Java实现协同过滤推荐算法及阿里云竞赛解析
版权申诉
180 浏览量
更新于2024-07-08
收藏 275KB PDF 举报
"协同过滤推荐算法的Java原生JDK实现,附带源码地址,主要涉及基于用户和商品的个性化推荐模型构建。"
协同过滤推荐算法是一种广泛应用于个性化推荐系统的方法,它主要分为用户-用户协同过滤和物品-物品协同过滤两种。此算法的核心思想是基于用户的历史行为数据,找出具有相似兴趣或喜好的用户或物品,然后为用户推荐他们可能感兴趣但尚未接触过的物品。
在Java中实现协同过滤推荐,首先需要对给定的数据进行预处理。根据描述中的数据说明,数据集包含用户行为数据(浏览、收藏、加购物车、购买)以及商品信息,其中用户标识(user_id)、商品标识(item_id)、行为类型(behavior_type)和时间(time)等是关键字段。为了构建模型,我们需要处理这些数据,例如:
1. 数据清洗:去除无效或空值,统一数据格式。
2. 数据转换:将行为类型编码,便于后续计算。
3. 用户-商品交互矩阵构建:以用户为行,商品为列,行为类型作为值,记录用户对商品的行为。
接着,我们可以通过以下步骤实现协同过滤:
1. **相似度计算**:计算用户之间的相似度(如余弦相似度、皮尔逊相关系数)或者商品之间的相似度。对于用户-用户协同过滤,可以基于共同评价的商品计算;对于物品-物品协同过滤,则基于被相似用户共同购买的商品。
2. **预测评分**:为每个用户预测对未评价商品的评分,这通常是通过相似用户对目标商品的平均评分或者相似商品的平均评分来计算。
3. **推荐生成**:根据预测评分,选取评分最高的若干个商品作为推荐。
在实际业务场景中,除了基础的协同过滤,还可以结合其他策略,如矩阵分解(如SVD)、深度学习方法(如NeuMF)来提升推荐效果。此外,考虑时间衰减、冷启动问题、稀疏性等因素也是优化推荐系统的关键。
提供的源码地址可能包含完整的实现过程,包括数据读取、预处理、相似度计算、评分预测以及推荐列表生成等步骤。通过分析和理解这些代码,开发者可以深入了解协同过滤推荐算法的工作原理,并将其应用到自己的项目中。
最后,比赛的目标是利用训练数据建立推荐模型,并预测用户在商品子集的购买行为。评分数据的计算公式会基于预测结果与真实购买数据的比较,通常采用准确率、召回率、F1分数等指标来评估模型性能。
协同过滤推荐算法的Java实现涉及到数据处理、相似度计算、预测评分和推荐生成等多个环节,理解并掌握这些知识点有助于构建一个有效的个性化推荐系统。
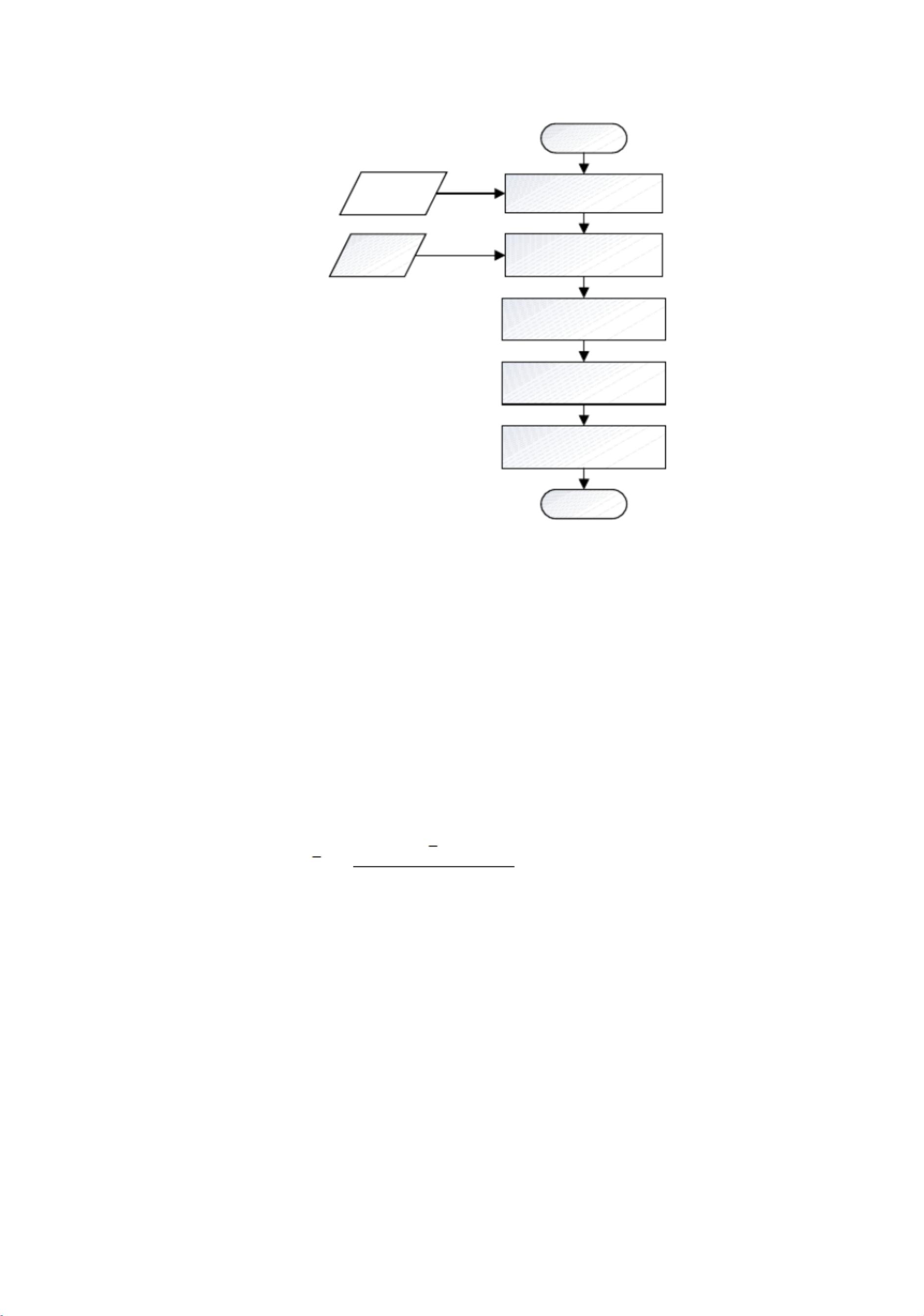
开始
得到目标用户访问过的项目
