深入理解RedisCluster分区机制
PDF格式 | 298KB |
更新于2024-08-28
| 137 浏览量 | 举报
"RedisCluster分区实现原理"
RedisCluster是Redis的一个扩展特性,它为用户提供了一种分布式缓存和数据库解决方案,通过将数据分散到多个节点上,实现了数据的自动分区。这个架构允许Redis处理大量数据并提高系统的可伸缩性。在RedisCluster中,数据分区的关键在于槽(slot)的概念,每个槽对应一个编号,从0到16383,共16384个。
槽分配策略是RedisCluster分区实现的核心。每个Master节点负责一部分槽,当客户端请求一个特定的key时,RedisCluster会根据一个哈希函数计算key的哈希值,然后将这个哈希值映射到对应的槽上。这样,每个key都会被分配到集群中的某个特定节点进行服务。这种分配方式确保了数据的分布均匀性,减少了热点数据集中在单一节点的情况。
为了保证客户端能正确访问数据,RedisCluster采用了路由机制。客户端在发送命令时,不仅需要知道key,还需要知道key所属的槽以及负责该槽的节点。这通常是通过查询集群的元数据来完成的,元数据包含了槽与节点的映射关系。客户端一旦知道了key所在的节点,就可以直接向该节点发送命令,无需经过中间代理。
为了实现高可用性,RedisCluster采用主从复制模式,每个Master节点都有一个或多个Slave节点。当Master节点发生故障时,其Slave可以接管并成为新的Master,继续提供服务。此外,通过集群总线(Cluster Bus),节点间可以进行通信,用于传播状态更新和故障检测,确保集群的稳定运行。
在RedisCluster中,槽的迁移是动态进行的,以适应节点的添加、删除或者负载均衡。槽迁移过程需要确保不影响正常服务,这意味着在迁移过程中,旧Master和新Master都必须能够处理针对迁移槽的请求,直到迁移完成。槽迁移的复杂性使得它成为RedisCluster设计中的一个重要挑战。
RedisCluster的通信机制是基于二进制协议的,这提高了节点间通信的效率。而客户端则使用标准的Redis文本协议与集群节点通信,简化了客户端的实现。值得注意的是,由于RedisCluster不支持全局事务,因此在分布式一致性方面,它依赖于客户端来实现数据的一致性视图。
总结来说,RedisCluster通过槽分区、路由机制、主从复制和槽迁移策略,实现了分布式环境下的数据管理和高可用性。理解这些原理对于有效地部署和使用RedisCluster至关重要,它可以帮助开发者构建出高性能、可扩展的分布式应用。
RedisCluster分区实现原理分区实现原理
摘要
Redis Cluster本身提供了自动将数据分散到Redis Cluster不同节点的能力,分区实现的关键点问题包括:如何将数据自动地打
