Hadoop分布式数据分析系统设计与实现
版权申诉
105 浏览量
更新于2024-06-18
收藏 5.76MB PDF 举报
"基于Hadoop数据分析系统设计毕业论文"
这篇毕业论文详细探讨了如何设计和实施一个基于Hadoop的数据分析系统,以解决特定企业面临的大规模日志数据分析问题。Hadoop作为一个开源的分布式计算平台,其核心包括Hadoop分布式文件系统(HDFS)和MapReduce编程模型,这两部分为用户提供了强大的数据存储和处理能力。
HDFS是Hadoop的基础,它具有高容错性和高伸缩性,使得用户能够在低成本的硬件上构建分布式系统。通过HDFS,大量数据可以被分布式存储,确保了系统的稳定性和数据的可靠性。MapReduce则是一种并行处理模型,它简化了开发者编写大规模数据处理程序的难度,无需深入理解分布式系统底层的工作机制。
在论文的第三章,作者介绍了Hadoop的部署过程,包括单一节点部署和集群部署。集群部署中,详细列出了集群部署的拓扑图,以及安装CentOS操作系统、配置SSH免密码登录、安装JDK和Hadoop的步骤。对于32位和64位Hadoop的安装进行了区分,以适应不同的硬件环境。此外,还讨论了Hadoop的优化措施,以提升系统性能。
Hive作为数据仓库工具,被引入到Hadoop生态系统中,用于提供SQL-like查询功能。论文中介绍了如何安装Hive,使用MySQL作为元数据存储,并演示了Hive的基本使用方法。HBase,作为NoSQL数据库,适合处理大规模的非结构化数据。论文也涵盖了HBase的安装和使用,强调了其在大数据分析中的作用。
