Python3 BeautifulSoup4 安装教程与高效数据抓取
PDF格式 | 106KB |
更新于2024-08-30
| 137 浏览量 | 举报
BeautifulSoup4是Python中一个广泛使用的HTML和XML解析库,专为网页数据抓取和分析而设计。它的核心功能在于提供一种简洁的方式来解析、搜索和修改HTML或XML文档,使得开发者能够方便地从复杂页面中提取所需的信息。BeautifulSoup具有以下显著特点:
1. **Pythonic API与方法**:
BeautifulSoup封装了底层解析器的复杂性,提供了易于理解的接口,如遍历解析树、查找特定元素、提取属性等,使开发者能够像操作Python对象一样处理网页内容。
2. **编码处理**:
它自动将HTML文本转换为稳定的Unicode编码,并默认使用UTF-8进行输出。这样避免了编码问题,除非遇到未指定编码的文档,此时只需明确指定原始编码即可。
3. **灵活性与兼容性**:
BeautifulSoup建立在诸如lxml和html5lib等流行Python解析器之上,允许用户选择不同解析器,以权衡速度和性能。例如,lxml由于其C语言实现,通常解析速度更快,但可能需要额外的安装步骤;而Python标准库则提供更稳定但相对较慢的解析。
**安装配置步骤**:
- BeautifulSoup4可以通过包管理工具pip进行安装,命令行输入`pip install beautifulsoup4`或`easy_install beautifulsoup4`。
- 如果选择下载源码包,可以从Crummy Software的网站获取,解压后运行`python setup.py install`进行安装。
4. **解析器的选择**:
- BeautifulSoup支持Python标准库的HTML和XML解析器,如`BeautifulSoup(markup, "html.parser")`,虽然速度较慢但文档处理能力强,特别适合Python早期版本。
- lxml解析器提供了更快的速度,特别是对于HTML,但需要额外安装lxml库,且可能需要C语言环境支持。
BeautifulSoup4是Python数据抓取和网页解析的强大工具,无论是为了快速提取网页内容还是处理复杂的HTML结构,都能有效简化开发过程。通过灵活选择解析器和利用其丰富的API,开发者可以高效地完成各种网络爬虫和数据分析任务。
python3解析库解析库BeautifulSoup4的安装配置与基本用法的安装配置与基本用法
前言前言
Beautiful Soup是python的一个HTML或XML的解析库,我们可以用它来方便的从网页中提取数据,它拥有强大的API和多样的
解析方式。
Beautiful Soup的三个特点:的三个特点:
Beautiful Soup提供一些简单的方法和python式函数,用于浏览,搜索和修改解析树,它是一个工具箱,通过解析文档为用户
提供需要抓取的数据
Beautiful Soup自动将转入稳定转换为Unicode编码,输出文档转换为UTF-8编码,不需要考虑编码,除非文档没有指定编码方
式,这时只需要指定原始编码即可
Beautiful Soup位于流行的Python解析器(如lxml和html5lib)之上,允许您尝试不同的解析策略或交易速度以获得灵活性。
1、、Beautiful Soup4的安装配置的安装配置
Beautiful Soup4通过PyPi发布,所以可以通过系统管理包工具安装,包名字为beautifulsoup4
$easy_install beautifulsoup4
或者
$pip install beautifulsoup4
也可用通过下载源码包来安装:
