Python机器学习实战:揭秘内容流行预测
版权申诉
64 浏览量
更新于2024-06-26
收藏 3.5MB PDF 举报
"《Python机器学习项目开发实战_预测你的内容是否会广为流传_编程案例实例课程教程.pdf》是一份实用的教程,专注于利用Python进行机器学习项目的开发,特别是围绕如何预测内容的流行度。课程从现实生活中的故事开始,讲述了Jonah Peretti如何通过创新思维和巧妙策略,将一场关于耐克个性化运动鞋的争议转变为了一场病毒式的传播事件。Peretti利用机器学习技术分析内容的共享特性,挑战了看似难以复制的“病毒式传播”。
在2001年,作为一名研究生,Peretti通过与耐克公司的互动,发现了一个现象:某些特定内容能迅速在互联网上扩散。他与耐克客服的邮件交流成为关注焦点,最终引发全球媒体的广泛关注。这个案例促使Peretti的好友Cameron Marlow与其打赌,能否复制耐克事件的成功。
课程深入探讨了病毒性内容的研究,包括:
1. 关于病毒性研究的洞察:通过分析大量广为流传的内容,揭示其背后的共享规律和普遍特征,理解是什么使这些内容能够吸引人们主动分享。
2. 分享行为的量化分析:如何衡量和预测内容的被分享次数和范围,这在机器学习中是一个关键的预测任务。
3. 探索可共享性特征:识别那些促成内容快速传播的因素,如情感共鸣、新颖性、信息价值等,这些因素在内容设计和传播策略中至关重要。
4. 构建预测性内容评分模型:利用Python的机器学习工具,开发出能够预测内容受欢迎程度的模型,这对于内容创作者和营销人员来说,是提高内容传播效果的重要工具。
通过这个项目实战,学员将不仅学习到Python编程和机器学习技术,还能掌握如何运用这些技术去理解和创造具有高传播潜力的内容。课程目标是帮助读者理解内容传播的科学,从而在实际工作中提升他们的营销策略和创新能力。"
142
第 6 章预测你的内容是否会广为流传
link_class = browser.find_elements_by_class_name("link_read_more_article")
stats = browser.find_elements_by_class_name("ruzzit_statistics_area")
在最后一节中,我们选择了分析所需的页面元素。接下来,需要进一步解析它们以获
取文本信息。
我在分析中去除 Twitter 所提供的分享次数。该公司在 2015 年年底决定从其标准 API
中删除此项数据。鉴于此,其展示的次数不太可靠。为了避免数据被污染的风险,最好直
接去除这些信息。
all_data = []
for title, link, stat in zip(titles, link_class, stats):
all_data.append((title.text,\
link.get_attribute("href"),\
stat.find_element_by_class_name("col-md-
12").text.split(' shares')[0],
stat.find_element_by_class_name("col-md-
12").text.split('tweets\n')
[1].split('likes\n0')[0],
stat.find_element_by_class_name("col-md-
12").text.split('1's\n')[1].split(' pins')[0],
stat.find_element_by_class_name("col-md-
12").text.split('pins\n')[1]))
接下来,我们将它放入一个数据框。
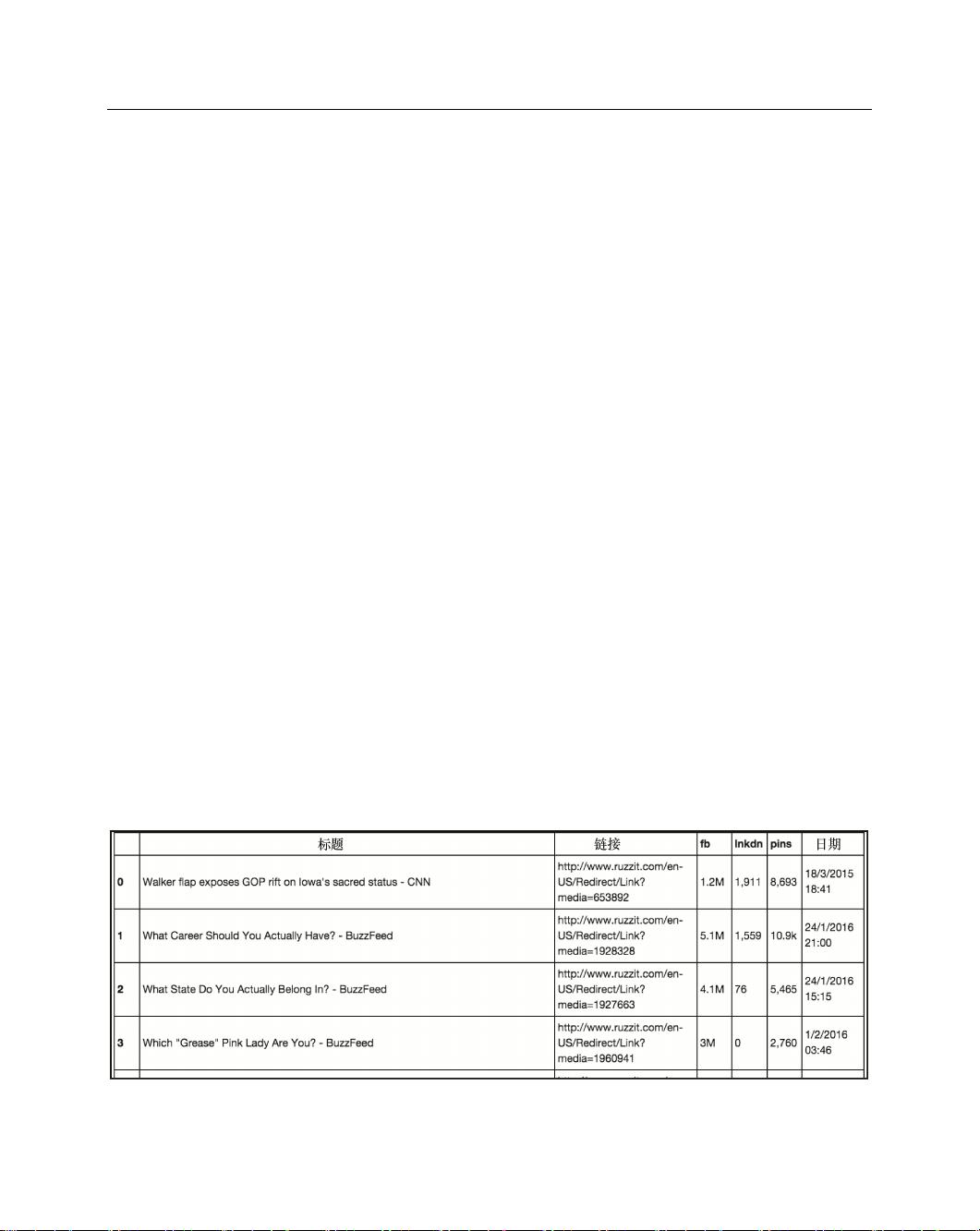
df = pd.DataFrame(all_data, columns=['title', 'link', 'fb', 'lnkdn',
'pins', 'date'])
df
上述代码生成图 6-3 的输出。
图 6-3
剩余24页未读,继续阅读

好知识传播者
- 粉丝: 1670
- 资源: 4133
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
