Hadoop组件详解:HDFS、MapReduce与Hbase入门
115 浏览量
更新于2024-09-05
收藏 226KB PDF 举报
"Hadoop组件简介,包括HDFS、MapReduce和HBase的介绍及HDFS的优势"
在Hadoop生态系统中,有多个关键组件协同工作,以实现高效、可靠的分布式计算和存储。首先,我们来看看Hadoop的核心组件:
1. HDFS(Hadoop Distributed File System)分布式文件系统:
HDFS是Hadoop的基础,它为大规模数据处理提供了高容错性的分布式存储。HDFS的主要优点包括:
- 高可用性:HDFS设计为能够容忍硬件故障,通过数据复制确保数据安全。
- 扩展性:HDFS能够轻松扩展到数千台服务器,提供PB级别的存储容量。
- 流式数据访问:适合大数据批处理任务,而不是频繁的随机读写操作。
- 大文件支持:可以处理GB到TB大小的单个文件。
- 简化的接口:对于用户来说,HDFS提供了一个类似于传统文件系统的简单接口,可以进行文件操作。
2. MapReduce:
MapReduce是Hadoop用于处理和生成大数据集的编程模型。它将大型数据集分解成小块,然后在集群中的多台机器上并行处理。Map阶段将数据分片并应用函数,Reduce阶段将结果聚合,从而得到最终输出。MapReduce的设计使得程序员可以专注于业务逻辑,而无需关心分布式计算的复杂性。
3. HBase:
HBase是一个基于HDFS的分布式数据库,提供实时读写访问和随机访问能力。它是一个NoSQL数据库,适用于半结构化和非结构化数据。HBase的特点包括:
- 表格模型:数据组织在列族中,列族下有列,列下有行。
- 实时查询:与HDFS不同,HBase允许快速的行级和列级数据访问。
- 空间和时间一致性:保证了数据的一致性,即使在高并发下。
- 水平扩展:可以通过添加更多的服务器来扩展存储和处理能力。
在安装和配置Hadoop时,例如HBase,通常需要设置环境变量,指定JDK路径,并修改配置文件如`hbase-env.sh`和`hbase-site.xml`来定制存储目录等。启动HBase后,可以使用命令行Shell进行交互,例如查看状态或执行操作。
总结来说,Hadoop通过HDFS、MapReduce和HBase等组件,构建了一个强大的分布式计算平台,适合处理海量数据。Hadoop的出现解决了传统计算框架在处理大规模数据时的效率问题,为大数据时代的数据分析和挖掘提供了有力工具。
Hadoop组件简介组件简介
Hadoop作为一种分布式基础架构,可以使用户在不了解分布式底层细节的情况下,开发分布式程序。接下来通
过本文给大家分享Hadoop组件简介,感兴趣的朋友一起看看吧
安装安装hbase
首先下载hbase的最新稳定版本
http://www.apache.org/dyn/closer.cgi/hbase/
安装到本地目录中,我安装的是当前用户的hadoop/hbase中
tar -zxvf hbase-0.90.4.tar.gz
单机模式单机模式
修改配置文件
conf/hbase_env.sh
配置JDK的路径
修改conf/hbase-site.xml
hbase.rootdir
file:///home/${user.name}/hbase-tmp
完成后启动
bin/start-hbase.sh
启动后
