"深度学习优化算法解析:从理论到应用"
需积分: 0 53 浏览量
更新于2024-03-21
收藏 18.84MB PDF 举报
Deep learning algorithms are at the forefront of artificial intelligence and involve complex optimization processes. The applications of deep learning are vast, from performing inference in models like PCA to training neural networks. Optimization is a crucial component in deep learning, whether it is for writing proofs, designing algorithms, or training deep models.
One of the most challenging optimization problems in deep learning is neural network training. This process often requires a significant amount of time and computational resources, with researchers sometimes investing days to months and utilizing hundreds of machines to solve a single instance. The complexity of training neural networks lies in the large number of parameters that need to be optimized, as well as the non-convex nature of the optimization problem.
Despite the challenges, optimization is essential for improving the performance of deep learning models. By fine-tuning the parameters of neural networks and optimizing the training process, researchers can enhance the accuracy and efficiency of these models. Optimization techniques such as stochastic gradient descent, Adam, and RMSprop play a critical role in training deep models and achieving state-of-the-art performance in various tasks such as image recognition, natural language processing, and reinforcement learning.
In conclusion, optimization is a fundamental aspect of deep learning, powering the training and inference processes of complex models. While neural network training can be time-consuming and computationally intensive, the advancements in optimization algorithms have paved the way for groundbreaking innovations in artificial intelligence. By continuously refining and improving optimization techniques, researchers can unlock the full potential of deep learning and push the boundaries of what is possible in the field of AI.
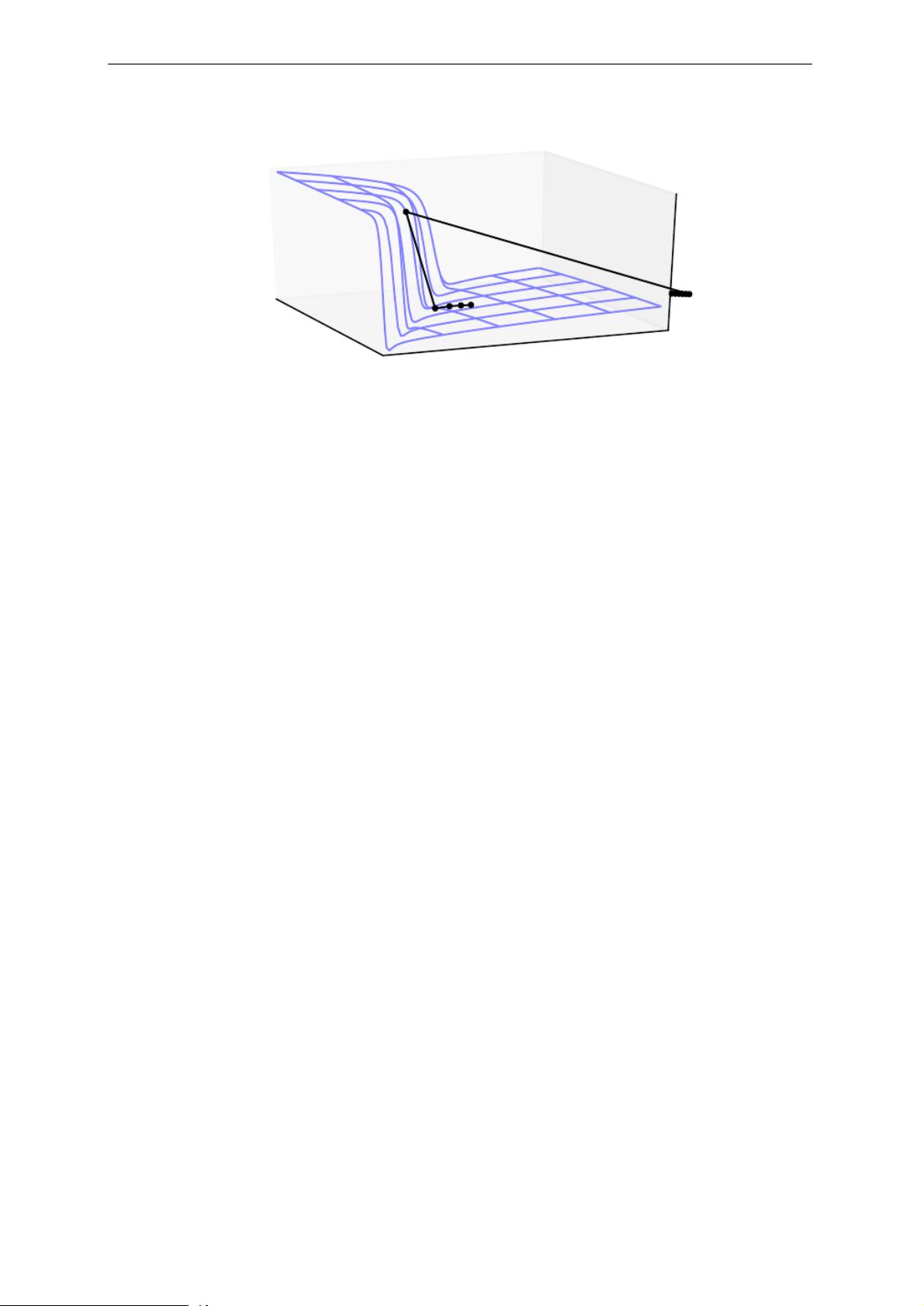
CHAPTER 8. OPTIMIZATION FOR TRAINING DEEP MODELS
w
b
J w;b( )
Figure 8.3: The objective function for highly nonlinear deep neural networks or for
recurrent neural networks often contains sharp nonlinearities in parameter space resulting
from the multiplication of several parameters. These nonlinearities give rise to very
high derivatives in some places. When the parameters get close to such a cliff region, a
gradient descent update can catapult the parameters very far, possibly losing most of the
optimization work that had been done.Figure adapted with permission from Pascanu
et al. ( ).2013a
The cliff can be dangerous whether we approach it from above or from below,
but fortunately its most serious consequences can be avoided using the gradient
clipping heuristic described in Sec. .The basic idea is to recall that the10.11.1
gradient does not specify the optimal step size, but only the optimal direction
within an infinitesimal region. When the traditional gradient descent algorithm
proposes to make a very large step, the gradient clipping heuristic intervenes to
reduce the step size to be small enough that it is less likely to go outside the region
where the gradient indicates the direction of approximately steepest descent. Cliff
structures are most common in the cost functions for recurrent neural networks,
because such models involve a multiplication of many factors, with one factor
for each time step. Long temporal sequences thus incur an extreme amount of
multiplication.
8.2.5 Long-Term Dependencies
Another difficulty that neural network optimization algorithms must overcome arises
when the computational graph becomes extremely deep.Feedforward networks
with many layers have such deep computational graphs. So do recurrent networks,
described in Chapter ,which construct very deep computational graphs by10
289



剩余230页未读,继续阅读
2022-08-03 上传
189 浏览量
241 浏览量
238 浏览量
2021-04-23 上传
2025-01-02 上传
158 浏览量









