TensorFlow入门:文本分类实战与TensorBoard应用
105 浏览量
更新于2024-09-01
收藏 224KB PDF 举报
本文档是一篇关于TensorFlow学习教程的深度分析,特别关注于文本分类技术在深度学习框架中的应用。作者结合自己的实践经历,分享了如何利用TensorFlow进行文本数据处理和分类的学习过程。TensorFlow是一个强大的开源机器学习库,以其易读性、跨平台支持、高效计算能力和活跃的社区而著称。
文章首先简述了TensorFlow的特点,包括使用Python编程、支持CPU和GPU并行计算、编译效率高、以及图形化工具TensorBoard的运用,这使得模型构建和可视化变得直观。TensorFlow的核心运作流程包括两个步骤:模型构建和模型训练。模型构建阶段通过定义计算图描述模型结构,而实际计算则在Session.run()函数中执行。
文本分类部分是本文的重点。作者通过示例展示了如何进行文本预处理,如使用Pandas和NumPy库加载和操作数据,以及从sklearn库导入新闻组数据集。函数`get_word_2_index`用于创建词汇到索引的映射,这是向量化文本数据的关键步骤,便于模型处理。`get_batch`函数用于将数据划分为小批量,便于训练过程中的迭代。
接下来,作者给出了一个基础的文本分类模型的代码,其中涉及到的数据预处理、词嵌入(可能使用的是词袋模型或更高级的词嵌入方法,如Word2Vec或GloVe)、模型参数设置(如使用TensorFlow的Dense层)以及训练循环。在这个过程中,可能会用到TensorFlow的`tf.placeholder`和`tf.nn.softmax`等核心函数,以及损失函数和优化器的选择,如交叉熵损失和Adam优化器。
这篇教程旨在帮助初学者理解如何使用TensorFlow进行文本分类任务,包括数据预处理、模型构建和训练的基本流程。读者可以借此学习如何将自然语言处理技术与深度学习结合起来,解决实际问题。同时,文中提到的工具和库选择对于理解TensorFlow在实际项目中的应用具有重要意义。
tensorflow学习教程之文本分类详析学习教程之文本分类详析
初学tensorflow,借鉴了很多别人的经验,参考博客对评论分类(感谢博主的一系列好文),本人也尝试着实现了
对文本数据的分类,下面这篇文章主要给大家介绍了关于tensorflow学习教程之文本分类的相关资料,需要的朋
友可以参考下
前言前言
这几天caffe2发布了,支持移动端,我理解是类似单片机的物联网吧应该不是手机之类的,试想iphone7跑CNN,画面太美~
作为一个刚入坑的,甚至还没入坑的人,咱们还是老实研究下tensorflow吧,虽然它没有caffe好上手。tensorflow的特点我就
不介绍了:
基于Python,写的很快并且具有可读性。
支持CPU和GPU,在多GPU系统上的运行更为顺畅。
代码编译效率较高。
社区发展的非常迅速并且活跃。
能够生成显示网络拓扑结构和性能的可视化图。
tensorflow((tf)运算流程:)运算流程:
tensorflow的运行流程主要有2步,分别是构造模型和训练。
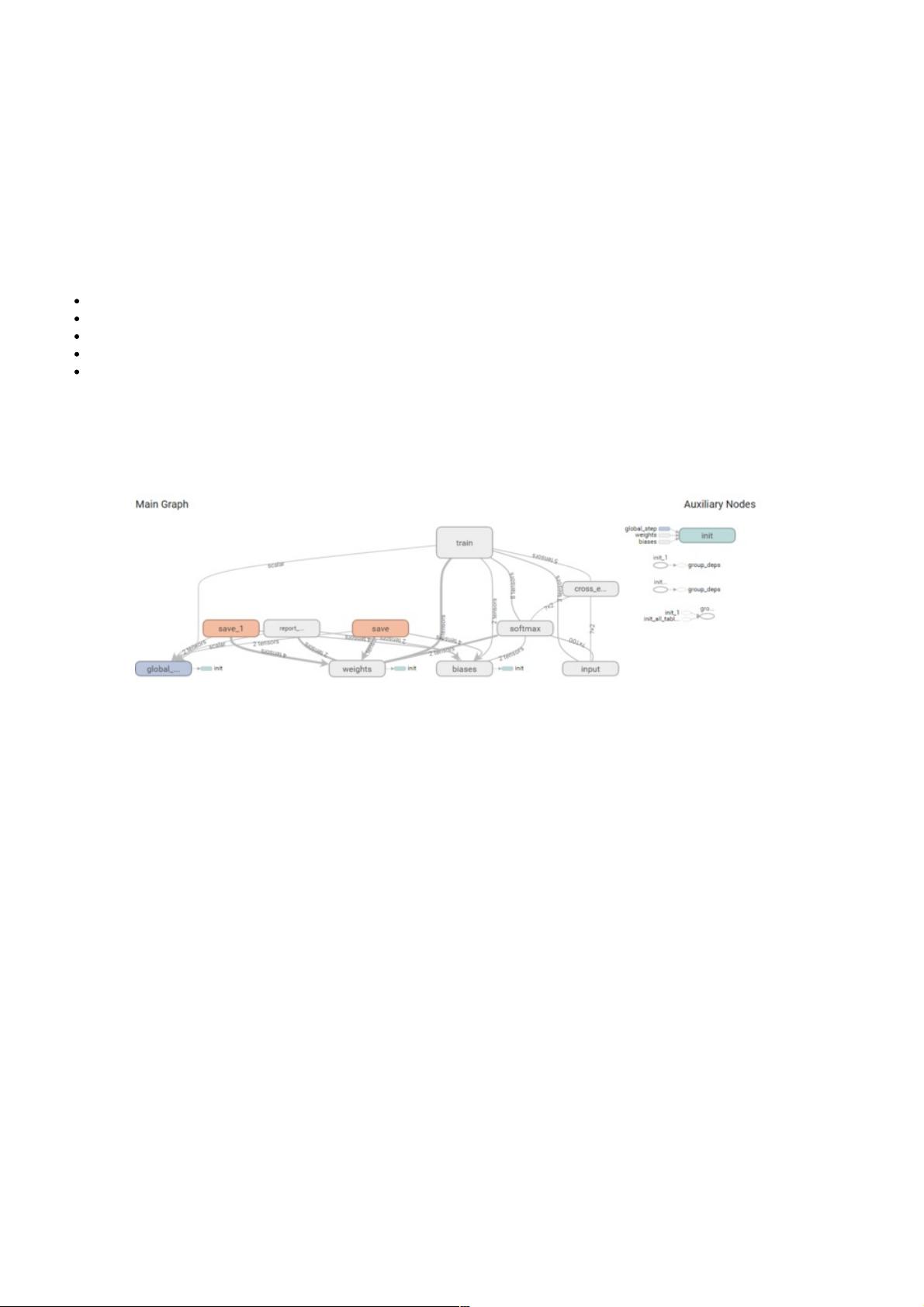