starting master, logging to/home/lgstar888/hadoop/hbase0.9/bin/../logs/hbase-lgstar888-master-ubuntu.out
然后执行
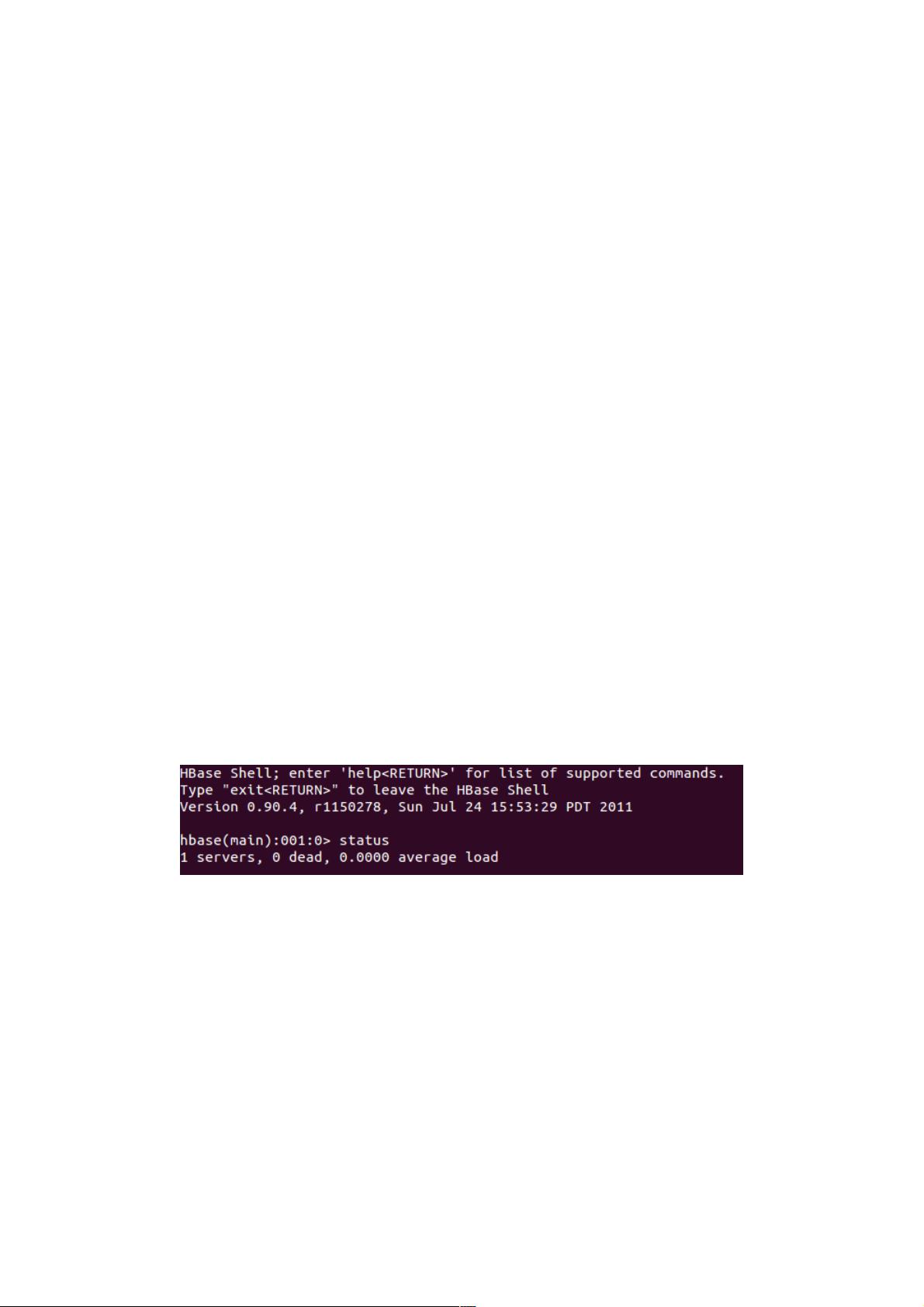
bin/hbase shell
输入status
如果输入exit则退出
Hadoop与Google一样,都是小孩命名的,是一个虚构的名字,没有特别的含义。从计算机专业的角度看,Hadoop是一个分
布式系统基础架构,由Apache基金会开发。Hadoop的主要目标是对分布式环境下的“大数据”以一种可靠、高效、可伸缩的方
式处理。设想一个场景,假如您需要grep一个100TB的大数据文件,按照传统的方式,会花费很长时间,而这正是Hadoop所
需要考虑的效率问题。
关于Hadoop的结构,有各种不同的说法。我们这里简单的理解为Hadoop主要由三部分组成:HDFS(HadoopDistributed File
System),MapReduce与Hbase。
1.Hadoop组件之一:组件之一:HDFS分布式文件系统具有哪些优点分布式文件系统具有哪些优点?
HDFS作为一种分布式文件系统,它和现有的分布式文件系统有很多共同点。比如,Hadoop文件系统管理的物理存储资
源不一定直接连接在本地节点上,而是通过计算机网络与节点相连。对于Client端而言,HDFS就像一个传统的分级文件系
统,可以创建、删除、移动或重命名文件等等。与此同时,HDFS与其他的分布式文件系统的区别也是显而易见的。
首先,HDFS设计目标之一是适合运行在通用硬件(commodityhardware)上的分布式文件系统。HDFS假设的硬件错误不
是异常,而是常态。因为HDFS面向的是成百上千的服务器集群,每台服务器上存储着文件系统的部分数据,并且这些机器的
价格都很低廉。这就意味着总是有一部分硬件因各种原因而无法工作。因此,错误检测和快速、自动的恢复是HDFS最核心的
架构目标。从这个角度说,HDFS具有高度的容错性。
第二,HDFS的另一个设计目标是支持大文件存储。与普通的应用不同,HDFS应用具有很大的数据集,一个典型HDFS
下载后可阅读完整内容,剩余3页未读,立即下载
2022-10-29 上传
103 浏览量
191 浏览量
186 浏览量
116 浏览量

weixin_38536716
- 粉丝: 11
- 资源: 921
 我的内容管理
展开
我的内容管理
展开







最新资源
- cygwin平台上NS2安装的详细步骤
- linux安装如何分区
- 计算机网络教学之局域网
- K3金蝶里的现金流量表入门操作手册
- 计算机网络教学之数据链路层
- 嵌入式软件UML设计范例
- 中国移动短信网关接口协议CMPP(V2.0.0).doc
- 谭浩强C语言.pdf
- The UNIX- HATERS Handbook(UNIX痛恨者手册)
- c语言编程100例.pdf
- ASP.NET程序设计教程与实训(C#语言版)
- Wrox - Professional Windows PowerShell
- JSP技术手册电子书内容详细
- TD-SCDMA基本原理--上海欣民
- Interfacing the MSP430 and TMP100 Temperature Sensor
- 华为公司以前的笔试题