集合 Icol(u)
项目评分
矩阵
计算集合 Icol(u)中每个项目与
其他项目相似度
选择相似度最高的 k个项目作
为候选集合
计算候选集中所有项目的预测
评分
结束
推荐预测评分最高的 N个项目
输入 k值
图 2 基于项目的协同过滤推荐算法流程
基于项目的协同过滤推荐算法流程为:
首先,读取目标用户的评分记录集合 I
??
;然后计算项目 i 与I
??
中其他项目
的相似度,选取 k 个最近邻居;根据评分相似度计算公式计算候选集中所有
项目的预测评分;最后选取预测评分最高的 N 个项目推荐给用户。
基于项目的协同过滤推荐算法预测评分与其他用户评分的加权评分值相
关,不同的历史评分项目与当前项目 i 的相关度有差异,所以在进行计算时,
不同的项目有不同的权重。评分预测函数 p(u,i),以项目相似度作为项目的
权重因子,得到的评分公式如下:
p(u,i)= ??
??
+
(??
??,??
- ??
??
) × sim(i,j)
??∈ ??
??
|sim (i,j)|
??∈ ??
??
(2)
基于项目的协同过滤推荐算法实现步骤为:
实时统计 user对 item 的打分,从而生成 user-item
表(即构建用户 -项目评分矩阵);
计算各个 item 之间的相似度,从而生成 item-item
的得分表,并进行排序;
对每一 user的 item 集合排序;
针对预推荐的 user,在该用户已选择的 item 集合
剩余22页未读,继续阅读
2022-05-30 上传
点击了解资源详情
2023-11-07 上传
2023-07-17 上传
2010-02-07 上传
135 浏览量
207 浏览量

普通网友
- 粉丝: 4
- 资源: 10万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 周立功 RS485通讯 51单片机
- 网络编程 Web编程
- MC9S08AC60单片机数据手册(英文)
- java2d教材 .
- C#完全手册.pdf
- CRC算法原理及C语言实现.pdf
- BGP.Internet.Routing.Architectures.2nd.Edition.2000
- S3C44B0试验配置
- 自地球诞生以来最全的C语言笔试面试题!将近有250页的word文档!
- VC&MFC讲解教材
- 高质量C-C++编程指南
- XMPP核心(PDF)
- struts入门详解(初学者)
- 索尼(SONY)DSR-190P 数码摄像机说明书
- 学习ASP.NET的最优顺序(好的计划等于效率的提高)
- 关于智能手机的学习资料《智能手机》
