SQL Server表与索引存储结构详解:提升查询速度的关键
需积分: 46 199 浏览量
更新于2024-09-08
收藏 208KB DOCX 举报
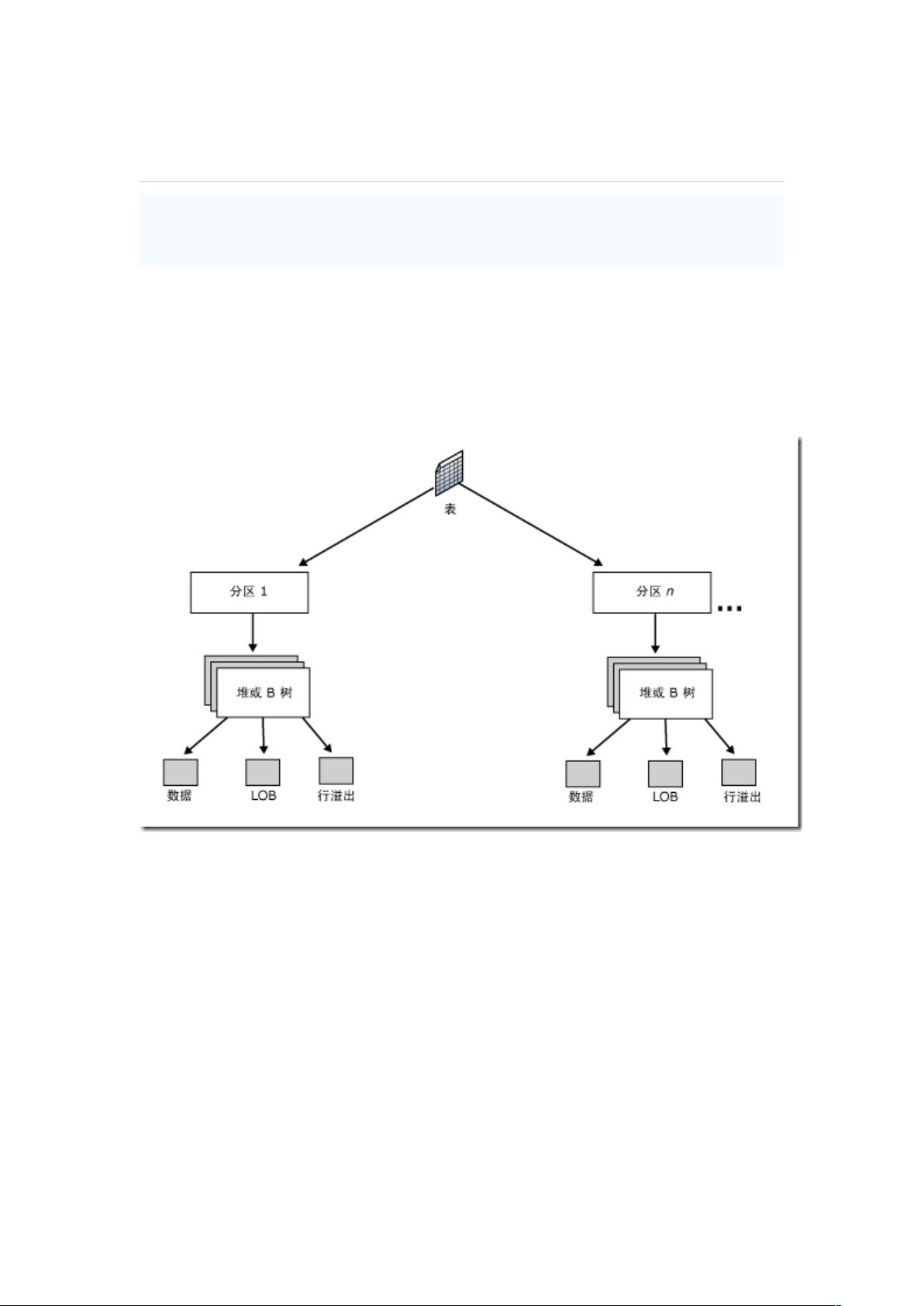
本文详细解析了SQL Server中表和索引存储结构的关键要点,帮助读者深入了解数据库管理和性能优化。首先,SQL Server中的每个表都有一个唯一的对象ID,其存储组织基于分区,每个分区可以是堆(无聚集索引)或B树(通常用于聚集索引)。堆由一个或多个预留的堆或B树组成,每个结构包含三个分配单元:数据、LOB(大型对象)和行溢出,其中数据分配单元最为常用。
对于堆结构,数据存储在无序的数据页中,这些页通过IAM(Index Allocation Map)页进行逻辑管理。IAM页描述了每个分区的数据分布情况,而堆中的数据页之间仅依赖IAM页中的信息进行逻辑连接。
非聚集索引的表则不同,每个非聚集索引对应一个分区,数据页之间通过前后指针形成一个树形结构。根页指向数据的实际存储位置,即以堆形式存在的物理页。这种设计允许快速查找,但查找过程涉及两次I/O操作:一次找到索引页,一次定位到数据页。
聚集索引是最具代表性的,其索引号为1,与之关联的分区下的分配单元直接指向根页。聚集索引的叶子节点存储实际数据,这意味着在查询时,可以直接定位到所需数据,大大提高了搜索速度。此外,聚集索引通常作为主键使用,因为它们提供了唯一标识和高效的排序能力。
理解这些存储结构对于优化SQL Server查询性能至关重要,包括选择合适的索引策略、调整分区大小以及管理大型数据类型。通过合理设计和维护表和索引,可以显著提升数据库性能,确保应用程序的高效运行。
详解 SQL Server 表和索引存储结构
这篇文章主要介绍了详解 SQL Server 表和索引存储结构,有助于大家对 SQL 存储方式有
深入的理解,参考学习下吧。
本文详细分析了 SQL Server 中表和索引结构存储的原理以及对于如何加快搜索速度和提
高效率等方面做了详细的分析,以下是主要内容。
下图显示了表的存储组织,每张表有一个对应的对象 ID,并且包含一个或多个分区,每个
分区会有一个堆或者多个 B 树,堆或者 B 树的结构是预留的。每个堆或者是 B 树都有三个
分配单元用来存放数据,分别是数据、LOB、行溢出,使用最多的分配单元是数据。如果
有 LOB 数据或者是长度超过 8000 字节的记录,则可能有另外的 LOB 分配单元和行溢出
分配单元。
小总结: 一个表可以有多个分区,但是每个分区(堆/B 树)最多有三个分配单元,每个分
配单元可以有很多页,对于每个分配单元内的数据页,根据表是否有索引,以及索引是聚
集还是非聚集,组织方式有以下三种:
1. 堆
所谓堆(heap),就是不含聚集索引的表。堆的 sys.partitions 中具有一行,对于堆使用
的每个分区,都有 index_id= 0。只有一个分区,在系统表里,对于这个分区下面的每
个分配单元都有一个连接指向 Index Allocation Map 页(IAM),在 IAM 页里,描述了区
的信息。
sys.system_internals_allocation_units系统视图中的列 %rst_iam_page指向管理特
定分区中堆的分配空间的一系列 IAM 页的第一页。SQL Server 使用 IAM 页在堆中移动。
堆内的数据页和行没有任何特定的顺序,也不链接在一起。数据页之间唯一的逻辑连接是
记录在 IAM 页内的信息。
下载后可阅读完整内容,剩余6页未读,立即下载
2020-09-10 上传
点击了解资源详情
点击了解资源详情
2020-12-15 上传
2012-05-24 上传
点击了解资源详情
点击了解资源详情

taozuibar
- 粉丝: 0
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