在构造模型阶段,我们需要构建一个图(Graph)来描述我们的模型,tensoflow的强大之处也在这了,支持tensorboard:
就类似这样的图,有点像流程图,这里还推荐一个google的tensoflow游乐场,很有意思。
然后到了训练阶段,在构造模型阶段是不进行计算的,只有在tensoflow.Session.run()时会开始计算。
文本分类文本分类
先给出代码,然后我们在一一做解释
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import tensorflow as tf
from collections import Counter
from sklearn.datasets import fetch_20newsgroups
def get_word_2_index(vocab):
word2index = {}
for i,word in enumerate(vocab):
word2index[word] = i
return word2index
def get_batch(df,i,batch_size):
batches = []
results = []
texts = df.data[i*batch_size : i*batch_size+batch_size]
categories = df.target[i*batch_size : i*batch_size+batch_size]
for text in texts:
layer = np.zeros(total_words,dtype=float)
for word in text.split(' '):
layer[word2index[word.lower()]] += 1
batches.append(layer)
for category in categories:
y = np.zeros((3),dtype=float)
下载后可阅读完整内容,剩余5页未读,立即下载
203 浏览量
241 浏览量
377 浏览量
2020-09-21 上传
139 浏览量
108 浏览量
2010-12-24 上传
131 浏览量
327 浏览量

weixin_38557068
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Node.js OpenStack客户端使用教程
- 压缩文件归档管理与组织方法详解
- MakeCode项目开发与管理:从扩展到部署
- 如何通过USB芯片检测甄别真假U盘
- cc2541 ccdebug烧录工具及SmartRF驱动程序安装指南
- 掌握VC++设计:深入解析俄罗斯方块游戏开发
- 掌握Solidity: 在以太坊测试网络上部署ERC20兼容合约
- YOLO-V3算法在PyTorch中的实现与性能提升
- 自动格式化各国货币类型,个性化货币设置工具
- CSS3按钮:20种炫酷样式与滑过特效
- STM32系列单片机ADC+DMA实验教程与实践
- 简易象棋游戏Java编程教程
- 打造简易ASP网站服务器的实践指南
- Gatsby入门:使用hello-world启动器快速启动React项目
- POJOGenerator v1.3.3:绿色免费POJO代码生成器发布
- 软件开发方法与工具实践:CSCI3308项目解析
