"基于Python的大学生线上学习体验分析与聚类研究"
 已收录资源合集
已收录资源合集
需积分: 0 55 浏览量
更新于2024-01-14
收藏 16.86MB PDF 举报
本设计主要分为三个步骤:数据收集与预处理、聚类分析和可视化展示。首先,利用Python编程进行爬虫搜集微博平台上关于大学生网课的评论,获取原始语料数据。然后对数据进行分词和数据清洗,去除噪声和无关信息,并进行词频统计,得到每个词在语料库中的重要程度。接下来利用机器学习和自然语言处理的方法,对预处理后的数据进行聚类分析,将相似的评论归为一类,以揭示大学生在线学习体验的不同特点和现状。最后,根据所得到的聚类结果进行前端可视化展示和分析,通过可视化的形式呈现出学生在线学习体验的趋势和问题,为未来的在线教学提供参考。
在数据收集与预处理阶段,利用Python编程实现爬虫程序,抓取微博平台上有关大学生网课的评论数据,并将数据保存为list的元素,以便后续的处理和分析。接着对抓取到的原始数据进行文本分词和数据清洗,去除停用词和特殊符号,保留语料中有用的信息。然后利用TF-IDF(词频-逆文档频率)算法,计算每个词在语料库中的重要程度,以便后续的聚类分析和可视化展示。经过这一步骤,我们得到了处理完毕的文本数据,为后续的聚类分析和可视化展示奠定了基础。
在聚类分析阶段,通过SPSS、机器学习和自然语言处理等方法对预处理后的文本数据进行聚类分析。首先,利用机器学习的聚类算法,将文本数据进行自动分类,找出其中的相似模式和规律。然后对每个类别的评论进行分析,揭示其中的共性和差异性,以便理解大学生在线学习体验的不同特点和现状。通过这一步骤,我们可以深入挖掘抓取到的评论数据,发现其中的潜在规律和价值信息,为后续的可视化展示提供有力支持。
在可视化展示阶段,根据聚类分析的结果利用前端可视化技术,对学生在线学习体验的趋势和问题进行展示和分析。通过图表、图形和统计数据的呈现,将聚类分析的结果直观地展现出来,以便深入理解大学生在线学习的现状和趋势。同时,通过可视化的方式呈现出一些待解决的问题和改进建议,为未来的在线教学提供参考和借鉴。通过这一步骤,我们可以在视觉上直观地理解学生在线学习的情况,为在线教学的改进提供有力支持。
综上所述,本设计利用Python编程爬虫搜集微博平台上关于大学生网课的评论,使用SPSS、机器学习和自然语言处理等方法对文本数据进行分词、数据清洗、词频统计和聚类分析,并利用前端可视化技术进行展示和分析。通过以上三个步骤的操作,我们可以深入挖掘抓取到的评论数据,揭示大学生在线学习的不同特点和现状,为未来的在线教学提供参考和借鉴。同时,我们也可以发现其中的一些待解决的问题和改进建议,为在线教学的改进提供有力支持。通过这一设计,我们可以更好地了解大学生线上学习的情况,为未来的在线教学提供科学依据,为学生的学习体验和教学质量提供有力支持。
4 / 18
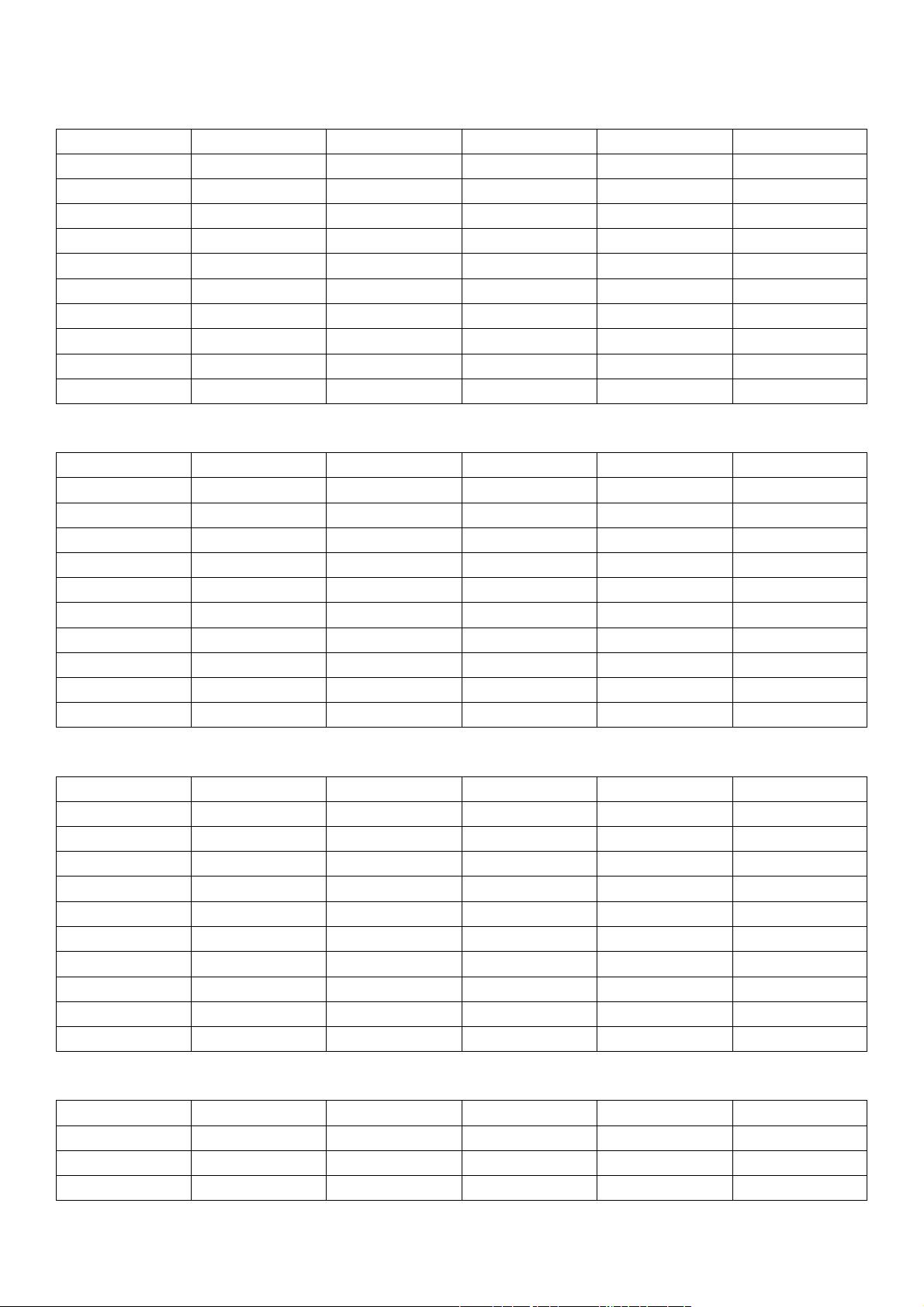
此时就可以进行词频的统计了,部分结果统计如下表:
微博
2019
年上半年词频数排行前
20
词频表
排序
词语
词频数
排序
词语
词频数
1
网课
7620
11
网红
1555
2
培训
3954
12
蛋糕
1549
3
老师
3048
13
机构
1420
4
学习
2783
