Java编码深度解析:中文乱码背后的秘密
需积分: 14 62 浏览量
更新于2024-07-23
收藏 298KB DOCX 举报
Java中文乱码问题是一个普遍存在的挑战,尤其是在处理跨平台交互时。Java作为一门广泛使用的编程语言,由于其设计初衷支持多平台兼容性,导致在处理文本数据,特别是非ASCII字符如中文时,编码问题显得尤为重要。本文将深入探讨Java中的编码问题及其解决方案。
首先,文章解释了编码的必要性。计算机使用二进制位(bits)存储信息,而人类使用的字符集数量众多,远远超出一个字节(8个bit)所能表示的范围。为了使计算机能够理解非ASCII字符,如中文,我们需要将这些字符转化为计算机可以识别的编码形式,这个过程类似于语言翻译。编码的主要目标是找到一种数据结构,如char,将其转换为字节(byte),以便存储和传输。
Java中常见的编码格式包括ASCII、ISO-8859-1、GB2312、GBK、UTF-8和UTF-16等。ASCII是一种较早的单字节编码,仅支持拉丁字母,不能完全覆盖非英文字符。ISO-8859-1和GB2312扩展了ASCII,但可能不包含所有汉字。GBK和UTF-8是两种常用的多字节编码,UTF-8具有更好的跨平台兼容性和更小的存储空间需求,而UTF-16则为每个汉字分配两个字节,占用空间较大。
在实际开发中,Java中文编码问题可能出现在以下几个场景:
1. **文件读写**:当处理文本文件时,如果不正确地指定文件的编码,可能会导致读取或写入的中文字符错误。
2. **网络通信**:HTTP请求和响应中的字符编码需要统一,否则可能导致显示乱码。例如,POST请求的body和URL查询参数可能需要设置为UTF-8编码。
3. **Javaweb应用**:在服务器端处理用户输入的文本,如表单提交,如果没有正确设置HTTP头或数据库连接的字符集,中文字符可能出现乱码。
4. **字符串操作**:字符串的拼接、格式化等操作如果不明确指定字符集,可能会造成编码转换错误。
为了避免中文问题,开发人员应遵循以下策略:
- **设置明确的编码**:在编写代码时,确保字符串、文件和网络通信的编码格式一致,比如使用`StandardCharsets.UTF_8`。
- **处理输入**:对用户输入进行解码和转码,确保输入符合预期的编码格式。
- **配置环境变量**:如系统属性`file.encoding`和数据库连接字符集设置。
- **异常处理**:捕获并处理可能出现的编码异常,提供良好的错误提示和恢复机制。