为了监控Hadoop集群的运行状况,论文提到了Ganglia这一监控工具,它能提供实时性能指标,帮助管理员检测和诊断集群的问题。在第四章,作者讲解了如何使用Cobbler和Ambari进行Hadoop集群的批量部署,这大大提高了部署效率。
第五章中,作者详细阐述了如何利用Hadoop分析日志数据,包括数据预处理、数据清洗和数据分析等步骤,展示了Hadoop在日志分析中的实际应用。最后,第六章总结了整个项目的设计和实现,第七章列出了参考文献,感谢了相关人员。
这篇论文全面覆盖了Hadoop系统的设计、部署、配置和优化,为企业解决大数据分析问题提供了实用的指导。通过这个案例,读者可以学习到如何构建一个能够处理海量日志数据的分布式系统,以提高数据处理效率和系统稳定性。
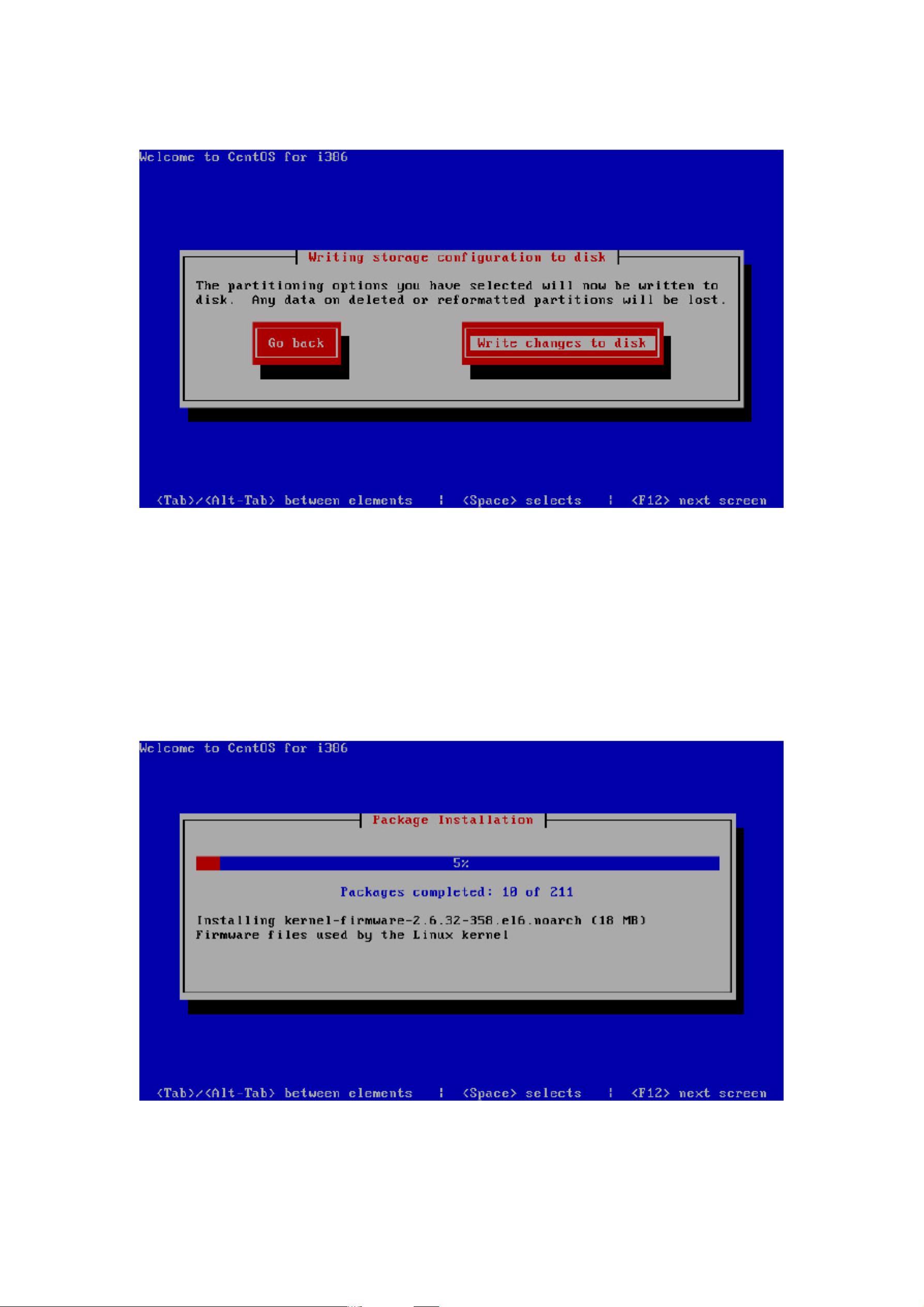
确认写入磁盘,下一步,如图 3.11 所示。
图 3.11 确认格式化磁盘界面
11) 开始写入系统文件,100%即为完成写系统操作,如图 3.12 所示。
图 3.12 操作系统安装界面
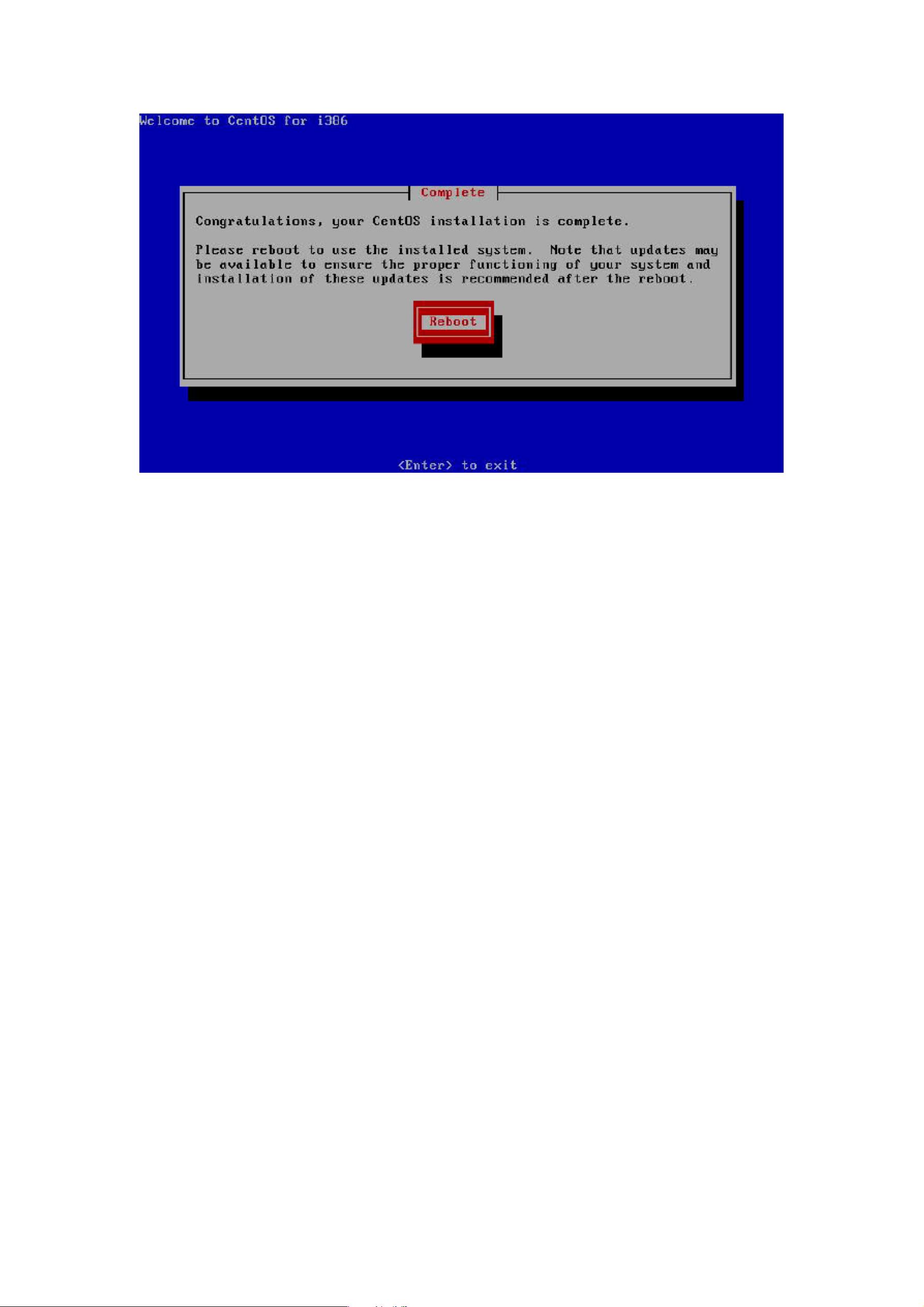
12) 重启,进入系统,如图 3.13 所示。

剩余68页未读,继续阅读
2022-07-07 上传
2022-11-02 上传
2023-08-07 上传
2023-08-06 上传
143 浏览量

Rocky006
- 粉丝: 8372
- 资源: 1339
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
