Apache Kylin与Parquet集成:高性能OLAP分析
需积分: 11 162 浏览量
更新于2024-07-16
收藏 3.09MB PDF 举报
"Kylin on Parquet.pdf 是一份由Kyligence工程师王汝鹏在2020.04.13分享的文档,主要介绍了开源OLAP分析引擎Kylin对Parquet存储的支持以及使用Spark构建cube的技术细节。文档涵盖了架构设计、选择Parquet的原因、cube构建与查询流程、性能表现以及现场演示等内容。"
Apache Kylin是一个高效的大数据OLAP引擎,最初设计时使用Hive作为元数据存储,Hadoop MapReduce作为计算引擎,而数据存储在HBase中。然而,随着大数据技术的发展,Kylin引入了对Parquet的支持,这是一种列式存储格式,能够提供更好的性能和效率。
**Parquet的优势**
1. **分布式查询执行**: Kylin on Parquet实现了分布式查询执行,降低了单一故障点的问题,提升了系统的可用性和扩展性。
2. **调试友好**: 使用Spark作为引擎后,可以通过DataFrame添加断点进行调试,使得问题定位更为便捷。
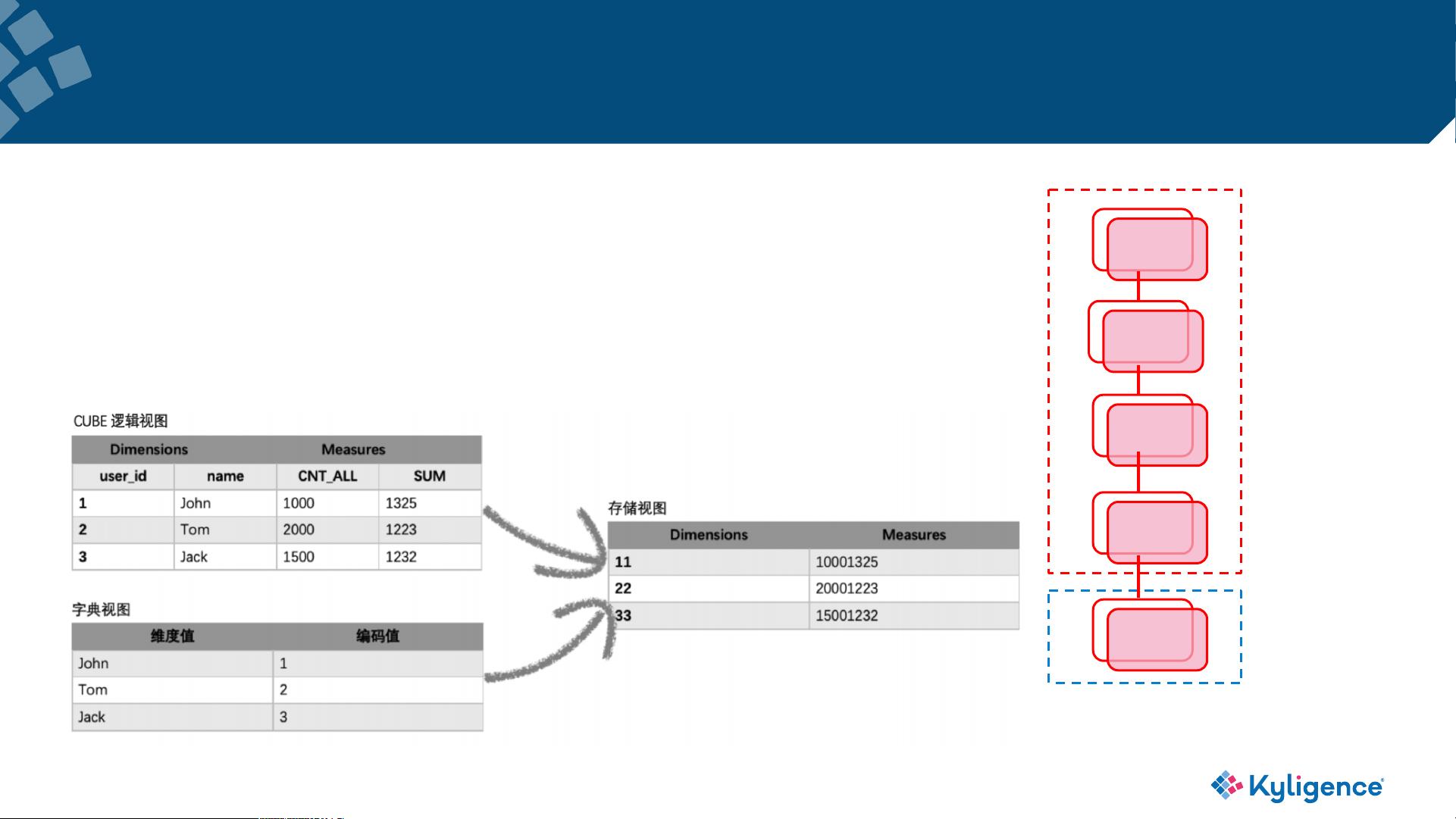
3. **真正的列式存储**: Parquet是一种列式存储格式,对于分析查询来说,可以显著提高读取速度,因为列式存储只需读取所需列的数据,而非整个行。
4. **操作维护简单**: 相比于HBase,Parquet的管理和操作更加简便,更适用于大数据分析场景。
**Kylin on Parquet的架构变化**
1. **插件化设计**: Kylin引入Parquet并不意味着完全摒弃原有架构,而是采用了插件化设计,允许用户根据需求选择不同的存储和计算引擎。
2. **Spark引擎**: 采用Spark替代MapReduce作为cube构建的计算引擎,Spark提供了更强大的计算能力,同时具备良好的交互性和易用性。
3. **REST服务器和SQL路由**: 通过REST API和SQL接口,Kylin提供了一种统一的方式来处理来自各种3rd Party应用(如Webapp,移动应用)的查询请求。