总结来说,理解Java中的编码问题以及如何选择合适的编码格式是开发过程中必不可少的知识。通过合理处理字符编码,可以有效避免中文乱码问题,提高应用程序的稳定性和用户体验。
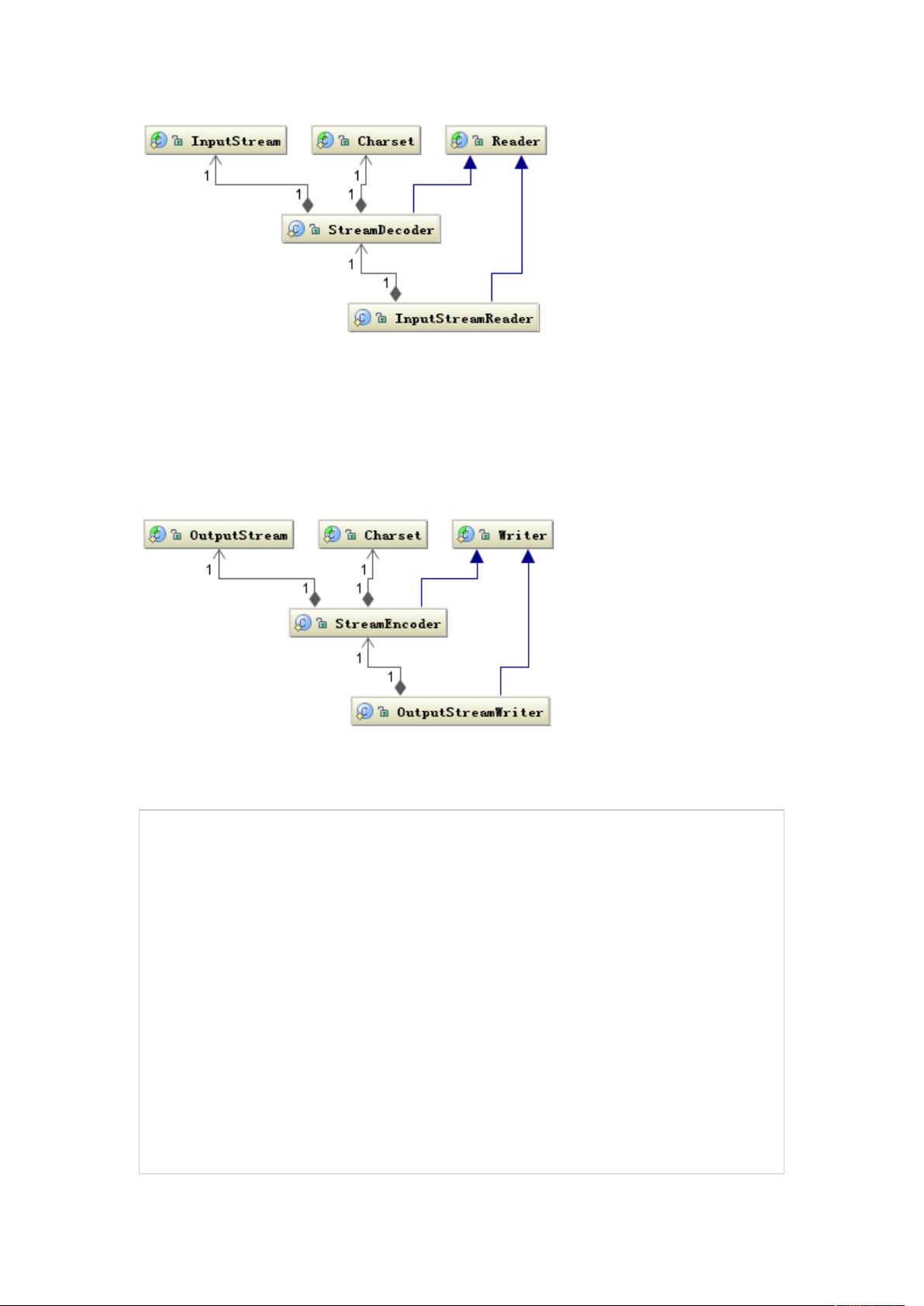
Reader 类是 Java 的 I/O 中读字符的父类,而 InputStream 类是读字节的父类,
InputStreamReader 类就是关联字节到字符的桥梁,它负责在 I/O 过程中处理读取字节到字符
的转换,而具体字节到字符的解码实现它由 StreamDecoder 去实现,在 StreamDecoder 解
码过程中必须由用户指定 Charset 编码格式。值得注意的是如果你没有指定 Charset,将使用
本地环境中的默认字符集,例如在中文环境中将使用 GBK 编码。
写的情况也是类似,字符的父类是 Writer,字节的父类是 OutputStream,通过
OutputStreamWriter 转换字符到字节。如下图所示:
同样 StreamEncoder 类负责将字符编码成字节,编码格式和默认编码规则与解码是一致的。
如下面一段代码,实现了文件的读写功能:
清单 1.I/O 涉及的编码示例
写字符换转成字节流
!"
# #!
$"
%&
!这是要保存的中文字符"
'%&
!"
'
读取字节转换成字符
( (!"
()** ()*!
$"
剩余18页未读,继续阅读
2691 浏览量
1633 浏览量
8451 浏览量
235 浏览量
216 浏览量
4718 浏览量
151 浏览量

andyzhaojianhui001
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- c++新手必看,手把手教你c++
- java课件, 包含多线程
- 数据库函数实例的小例子 有助于初学者更好的理解存储过程的操作
- Administracion Tomcat
- 易学c++初学者的好帮手
- java课件,入门者可以来参考一下
- OpenCms7教程(3)
- Patterns of Enterprise Application Architecture
- Architectural Blueprints—The “4+1” View英文
- OpenCms7教程(2).pdf
- 《计算机网络》课后习题答案
- Applying Domain Driven Design and Patterns
- A quick guide to CISSP certification
- 高质量C++C 编程指南.
- icc编译器中文使用说明
- JSP高级编程,详细介绍JSP的开发知识
