MapReduce模型详解:分布式计算与Hadoop优化
需积分: 3 178 浏览量
更新于2024-09-10
收藏 3.01MB DOCX 举报
"MapReduce是Hadoop框架下的分布式计算模型,用于处理和生成大规模数据集。它将复杂的并行计算过程简化为两个主要阶段:Map和Reduce。HDFS(Hadoop Distributed File System)则是Hadoop的基础分布式文件系统,负责存储数据。MapReduce与HDFS结合,实现了高效的数据处理能力。"
MapReduce体系的核心在于Map和Reduce两个阶段。Map阶段将原始数据(例如天气数据文件)按块(Block)存储在DataNode上,并根据数据块进行拆分,形成多个Split。每个Split上运行一个Map任务,Map任务负责对输入数据进行预处理,例如在天气数据的例子中,将每年的天气温度整理成键值对形式。Map任务的结果会被Shuffle阶段整理,按照相同的键聚合,形成键对应的值的集合。
Shuffle阶段是Map和Reduce之间的过渡,它将Map任务产生的中间结果进行排序和分区,准备进入Reduce阶段。Reduce任务负责对每个键的值集合进行聚合操作,例如计算每一年的温度最大值。如果需要按年份区间计算,可以运行多个Reduce任务,每个任务处理特定区间的年份。
Hadoop设计时考虑了数据局部性原则,尽量让计算任务在数据所在的节点上执行,减少了数据在网络中的传输,提高了效率和可靠性。例如,Map任务通常会在包含输入数据的DataNode上运行。
此外,MapReduce系统还包括推测执行功能,用于应对任务执行缓慢或失败的情况。推测执行默认开启,但过多的推测任务可能会消耗资源,因此需要谨慎管理。JVM的重用策略也是优化性能的重要手段,通过复用已启动的JVM,避免频繁启动新JVM带来的开销。
在Hadoop集群中,JobTracker负责任务调度,TaskTracker执行具体任务。然而,高可用性是必须考虑的因素,因此需要应对JobTracker或TaskTracker所在节点的故障。HDFS的副本机制能容忍一定数量的DataNode故障,保证数据的完整性。
