原生JS与jQuery获取元素差异解析
27 浏览量
更新于2024-08-31
收藏 104KB PDF 举报
"这篇技术文章深入探讨了原生JavaScript(JS)与jQuery(JQ)在获取页面元素上的差异,提供了详细的代码示例,有助于初学者区分这两种方式的使用。
一、原生JS获取元素
1. 获取元素的三种常见方法:
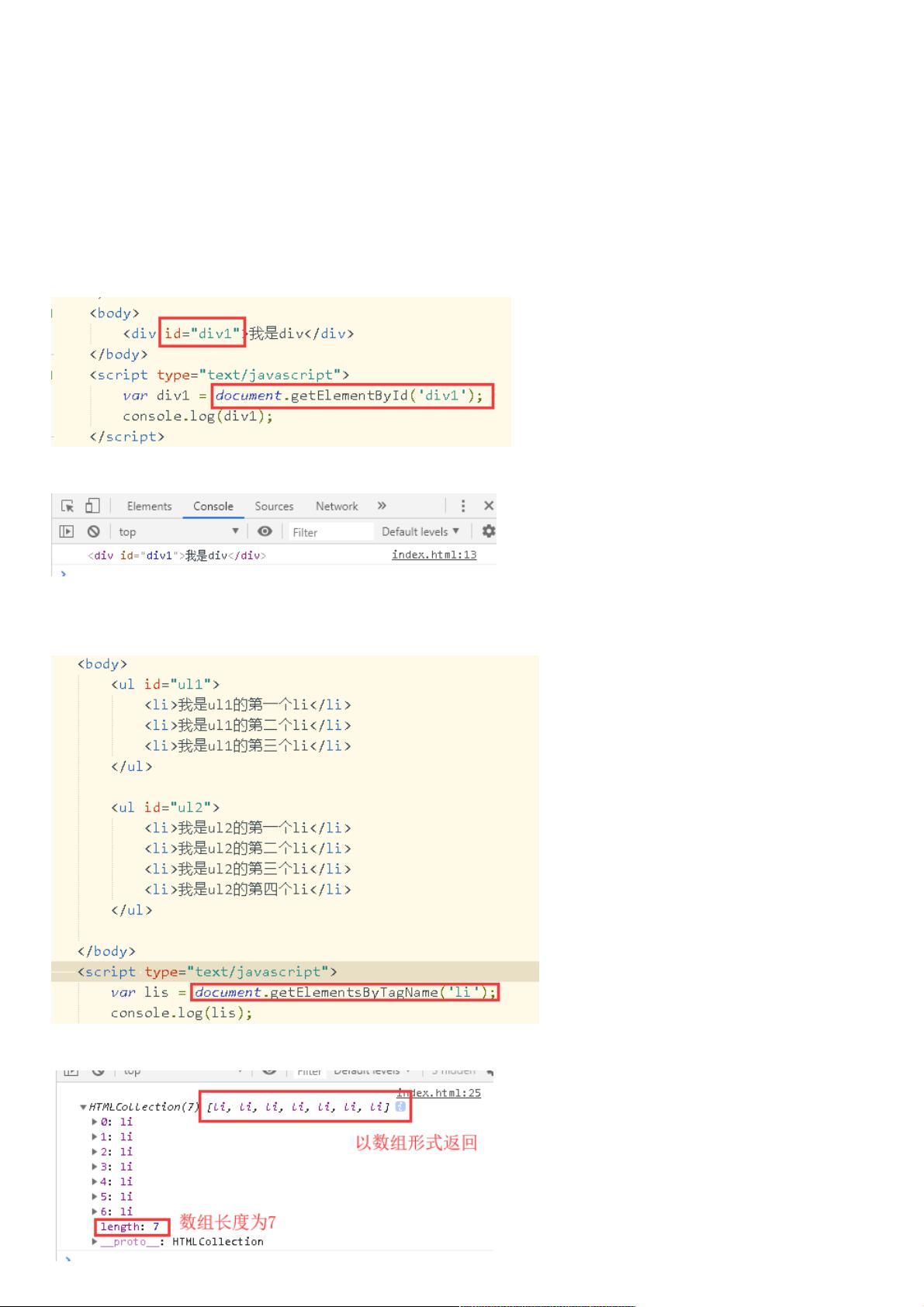
- 通过ID获取:`document.getElementById()`。例如,获取id为"div1"的元素,输出结果为对应的DOM对象。
- 通过标签名获取:`document.getElementsByTagName()`。此方法返回一个包含所有指定标签名元素的HTMLCollection,如获取所有`<li>`元素,可以进一步通过索引访问特定元素。
- 通过类名获取:`document.getElementsByClassName()`。返回的是一个NodeList,例如获取类名为"sp"的所有元素。
二、jQuery获取元素
1. jQuery的简洁语法体现在其工厂函数`$()`,通过这个函数,我们可以创建jQuery对象并使用各种选择器来选取元素。
- ID选择器:`$("#div1")`,返回一个jQuery对象,包含对应ID的元素。
- 类选择器:`$(".className")`,返回一个jQuery对象集合,包含所有匹配类名的元素。
- 元素选择器:`$("tagName")`,返回一个jQuery对象集合,包含所有指定标签名的元素。
对比原生JS,jQuery提供了更简洁的语法和强大的选择器系统,使得开发者能更高效地操作DOM。然而,对于性能敏感的场景,原生JS可能更具优势,因为它避免了额外的库依赖和函数调用开销。在实际开发中,开发者应根据项目需求和性能要求灵活选择使用原生JS还是jQuery来获取和操作页面元素。"
本文详尽阐述了原生JS与jQuery在获取HTML元素上的差异,通过实例代码展示了两种方式的使用方法,帮助读者理解何时以及如何选择合适的API。同时,也强调了在效率和便利性之间的权衡,这对于提升前端开发的实践技能至关重要。
原生原生JS与与JQ获取元素的区别详解获取元素的区别详解
这篇文章主要介绍了原生JS与JQ获取元素的区别详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的
参考学习价值,需要的朋友可以参考下
刚学JQ不久,有时候可能会把JS和JQ获取元素的方式搞错,接下来获取属性方法什么的就一发不可收拾了,现在把两者获取
获取元素的代码整理下。
一.原生JS获取元素。
1.常用的三种方式获取元素对象(将指定的元素封装成DOM对象):
(1)通过元素ID获取:document.getElementById(),示例如下:
我们在控制台输出,结果如下:
可以看到我们获取到了id为div1的元素代码了
(2)通过元素标签名获取:document.getElementsByTagName(),它以数组的形式返回,具体示例如下:
控制台输出如下:
下载后可阅读完整内容,剩余3页未读,立即下载
2018-11-17 上传
2020-11-26 上传
2020-10-24 上传
2023-03-30 上传
2023-05-23 上传
2023-09-15 上传
2023-06-10 上传
2023-05-13 上传
2023-07-12 上传

weixin_38558186
- 粉丝: 4
- 资源: 878
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