#wget https://www.crummy.com/software/BeautifulSoup/bs4/download/4.0/beautifulsoup4-4.1.0.tar.gz
#tar xf beautifulsoup4-4.1.0.tar.gz
#cd beautifulsoup4
#python setup.py install
Beautiful Soup在解析时实际上是依赖解析器的,它除了支持python标准库中的HTML解析器外还支持第三方解析器如lxml
Beautiful Soup支持的解析器,以及它们的优缺点:
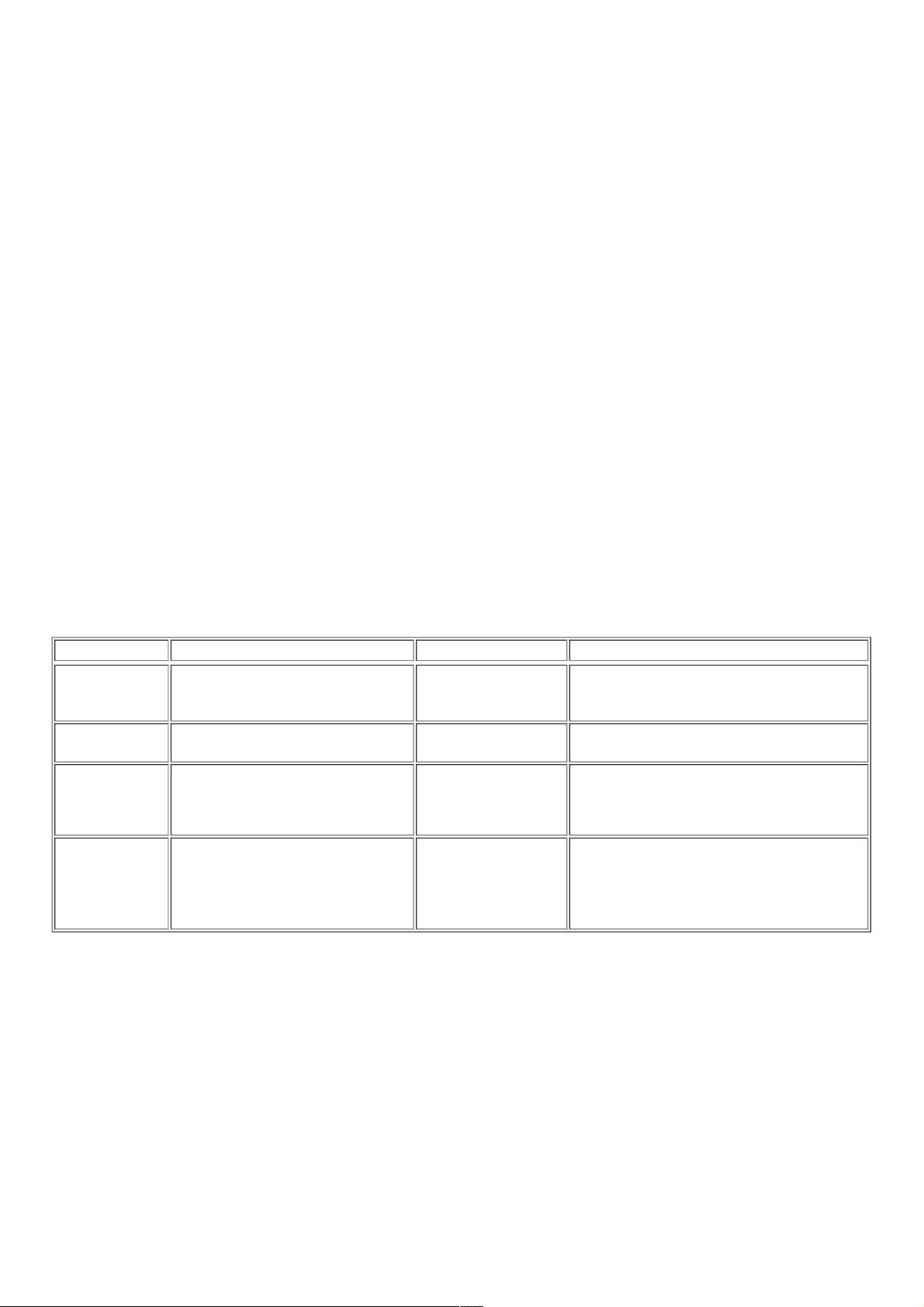
解析器解析器 使用方法使用方法 优势优势 劣势劣势
Python标准库 BeautifulSoup(markup,”html.parser”)
Python的内置标准库
执行速度适中
文档容错能力强
Python 2.7.3 or 3.2.2)前 的版本中文档容错能
力差
lxml HTML 解析
器
BeautifulSoup(markup,”lxml”)
速度快
文档容错能力强
需要安装C语言库
lxml XML 解析器
BeautifulSoup(markup,
[“lxml”, “xml”])
BeautifulSoup(markup,”xml”)
速度快
唯一支持XML的解析
器
需要安装C语言库
html5lib BeautifulSoup(markup,”html5lib”)
最好的容错性
以浏览器的方式解析
文档
生成HTML5格式的文
档
速度慢
不依赖外部扩展
安装解析器:
$pip install lxml
$pip install html5lib
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为
那些Python版本的标准库中内置的HTML解析方法不够稳定
2、、BeautifulSoup的基本用法的基本用法
通过传入一段字符或一个文件句柄,BeautifulSoup的构造方法就能得到一个文档的对象,选择合适的解析器来解析文档,如
手动指定将选择指定的解析器来解析文档,Beautiful Soup将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是
python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment
注意:注意:BeautifulSoup版本4的包是在bs4中引入的
from bs4 import BeautifulSoup
下载后可阅读完整内容,剩余6页未读,立即下载
相关推荐

1456 浏览量



weixin_38743481
- 粉丝: 698
 我的内容管理
展开
我的内容管理
展开







最新资源
- LineControl:轻量级HTML5文本编辑器JQuery插件
- FusionCharts导出功能核心组件介绍
- Vuforia AR教程:构建应用程序的入门指南
- 探索SwiftBySundell:代码示例与Swift学习资源
- 宠物定时喂食器设计原理与应用解析
- 提升PDF处理效率的工具推荐
- ASP.NET在线投票系统实现与数据库使用教程
- 利用回溯算法深入解决组合问题
- easyUI datagrid工程项目实战:增删查改与布局管理
- Qt官方文档汉化版:中文帮助文档完整翻译
- 物业公司专属蓝色风格网站模板设计教程
- 一键配置Hbase的压缩文件包下载
- ZeroBranePackage:ZeroBrane Studio集成的开源软件包
- CSerialPort类在VS2008中的应用及ComTool工具
- 个性化dotfiles配置及其自动化部署工具
- 成功试验USB转串口驱动,助力屏幕电脑应用
