"深度解读决策树和随机森林的内部工作机制"
版权申诉
145 浏览量
更新于2024-02-22
收藏 404KB DOCX 举报
过程中的每个叶子节点都代表了一个决策。在构建决策树的过程中,算法会根据数据的特征不断进行分裂,直到满足某种条件为止。决策树的工作方式主要包括以下几个步骤:
1. 特征选择:在构建决策树时,算法会根据某种准则选择最佳的特征作为当前节点的划分标准。这个准则可以是信息增益、基尼指数或者均方差等。
2. 节点分裂:根据选定的特征,将数据集分成不同的子集。这个过程会一直进行下去,直到满足停止条件为止,比如节点样本数达到一定阈值或者树的深度达到预定值。
3. 叶子节点处理:当所有分裂操作完成后,每个叶子节点都会对应一个分类或者回归输出。这些输出可以是平均值、多数投票法等。此时,决策树就可以用来进行预测或分类。
决策树虽然简单直观,但在处理复杂数据时往往存在过拟合的问题。因此,随机森林这种基于决策树的集成学习方法应运而生。
随机森林的工作方式
随机森林是一种集成学习方法,其基本单元就是决策树。它通过随机选择特征和样本,建立多个决策树,并通过投票的方式来决定最终的分类结果。随机森林的工作方式主要包括以下几个步骤:
1. 随机选择样本:在建立每棵决策树时,从原始数据集中随机选择一定比例的样本进行训练。这种采样方法被称为“自助采样”(bootstrap)。
2. 随机选择特征:在决定节点分裂时,随机选择一部分特征进行评估,从而避免过拟合。这种方法被称为“随机特征选择”。
3. 建立决策树:通过重复以上步骤,建立多棵决策树。每棵树的训练集和特征都是不同的,从而增加了模型的多样性和泛化能力。
4. 集成决策:在进行预测时,随机森林会将每棵树的预测结果进行投票或平均,确定最终的预测结果。这种集成方法能够降低模型的方差,提高模型的稳定性和准确性。
总结
决策树和随机森林是常用的机器学习模型,在数据挖掘、分类和回归等领域有着广泛的应用。理解它们的内部工作机制对于提高模型的性能和解释能力至关重要。通过本文的介绍,读者可以更加深入地了解决策树和随机森林的工作方式,从而更好地应用于实际问题中。同时,读者也可以进一步探索相关的算法原理和实践经验,不断提升自己在机器学习领域的技术水平。愿本文能给读者带来启发和帮助,促使大家在数据科学的道路上不断前行。
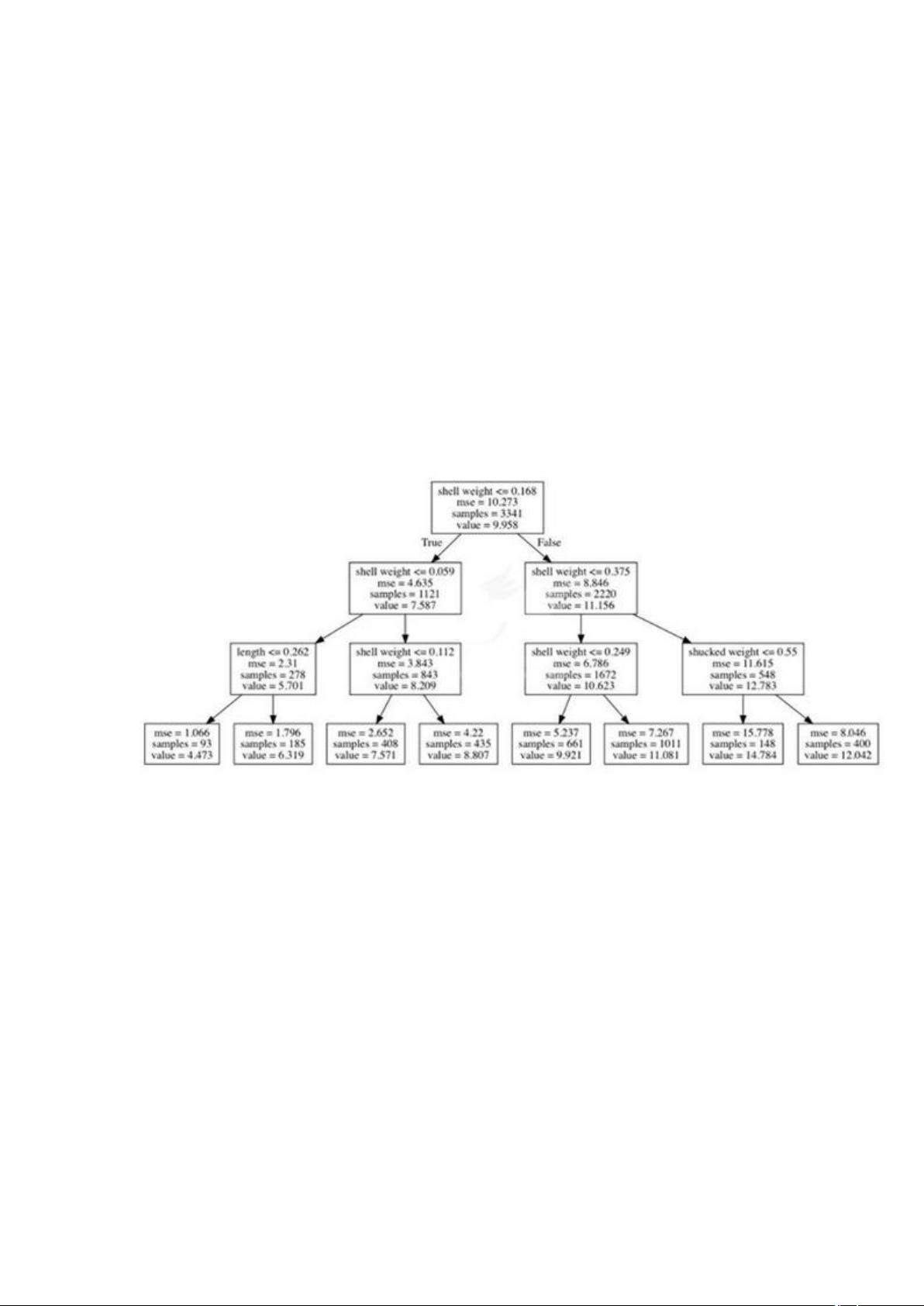
以 鲍 鱼 数 据 集
(https://archive.ics.uci.edu/ml/datasets/abalone )为例。我
们将根据壳的重量、长度、直径等变量来预测鲍鱼壳上环的
数量。为了演示,我们构建了一个很浅的决策树。我们可以
通过将树的最大层数限制为 3 而得到这个树。
图 2:预测不同环数的决策树路径
要预测鲍鱼的环的数量,决策树将沿着树向下移动直到
到达一个叶节点。每一步都会将当前的子集分成两个。对于
一次特定的分割,我们根据平均环数的改变来定义对该分割
剩余21页未读,继续阅读
2021-10-26 上传
2022-07-10 上传
2023-07-26 上传
2021-12-23 上传
2022-06-18 上传
2023-09-28 上传
2023-07-30 上传

weixin_41031635
- 粉丝: 0
- 资源: 5万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
