分布式环境下的缓存与数据库一致性优化策略
需积分: 45 131 浏览量
更新于2024-09-10
收藏 317KB DOCX 举报
本文主要围绕"缓存与数据库一致性保证"这一主题展开深入讨论,重点关注在分布式系统中数据库和缓存数据可能存在的不一致问题以及相关的优化策略。首先,文章指出当数据变化时,由于操作缓存和数据库的非原子性,可能会出现数据不一致的情况。具体来说,如果先写数据库再淘汰缓存,如果写数据库操作成功但淘汰缓存失败,会导致数据在数据库和缓存中不一致;反之,如果先淘汰缓存再写数据库,虽然缓存可能会缺失,但至少不会立即引入不一致。
数据不一致的主要原因是分布式环境下的并发读写操作。在多个应用并发访问同一数据时,即使数据库层面的并发不能保证操作顺序,后发出的请求可能先完成并读取到尚未更新的数据,从而造成脏数据进入缓存,形成不一致。例如,读请求B可能在写请求A更新数据之前读取到了旧值。
针对这种不一致性,文章提出优化思路之一是采用“串行化”策略。串行化意味着对并发操作进行有序调度,确保先发出的请求在写入数据库并更新缓存之后被处理。这通常涉及到事务管理和锁机制,例如在分布式环境中可能需要使用乐观锁或悲观锁来控制并发操作,确保数据一致性。此外,还有一些其他技术,比如使用版本号、TTL过期策略或者缓存预热等,可以减少数据不一致的可能性。
总结来说,本文深入剖析了数据库和缓存一致性问题的根源,并介绍了如何通过优化策略如串行化来降低不一致的风险,这对于理解和维护大规模分布式系统的正确性和性能至关重要。通过理解和实践这些技术,开发人员可以更好地设计和管理缓存架构,确保在高并发场景下提供一致且高效的用户体验。
本文主要讨论这么几个问题:
(1)啥时候数据库和缓存中的数据会不一致
(2)不一致优化思路
(3)如何保证数据库与缓存的一致性
一、需求缘起
上一篇《缓存架构设计细节二三事》(点击查看)引起了广泛的讨论,其中有一个结论:当数据发
生变化时,“先淘汰缓存,再修改数据库”这个点是大家讨论的最多的。
上篇文章得出这个结论的依据是,由于操作缓存与操作数据库不是原子的,非常有可能出现执行失
败。
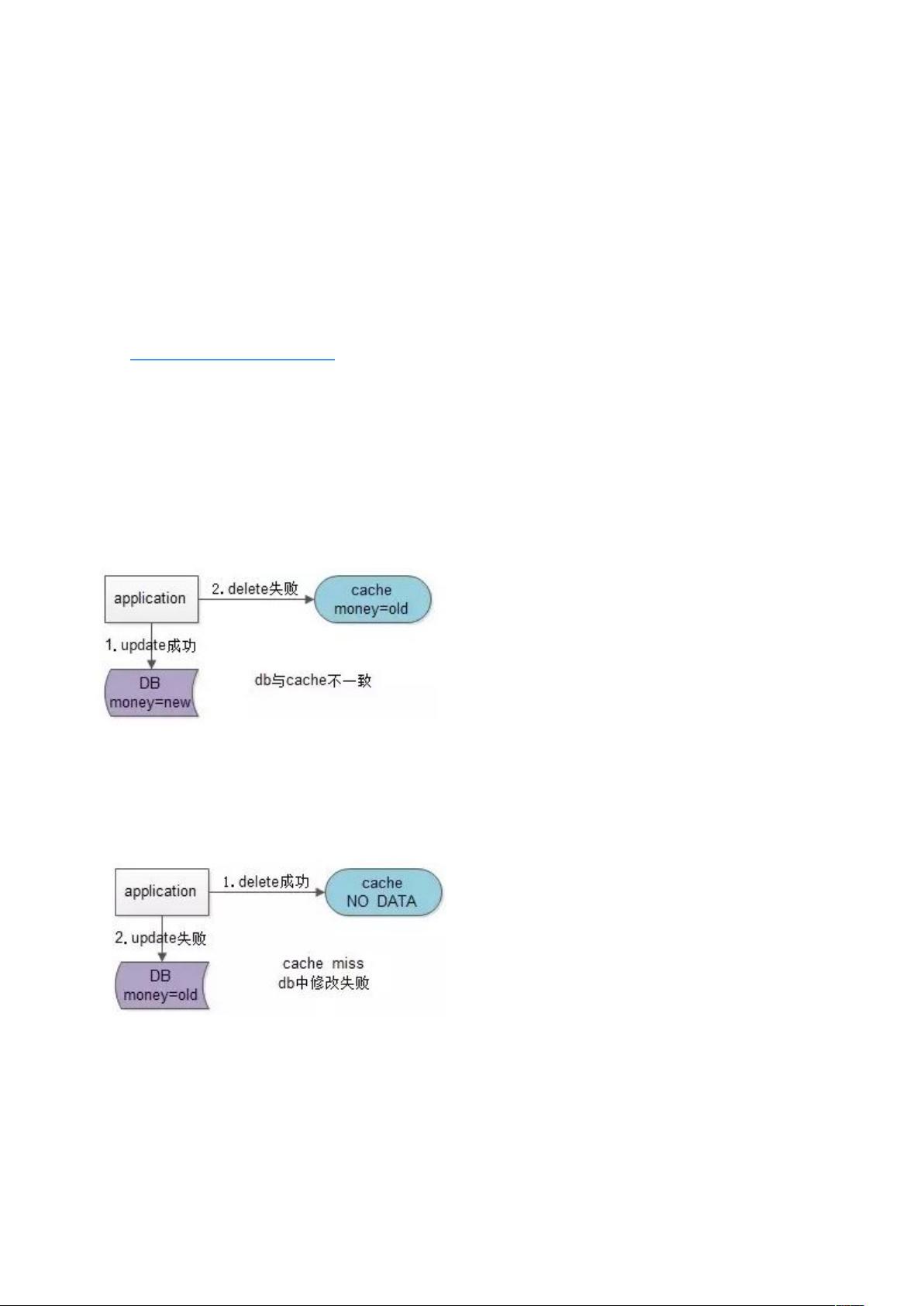
假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现 DB 中
是新数据,Cache 中是旧数据,数据不一致【如上图:db 中是新数据,cache 中是旧数据】。
假设先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次
Cache miss【如上图:cache 中无数据,db 中是旧数据】。
结论:先淘汰缓存,再写数据库。
下载后可阅读完整内容,剩余7页未读,立即下载
2021-01-07 上传
2022-08-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-04-01 上传
2023-05-10 上传
2022-07-09 上传

hyy80688
- 粉丝: 10
- 资源: 202
 我的内容管理
展开
我的内容管理
展开







最新资源
- 情感分类器
- MemoryTest.rar_数值算法/人工智能_Visual_C++_
- sketch-data-super-heroes::male_sign::male_sign:此存储库包含适用于Sketch设计师的超级数据集
- 人工智能五子棋.zip
- HotApplet-开源
- matlab心线代码-ECG-electrocardiogram:这是使用PIC18F4550微处理器创建的ECG
- Codeflix
- tv-shows-nextjs:电视节目与Next.js一起使用
- 小白简约浏览器界面.zip
- led-matrix-art:PIXEL控制台应用程序的更好的Web界面
- ADEL-WEB
- TicketKit是一个可以轻松创建票证或优惠券的框架-Swift开发
- 人工智能社会保险反欺诈分析-rank26.zip
- center.rar_教育系统应用_Visual_C++_
- Elenco-crx插件
- admissionClassification
