Transformer与问答:Thang Luong详解Transformer网络与应用
需积分: 10 26 浏览量
更新于2024-07-17
收藏 9.04MB PDF 举报
Transformer网络是深度学习在自然语言处理(NLP)领域的一项重要突破,由谷歌大脑的研究科学家Thang Luong介绍。该模型最初在2017年Google内部会议上由Jeff Dean和Quoc Le提出,旨在解决传统的递归神经网络(RNNs)在处理长距离依赖问题时的效率低下。Transformer网络的核心在于自注意力机制(Self-attention),这是一种全新的关注机制,使得模型能够并行处理所有输入元素,显著提高了计算效率。
Transformer由多个层级组成,每个层级包含多个注意力头(Attention Heads),每个头负责学习输入序列中不同关系的表示。输入首先被转换为向量,然后通过这些层级逐层传递,每一层的输出作为下一层的输入。这种设计允许模型在没有循环结构的情况下捕捉全局上下文信息,这是其与RNNs的主要区别。
在Question Answering任务中,如BiDAF(Bidirectional Attention Flow)和QANet(Question-Answer Network),Transformer的应用尤为突出。这些模型利用Transformer架构来理解问题与文本段落之间的交互,从而找出与问题最相关的答案片段。例如,Thang Luong在VietAIFoundationClass4中提到的BERT(Bidirectional Encoder Representations from Transformers)和XLNet(eXtra Longformer)就是基于Transformer的预训练模型,它们在大规模数据上进行自我监督学习,然后在各种NLP任务上表现出色。
Transformer的出现引领了深度学习在NLP领域的革新,不仅提升了机器理解和生成文本的能力,也促进了诸如机器翻译、问答系统和文本生成等任务的显著进步。相比于之前的方法,Transformer由于其并行性和对长序列的有效处理,已经成为现代NLP模型的标准组成部分。此外,像OpenAI的GPT-2这样的后续工作进一步扩大了Transformer的影响,展示了其在生成式语言模型中的巨大潜力。
总结来说,Transformer网络凭借其独特的自注意力机制和高效架构,彻底改变了我们处理自然语言的方式,并在众多NLP应用中展现出前所未有的性能。对于任何希望深入理解自然语言处理和深度学习的人来说,学习Transformer的工作原理以及它在实际问题中的应用是至关重要的。
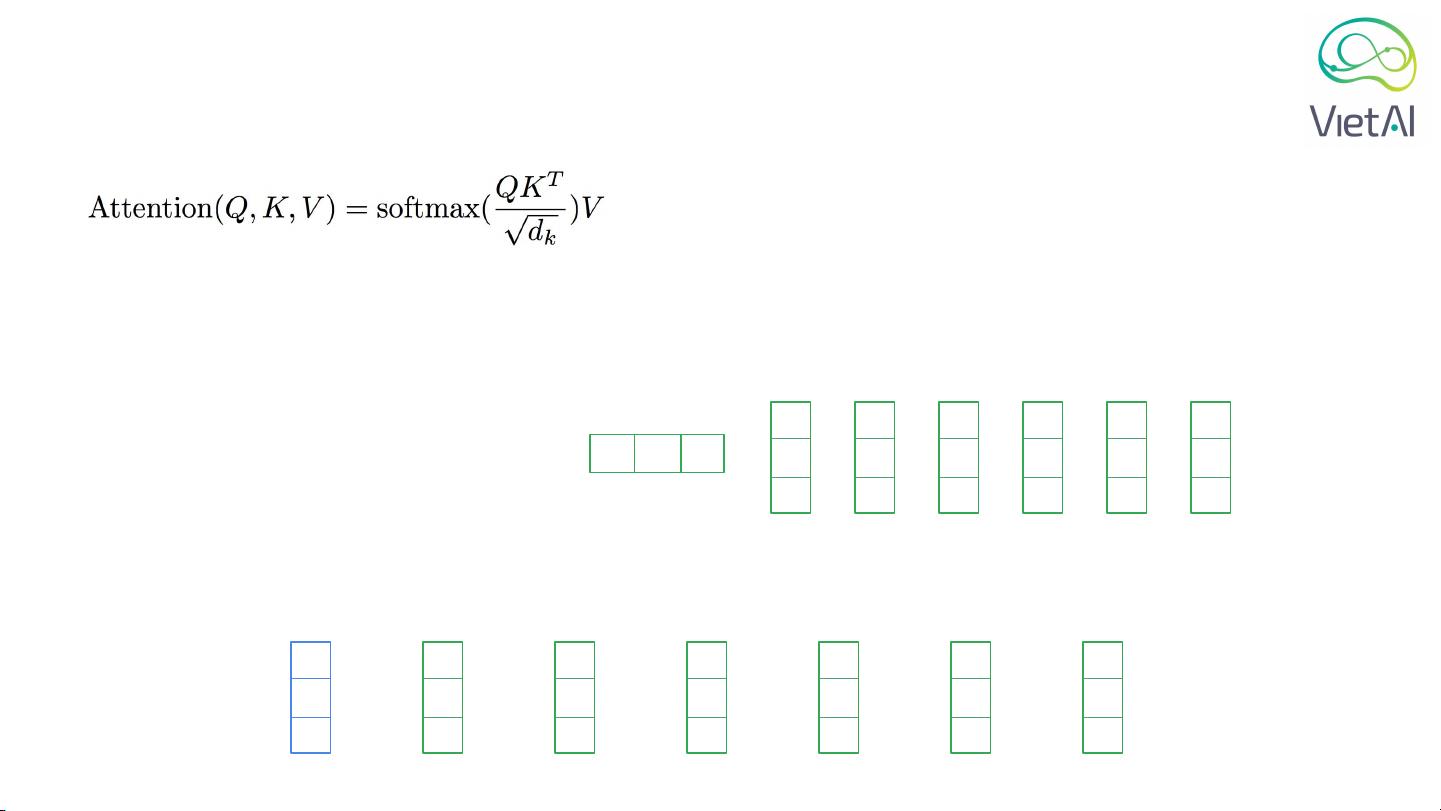
VietAI Foundation Class 4 - Thang Luong - QA, Transformer, BERT, XLNet
Self-aention
13
1.0
0.5
1.2
=
0.6
0.2
0.8
Apple
0.2
0.3
0.1
is
0.9
0.1
0.8
good
0.3
0.1
0.4
for
0.4
0.1
0.2
your
0.5
0.3
0.7
health
w
1
w
2
w
3
w
4
w
5
w
6
+ + + + +
Values V
0.6
0.2
0.8
Apple
0.2
0.3
0.1
is
0.9
0.1
0.8
good
0.3
0.1
0.4
for
0.4
0.1
0.2
your
0.5
0.3
0.7
health
w
1
, w
2
, w
3
, w
4
, w
5
, w
6
= somax ( , )
Apple
0.6 0.2 0.8
Query Q
Keys K
Scaled factor = sq(hidden size)


剩余75页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-12-12 上传
2022-04-07 上传
595 浏览量
2022-01-10 上传
2022-01-28 上传
2019-09-16 上传

tiance_0301
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