Hadoop还提供了丰富的命令行工具进行文件操作和管理。同时,为了监控和运维Hadoop集群,有各种第三方工具,它们可以帮助管理员跟踪HDFS事件,记录日志级别,例如WARN和INFO分别表示错误和常规事件的记录。这些工具对于保持Hadoop系统的稳定和高效运行至关重要。
总结来说,MapReduce体系是Hadoop的核心计算组件,与HDFS协同工作,实现大数据的高效处理。通过Map和Reduce任务的拆分,以及数据局部性、推测执行、JVM重用等策略,确保了大规模数据处理的效率和可靠性。同时,配合监控和运维工具,整个系统能够适应复杂的生产环境,满足大数据处理的需求。
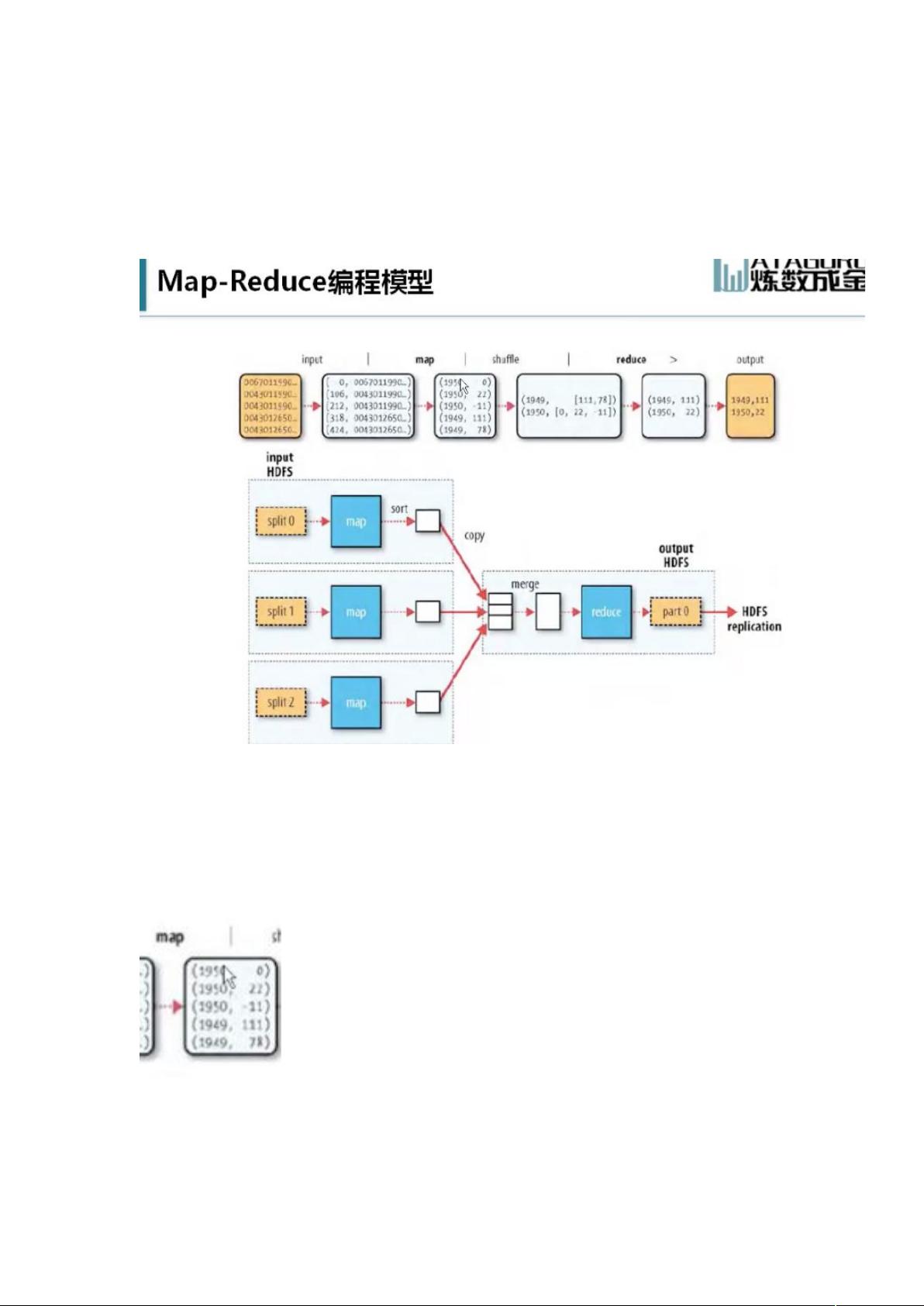
MapReduce 体系
Map Reduce
原始数据是很多天气数据的文件
分割成很多 block 存放在 DataNode 上,现在需要计算出每一年天气温度的最大
值
可以看到在每个 split 上,运行 Map 任务,
Map 任务的目的是将天气数据的每一年以及其对应的温度整
下载后可阅读完整内容,剩余8页未读,立即下载
2010-12-30 上传
2022-08-04 上传
2023-05-13 上传
2023-05-19 上传
2024-06-22 上传
2023-05-14 上传
2023-05-25 上传
2023-04-12 上传
2023-06-11 上传

yingmuhuadao1
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- MCS51单片机的寻址
- 用Flash制作选择题模板
- oracle10的优化
- Windows Communication Foundation 入门.pdf
- 中大ACM题库的分类
- datasheet-lm3s1138-zh_cn
- 基于ICL8038函数信号发生器的设计
- Makefile中文教程
- 杭电ACM1002解题答案
- Mean Shift图像分割的快速算法
- vxwork 6.6版本的bsp开发指导说明文档
- Windows嵌入式开发系列课程(3):WindowsCE.NET USB驱动开发基础.pdf
- Java反射机制Demo
- MyEclipse+6+Java开发教程
- 无废话JavaScript和html学习笔记
- 计算机专业软件工程的复习范围
