Solr5.5.4部署教程:jetty与tomcat集成IKAnalyzer
需积分: 10 35 浏览量
更新于2024-07-19
收藏 14.89MB DOCX 举报
"solr5.5.4的部署与使用,包括jetty和tomcat部署方式,集成IKAnalyzer中文分词器以及支持word文档"
在本文档中,我们将深入探讨如何部署Apache Solr 5.5.4版本,这是一个流行的全文搜索引擎,常用于企业级数据的检索和分析。我们将主要关注两种部署方式——Jetty和Tomcat,并介绍如何配置中文分词器IKAnalyzer,以及支持Word文档的处理。
首先,确保你拥有合适的环境配置,包括JDK 1.7或更高版本,Tomcat 8或更新版本,以及Solr和SolrJ的5.5.4版本。部署Solr的第一步是通过Apache官方网站下载对应版本的Solr,解压缩文件,然后进入解压后的`bin`目录。
对于Jetty部署,遵循以下步骤:
1. 使用提供的`solrstart`命令启动Solr服务,这将默认在8983端口运行。你可以通过访问`http://localhost:8983/solr`来验证服务是否正常工作。
2. 使用`solrstop`命令停止服务,你可以选择停止特定端口或所有端口。
3. 创建一个名为`core`的索引库目录,并在其中创建`conf`子目录,以存储Solr的配置文件。
4. 将`configsets\sample_techproducts_configs\conf`目录下的所有文件复制到新创建的`core\conf`目录,这包含了Solr的基本配置。
5. 重新启动Solr服务,并再次验证服务是否正常运行。
接下来,你需要在Solr管理界面的CoreAdmin中添加新的核心(core)。设置`name`为`core`,`instanceDir`指向`core`目录,然后点击`AddCore`。如果出现错误,检查核心名称和配置文件是否正确无误。
对于Tomcat部署,你需要将解压后的Solr目录放置在Tomcat的`webapps`目录下,然后启动Tomcat服务器。Solr会自动部署并可以在Tomcat管理界面中管理。
为了支持中文分词,我们需要集成IKAnalyzer。这个分词器特别设计用于处理中文文本,能有效切分词语。在`solrconfig.xml`文件中添加IKAnalyzer的相关配置,指定分词器路径,并在`schema.xml`中定义字段类型以使用IKAnalyzer。