14
厦门
1386
5
考研
2673
15
时间
1327
6
课程
2129
16
初级
1300
7
英语
2090
17
学校
1275
8
烘焙
2086
18
打卡
1163
9
视频
2063
19
美食
1133
10
考试
1672
20
尚德
1098
微博
2020
年上半年词频数排行前
20
词频表
排序
词语
词频数
排序
词语
词频数
1
网课
13804
11
笔记
1493
2
学习
3505
12
单词
1479
3
打卡
2978
13
复习
1234
4
老师
2813
14
学校
1222
5
明天
2765
15
感觉
1199
6
作业
2233
16
今日
1187
7
英语
1940
17
晚上
1170
8
考研
1927
18
开学
1108
9
视频
1896
19
希望
1032
10
时间
1645
20
加油
1015
微博
2021
年上半年词频数排行前
20
词频表
排序
词语
词频数
排序
词语
词频数
1
网课
15283
11
喜欢
1365
2
老师
3251
12
感觉
1365
3
学习
3073
13
英语
1331
4
考研
2470
14
晚上
1258
5
视频
2210
15
作业
1253
6
时间
1864
16
希望
1240
7
教育
1763
17
能量
1207
8
明天
1641
18
数学
1202
9
学校
1491
19
上网
1189
10
打卡
1397
20
孩子
1177
Coursera
词频数排行前
20
词频表
排序
词语
词频数
排序
词语
词频数
1
learning
185782
11
fashion
22903
2
korean
101273
12
brand
20402
3
learn
87710
13
easy
18948
剩余17页未读,继续阅读
点击了解资源详情
151 浏览量
点击了解资源详情
2012-07-02 上传
2008-12-28 上传
2009-10-28 上传
108 浏览量
2022-08-03 上传
150 浏览量

我有多作怪
- 粉丝: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- DeepFreeze密码移除工具6.x版本使用教程
- MQ2烟雾传感器无线报警器项目解析
- Android实现消息推送技术:WebSocket的运用解析
- 利用jQuery插件自定义制作酷似Flash的广告横幅通栏
- 自定义滚动时间选择器,轻松转换为Jar包
- Python环境下pyuvs-rt模块的使用与应用
- DLL文件导出函数查看器 - 查看DLL函数名称
- Laravel框架深度解析:开发者的创造力与学习资源
- 实现滚动屏幕背景固定,提升网页高端视觉效果
- 遗传算法解决0-1背包问题
- 必备nagios插件压缩包:实现监控的关键
- Asp.Net2.0 Data Tutorial全集深度解析
- Flutter文本分割插件flutter_break_iterator入门与实践
- GD Spi Flash存储器的详细技术手册
- 深入解析MyBatis PageHelper分页插件的使用与原理
- DELPHI实现斗地主游戏设计及半成品源码分析
