理解Linux中的AT&T汇编语言
需积分: 9 47 浏览量
更新于2024-08-01
收藏 236KB PDF 举报
"Linux中的汇编语言"
在深入探讨Linux中的汇编语言之前,先要理解为何在现代操作系统中,如Linux,仍然会使用汇编语言。尽管C语言因其高级抽象和跨平台兼容性成为了系统编程的首选,但在某些特定场景下,如初始化进程、处理中断、优化关键性能部分或者直接操作硬件时,汇编语言因其直接性和高效性显得不可或缺。例如,操作系统内核的初始化过程通常包含大量与硬件交互的低级操作,这些操作用汇编编写更为直观和可控。
汇编语言根据不同的架构和环境有不同的语法。在Linux中,特别是针对x86架构,通常使用的是AT&T风格的汇编,而不是Intel的原生格式。这是因为Unix传统的影响,AT&T的汇编格式在早年Unix系统移植到i386时被广泛采用。两者之间的主要区别在于指令表示方式和语法结构。
1. 寄存器引用:
- Intel汇编中,寄存器名称如`eax`、`ebx`等直接使用,而AT&T汇编则在其前面加上百分号`%`,如`%eax`、`%ebx`。
- 对于立即数,Intel汇编中直接写数值,而AT&T汇编则使用美元符号`$`前缀,如`mov eax, 8`在AT&T中变为`movl $8, %eax`。
2. 指令格式:
- Intel汇编通常使用源和目标的顺序,如`mov eax, ebx`,而AT&T汇编则相反,如`movl %ebx, %eax`。
- 在Intel汇编中,内存地址操作通常需要指定段前缀,而在AT&T汇编中,段选择通常是隐含的。
3. 数值表示:
- Intel汇编中,十六进制数字后缀为`h`,二进制为`b`,如`0xffffh`、`0101b`。AT&T汇编中,十六进制前缀为`0x`,无二进制前缀,如`0xffff`。
了解这些基本差异后,对于有Intel汇编基础的读者来说,学习和理解AT&T汇编语言将变得更容易。例如,Intel的`mov eax, 0xffff`在AT&T中写为`movl $0xffff, %eax`。
汇编语言的学习不仅仅是理解语法,还需要掌握硬件层面的知识,包括CPU的架构、指令集、内存模型等。在Linux环境下,这通常涉及到对x86架构的理解,如通用寄存器、控制寄存器、段寄存器的使用,以及如何通过汇编来执行系统调用、内存管理、中断处理等。
在阅读Linux源代码时,遇到汇编语言片段,可以通过以下步骤来理解和分析:
1. 分析上下文:了解代码所在的功能模块,判断这段汇编的作用。
2. 查阅手册:参考Intel的《软件开发者手册》和Linux汇编程序员指南,获取指令和寄存器的具体功能。
3. 转换为C语言:如果可能,尝试将汇编代码转换为等效的C语言,以帮助理解其逻辑。
4. 实践调试:使用GDB等调试工具,观察汇编代码在运行时的行为。
虽然汇编语言在阅读和理解上存在挑战,但它在Linux系统编程中的地位不可替代。掌握汇编语言,尤其是AT&T汇编,将有助于更深入地了解Linux内核的工作原理,对于系统优化和问题排查具有重要意义。