至于处理Word文档,Solr可以通过使用特定的解析器来支持。例如,可以配置Tika解析器,它能够解析多种文件格式,包括Word文档。在`solrconfig.xml`中添加Tika相关的配置,然后上传Word文档到Solr,系统将自动进行内容提取和索引。
Solr 5.5.4的部署和使用涉及到多个步骤,包括环境配置、服务启动和停止、核心的创建与管理,以及第三方组件如IKAnalyzer和Tika的集成。理解并熟练掌握这些过程对于有效地利用Solr处理和搜索大量数据至关重要。
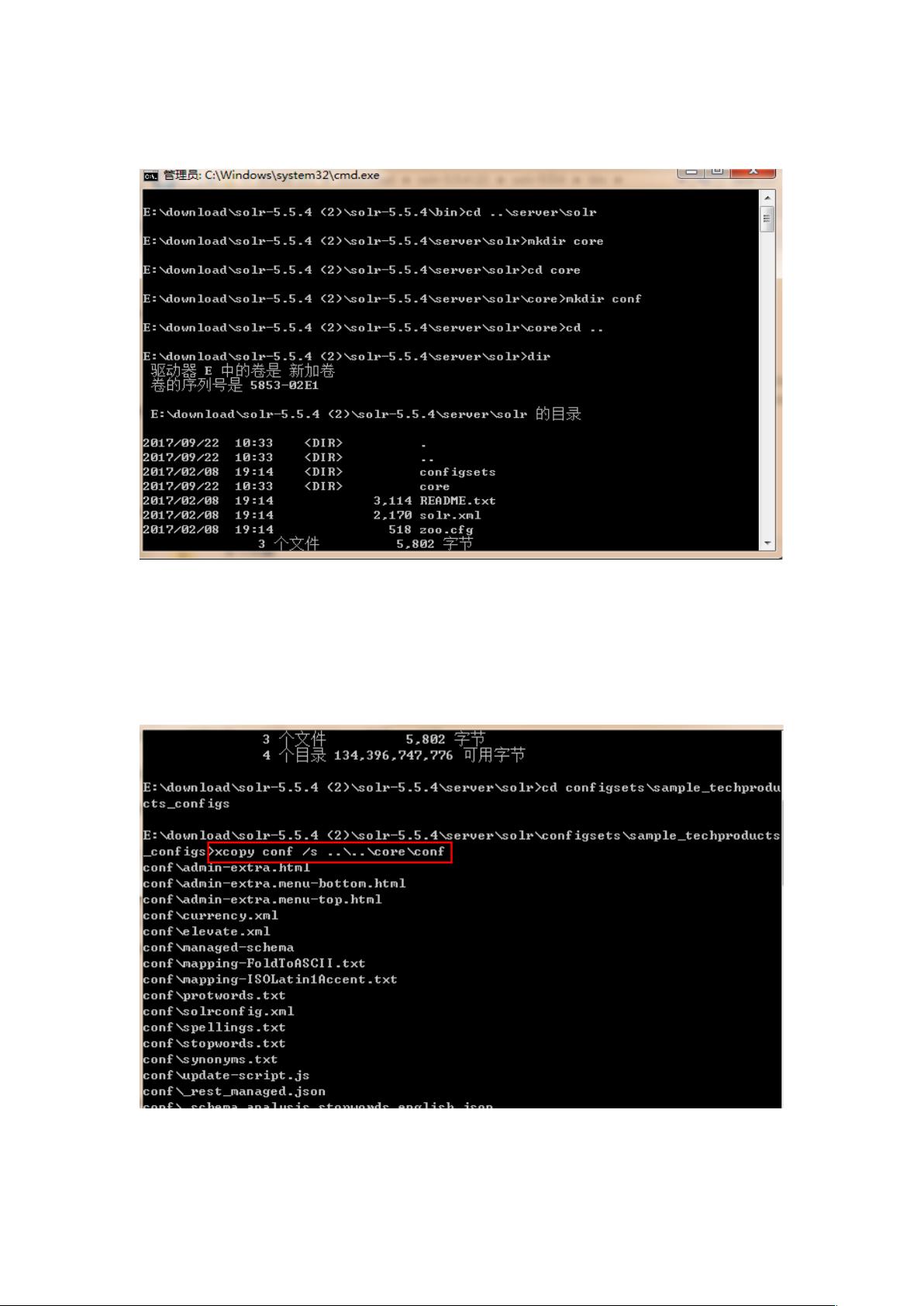
放 索引库配置文件的地方,执行命令如下:
( ) 复 制 解 压 文 件 下 的 %***,*
--,*+ 目录下的所有文件到 *
+ 目录下,执行命令如下图所示:
(&)重新启动 服务,切换到 目录下的 # 目录下,执行
剩余16页未读,继续阅读
2017-09-22 上传
2017-09-21 上传
2018-07-09 上传
2017-09-03 上传
2017-07-03 上传

Edward_S_Y
- 粉丝: 9
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







最新资源
- webgl-video-filter-example:使用麦克风输入的 GLSL 视频过滤示例
- HyperMinHash-java:日志日志空间中的并集,交集和设置基数
- weixin008微信平台的旅游出行必备商城小程序+ssm(源码+部署说明+演示视频+源码介绍+lw).rar
- dms-lk:数据管理系统(实验室密钥专用)
- PCtoLCD易语言版-易语言.zip
- naver_oauth2
- 创业计划书-2010“东风风神杯”四川省首届大学生营销策划大赛促销方案
- PHP超全网页在线qq音乐html静态页面
- 易语言BABYTEXT核心库模块源码.zip
- samsung-530U3C-hackintosh:仅供测试
- Python库 | Flask-Ticketing-0.2.tar.gz
- yPlot-开源
- 作为vue组件的简单拖放层次结构列表。-JavaScript开发
- 技术交底及其安全资料库-电梯安装工程安全技术交底
- 实现Html转PDF itextpdf-5.5.5.jar
- reactivejavademo
