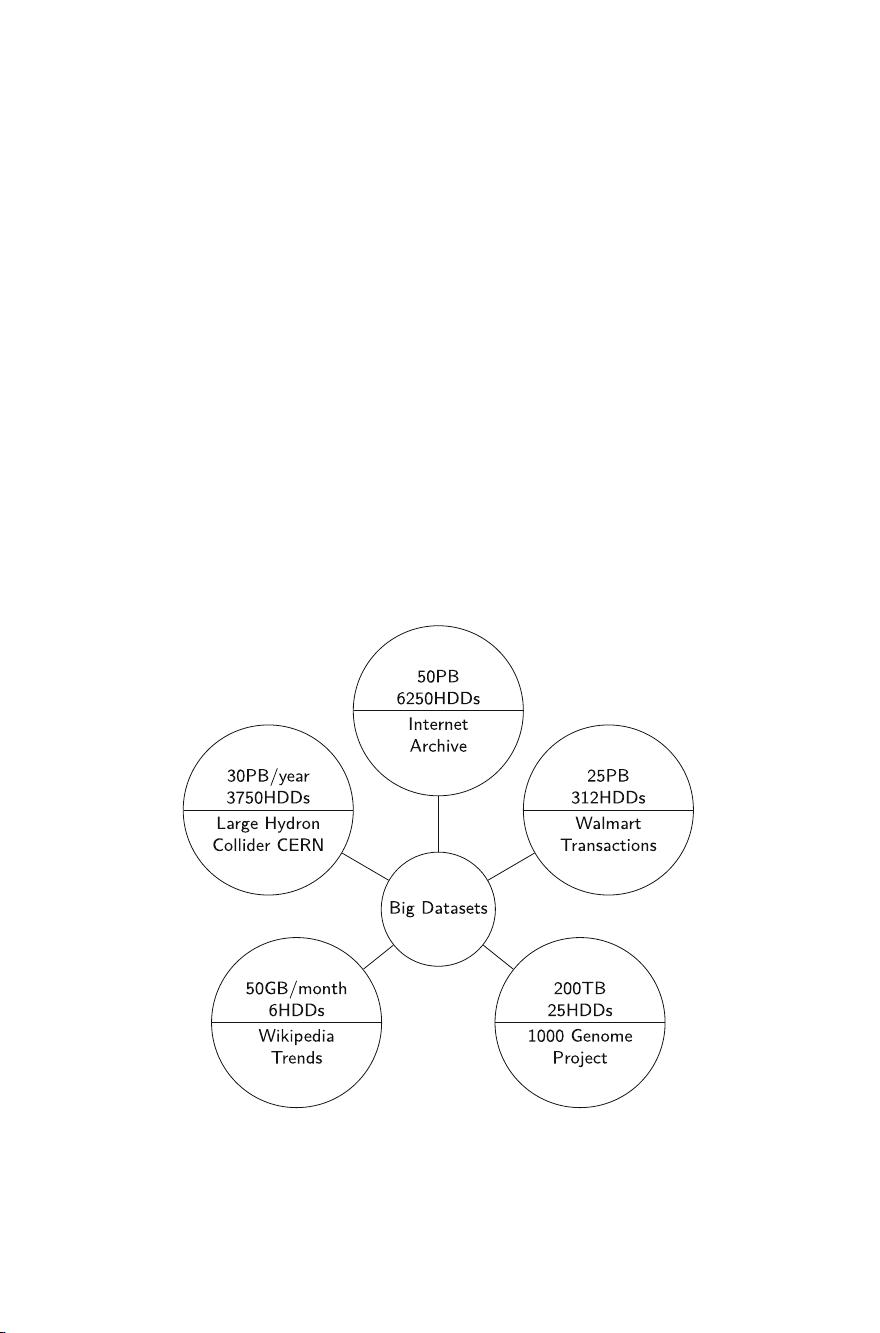
Let us look at a few examples of big datasets in Fig. 2.1. You are most prob-
ably familiar with a concept of trending articles on Wikipedia. It presents hourly
updated Wikipedia trends. Have you ever wondered how these trends are determined?
Wikipedia servers store page traffic data aggregated per hour; this leads quite directly
to the calculation of trends. However, one caveat is the amount of data it requires.
One month of such data requires 50 GBs of storage space and related computational
capabilities. While it is not much for each separate month, at moment you want to
analyze data from several months, both storage and computation become a consid-
erable challenge. In one of the earlier chapters, we already discussed the analysis
of genomic information as one of the major use cases for data-intensive systems, of
which 1000 Genomes Project is a famous example. Data collected as a part of this
project require 200 TBs of storage.
Fig. 2.1 Examples of big datasets. Source Troester (2012); European Organization for Nuclear
Research (2015); The Internet Archive (2015); Amazon Web Services (2015)


剩余104页未读,继续阅读
2015-05-07 上传
2019-02-06 上传
2021-04-22 上传
2021-06-05 上传
2021-06-05 上传
2021-03-14 上传
2021-05-24 上传
2021-05-16 上传
2021-04-30 上传

THESUMMERE
- 粉丝: 23
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