**Cubebuild&Query流程**
1. **Cube构建**: Kylin使用预计算技术创建多维立方体,以加速查询。在Parquet支持下,这一过程可能更快,因为Spark可以并行处理大量数据。
2. **查询处理**: 用户通过SQL语句发起查询,Kylin解析SQL并生成执行计划,利用Parquet的列式存储优势进行快速过滤、投影和聚合操作。
**性能提升**
1. **查询性能**: 列式存储的Parquet和Spark的组合大大提高了查询速度,尤其对于分析型查询,减少了I/O操作,提高了数据处理效率。
2. **运维成本**: 由于Parquet的易管理和Spark的可调试性,运维成本相对降低,使得整体系统更加健壮。
Kylin on Parquet的引入旨在解决Kylin在HBase上的局限性,通过引入Spark和Parquet,提供了更好的查询性能、易用性和可扩展性,满足大数据场景下快速分析的需求。同时,这种架构变化也为开发者和管理员带来了更友好的开发和维护体验。
7
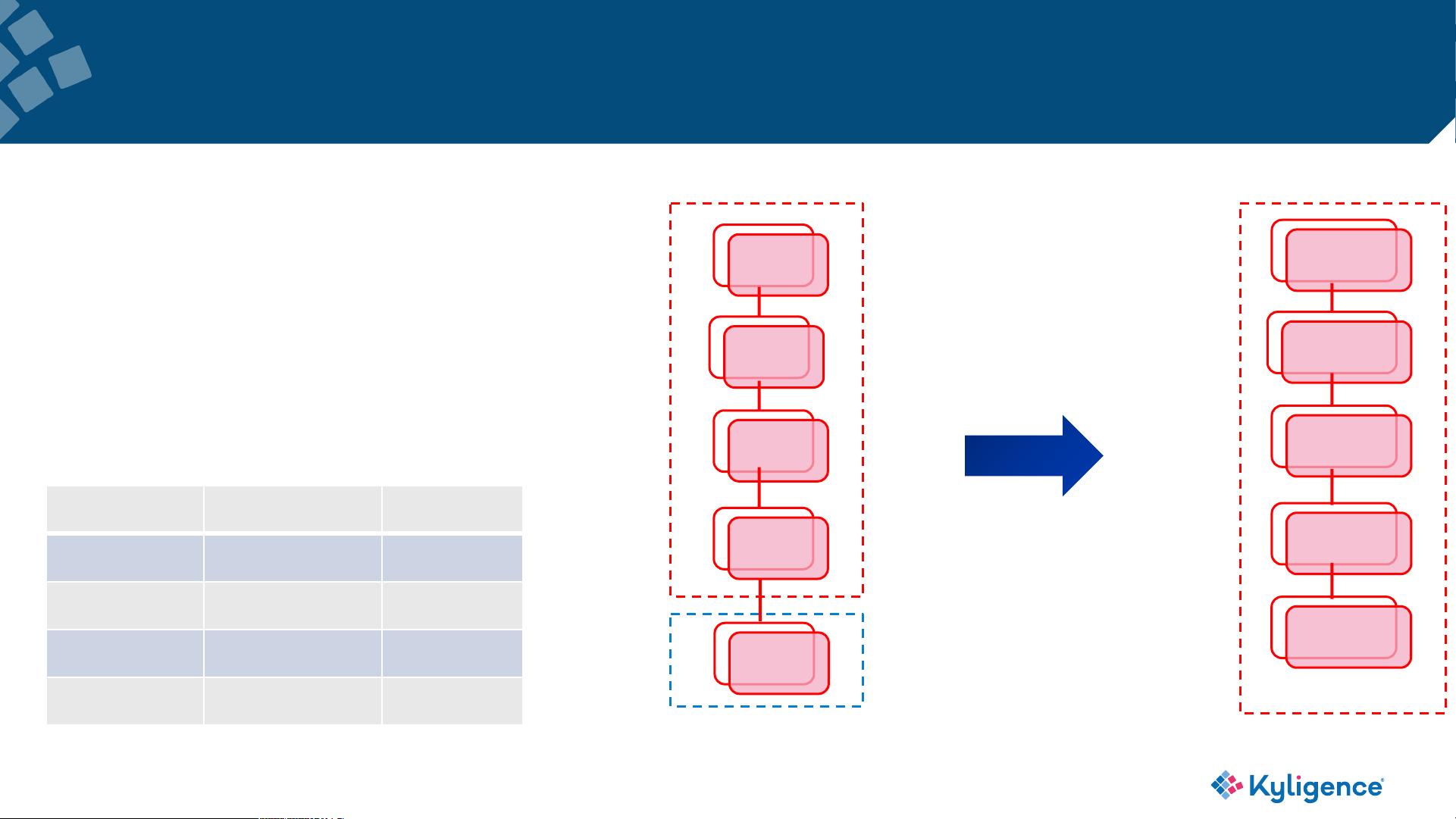
Kylin on HBase - Limitations
• Kylin Query engine has a single point problem
• The code generated by Calcite is hard to debug
• HBase is KV, not a real columnar storage
• HBase operation and maintenance is difficult to do
Cube
Filter
Project
Agg
Sort
Single
(Calcite)
Distributed
Coprocessor
剩余37页未读,继续阅读
2017-08-14 上传
2020-05-12 上传
2019-12-05 上传
2019-11-18 上传
2019-04-07 上传
2021-05-09 上传
2021-10-14 上传
2019-11-07 上传

Wu_San
- 粉丝: 4
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