散到不同的节点,使得不同节点的存储数据相对均匀;如何保证客户端能够访问到正确的节点和数据;如何保证重新分片的过
程中不影响正常服务。这篇文章通过了解这些问题来认识Redis Cluster分区实现原理。
认识Redis Cluster
Redis Cluster是由多个同时服务于一个数据集合的Redis实例组成的整体,对于用户来说,用户只关注这个数据集合,而整个
数据集合的某个数据子集存储在哪个节点对于用户来说是透明的。Redis Cluster具有分布式系统的特点,也具有分布式系统如
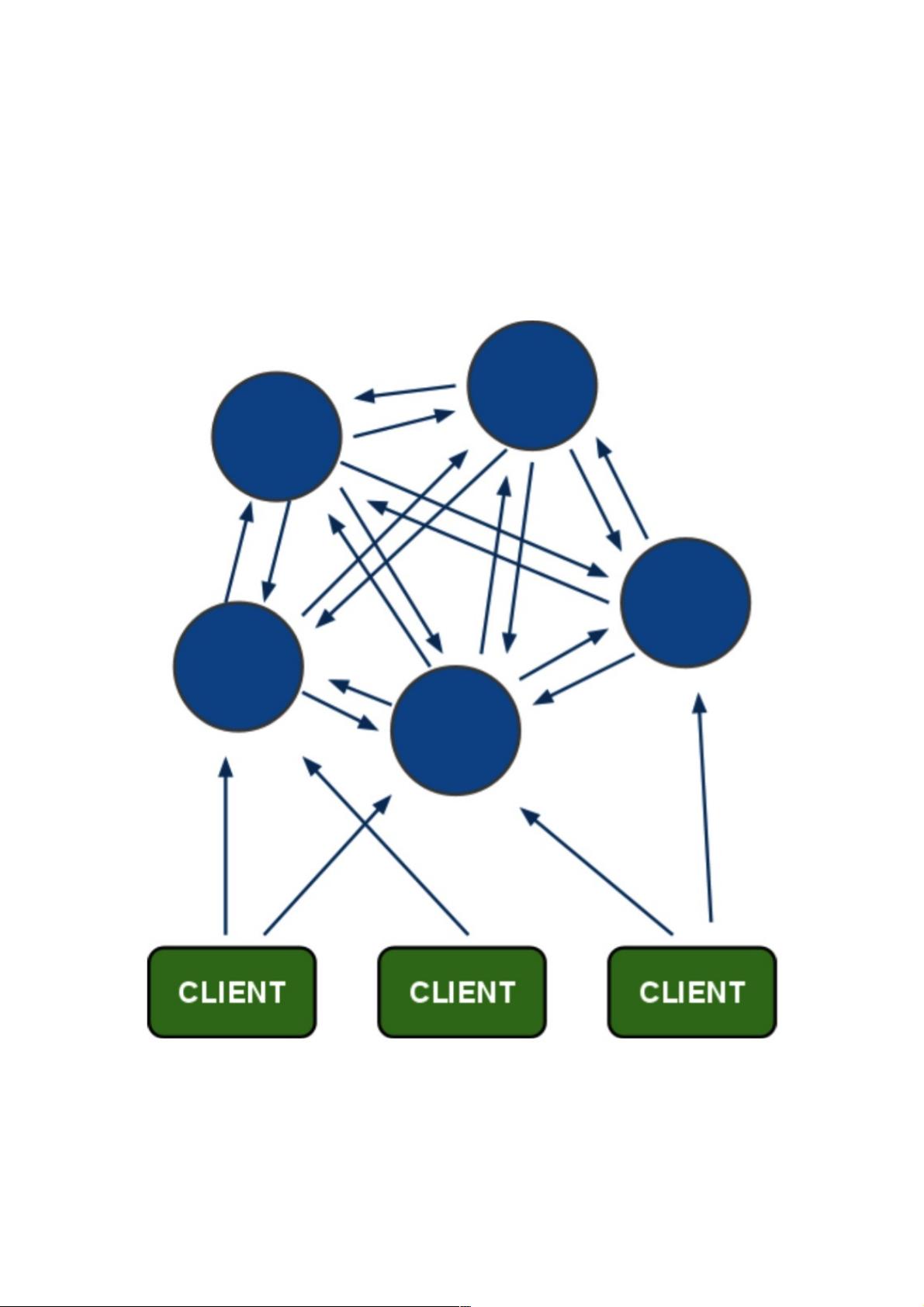
何实现高可用性与数据一致性的难点,由多个Redis实例组成的Redis Cluster结构通常如下:
Redis Cluster
Redis Cluster特点如下:
所有的节点相互连接;
集群消息通信通过集群总线通信,,集群总线端口大小为客户端服务端口+10000,这个10000是固定值;
节点与节点之间通过二进制协议进行通信;
客户端和集群节点之间通信和通常一样,通过文本协议进行;
下载后可阅读完整内容,剩余4页未读,立即下载
相关推荐






weixin_38686080
- 粉丝: 2
- 资源: 963
 我的内容管理
展开
我的内容管理
展开







最新资源
- 【容智iBot】8iBot=RPA+AI:数字化生产力为企业赋能.rar
- 操作系统课件+实验.rar_mightpol_wonsps_操作系统_操作系统实验
- TestYo:测试
- iocage-plugin-zabbix5-server
- 时代变频器在纺织机械行业中的应用.rar
- 【容智iBot】7你知道AI人工智能对我们的意义吗?.rar
- gimp-plugin-pixel-art-scalers:Gimp插件,用于使用hqx,xbr和scalex等Pixel Art Scalers重新缩放图像
- SpringBoot2.7整合SpringSecurity+Jwt+Redis+MySQL+MyBatis完整项目代码
- tarsnapper:tarsnap包装器,使用gfs-scheme使备份失效
- HC110110017 链路状态路由协议-OSPF-ospf.rar
- AreSolutionsClinicMobile:Spring世博会命令行界面,API消费和Spring启动
- Map-Fu-开源
- webbrowser自动填表,并获取网页源码(iframe框架也可获取网页源码)
- janeway::milky_way:具有对象检查和许多其他功能的Node.js控制台REPL
- 批量单词翻译
- indicator:财务指标(EMA,MACD,SMA)