segreg:[base+index*scale+disp]
,而
AT&T
的格式是
%segreg:disp(base,index,scale)
。其中
index/scale/disp/segreg
全部是可选的,完全可以简化掉。如果没有指定
scale
而指定了
index
,则
scale
的缺省值为
1
。
segreg
段寄存器依赖于指令以及应用程序是运行在实模式
还是保护模式下,在实模式下,它依赖于指令,而在保护模式下,
segreg
是多余的。在
AT&T
中,当立即数用在
scale/disp
中时,不应当在其前冠以“
$”
前缀,表
2.3
给出其语
法及几个相应的例子。
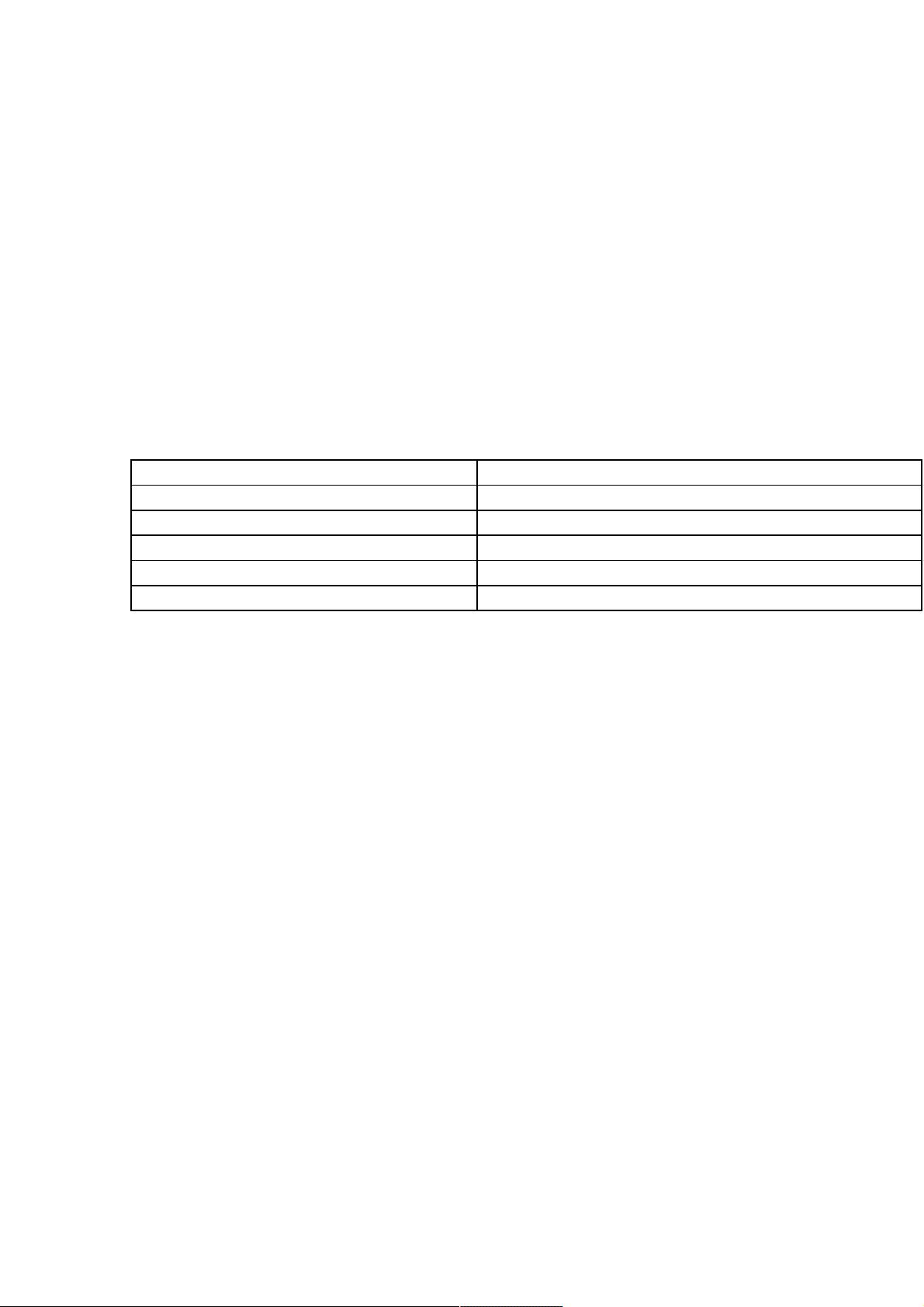
表
2.3
内存操作数的语法及举例
Intel 语法 AT&T 语法
指令 foo,segreg:[base+index*scale+disp] 指令 %segreg:disp(base,index,scale),foo
mov eax,[ebx+20h] Movl0x20(%ebx),%eax
add eax,[ebx+ecx*2h Addl (%ebx,%ecx,0x2),%eax
lea eax,[ebx+ecx] Leal (%ebx,%ecx),%eax
sub eax,[ebx+ecx*4h-20h] Subl -0x20(%ebx,%ecx,0x4),%eax
从表中可以看出,
AT&T
的语法比较晦涩难懂,因为
[base+index*scale+disp]
一眼就可
以看出其含义,而
disp(base,index,scale)
则不可能做到这点。
这种寻址方式常常用在访问数据结构数组中某个特定元素内的一个字段,其中,
base
为数组的起始地址,
scale
为每个数组元素的大小,
index
为下标。如果数组元素还
是一个结构,则
disp
为具体字段在结构中的位移。
5
.操作码的后缀
在上面的例子中你可能已注意到,在
AT&T
的操作码后面有一个后缀,其含义就是
指出操作码的大小。“
l”
表示长整数(
32
位),“
w”
表示字(
16
位),“
b”
表示字节
(
8
位)。而在
Intel
的语法中,则要在内存单元操作数的前面加上
byte ptr
、
word ptr,
和
dword ptr
,“
dword”
对应“
long”
。表
2.4
给出几个相应的例子。
表
2.4
操作码的后缀举例
剩余14页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2011-11-14 上传
2018-09-03 上传
2009-05-12 上传
2009-05-12 上传
2012-12-31 上传

jjwoll11
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
