Spark支持下的十亿级特征大规模机器学习优化与应用
需积分: 5 140 浏览量
更新于2024-06-21
收藏 2.4MB PDF 举报
《藏经阁:基于Spark的面向十亿级别特征的大型机器学习》是由Yanbo Liang撰写的一篇论文,主要关注在大规模数据集和复杂模型背景下,利用Apache Spark进行高效机器学习处理。Spark是一个广泛应用于大数据处理的分布式计算框架,其在处理海量特征和执行大规模优化算法上具有显著优势。
论文首先介绍了背景,强调了在大数据时代,大数据与复杂的机器学习模型相结合可以提高预测精度。CRTPipeline(Click-Through Rate Pipeline)是论文的核心,它涉及一系列关键步骤,包括特征选择、上下文广告影响、用户特征转换、特征编码以及模型训练与评估。
在技术细节部分,作者重点讨论了:
1. **Vector-free L-BFGS on Spark**:这是一种无向量化的L-BFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)优化方法,通过Spark并行化实现了对大规模数据集的有效处理,避免了传统向量存储带来的内存挑战。
2. **Logistic regression on vector-free L-BFGS**:在Spark环境下,作者优化了逻辑回归模型,采用无向量化优化技术,提高了模型训练效率。
3. **Performance evaluation**:论文深入比较了不同机器学习算法在Spark上的性能,包括线性回归(LR)、随机梯度下降/拟牛顿法(SGD/LBFGS)、Follow the Regularized Leader(FTRL)在线学习算法,以及Factorization Machines (FM)、Gradient Boosting Trees (GBT)、深度神经网络 (DNN) 和集成学习方法。
4. **State-of-the-art solutions**:文中提到,目前最先进的解决方案是结合GBDT(Gradient Boosting Decision Trees)和LR,以及DNN与LR的组合,这些在Spark平台上都得到了优化。
5. **Large-scale optimization algorithms**:论文探讨了几种大规模优化算法的实现策略,如MPI同步、Spark同步和参数服务器异步,以适应Spark的分布式计算环境。
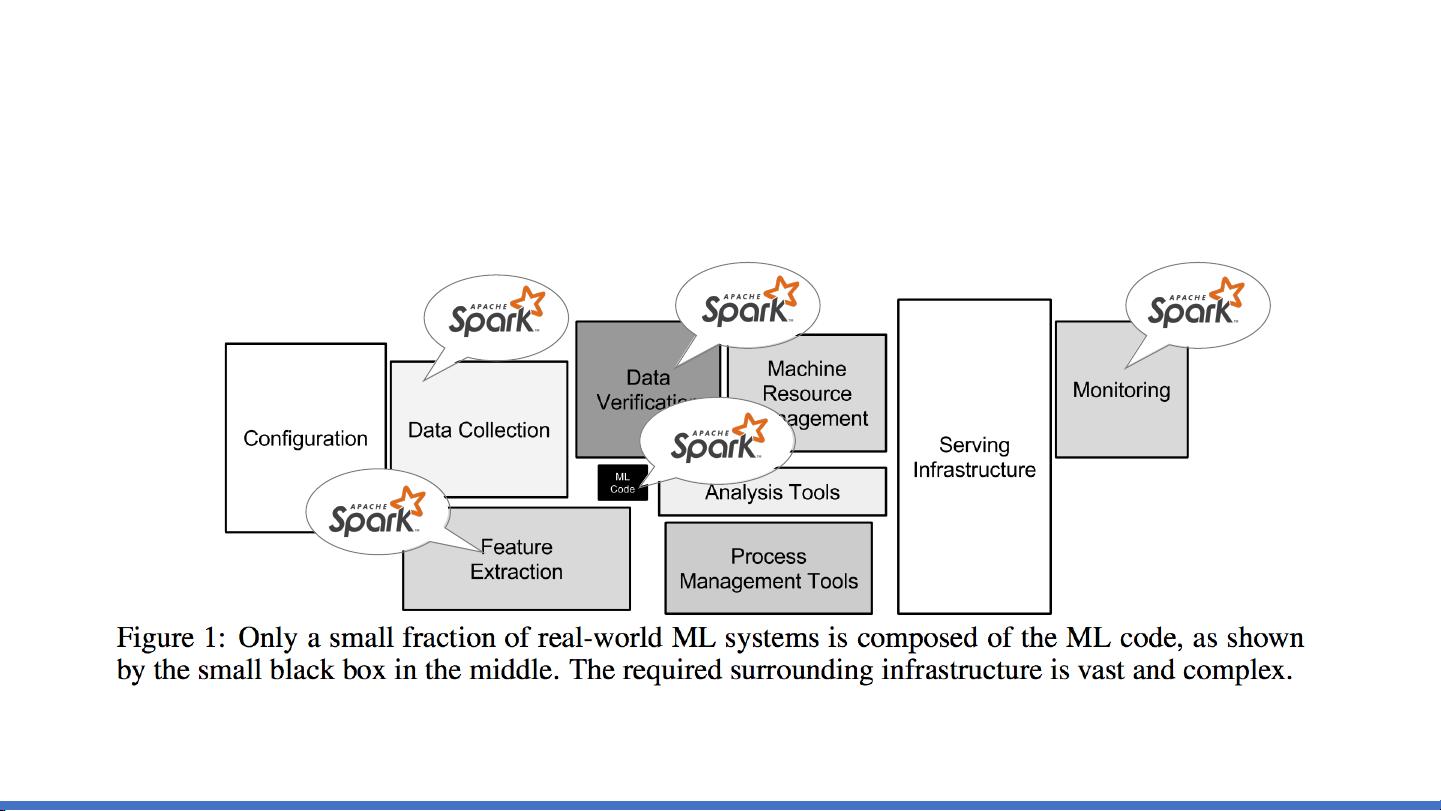
6. **Spark作为一个统一平台**:Spark的统一性使得开发者能够方便地集成现有的MLlib库,同时降低了隐藏的技术债务。
7. **实验与实践应用**:文章还分享了实验结果,展示如何将这些技术应用于实时的在线CTR服务,并进行了特征校准,以提高CTR模型的准确性。
《藏经阁:基于Spark的面向十亿级别特征的大型机器学习》提供了在大数据场景下,如何有效利用Spark进行特征工程、模型训练和优化的重要实践指南,对于理解和应用Spark在大规模机器学习中的作用具有很高的参考价值。

Large-scale optimization
• MPI - Sync
• Spark - Sync
• Parameter Server - Async
剩余44页未读,继续阅读
2019-08-20 上传
2023-09-10 上传
2023-09-09 上传
2023-09-11 上传
2023-08-26 上传
2023-08-26 上传

weixin_40191861_zj
- 粉丝: 83
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
