Apache Flink Python API 深入解析与未来展望
8 浏览量
更新于2024-07-15
收藏 1.64MB PDF 举报
"Apache Flink Python API 的使用、发展历史及未来规划,包括API的架构、开发环境搭建和核心算子的应用。文章来源于Apache Flink系列直播课程,由Flink PMC、阿里巴巴高级技术专家孙金城分享。"
Apache Flink 是一款强大的开源大数据计算引擎,支持流处理和批处理的统一。在Flink 1.9.0版本中,它引入了新的机器学习接口和针对Python的API,以满足开发者对Python语言日益增长的需求。Python作为编程界的热门语言,因其易学易用的特性深受开发者喜爱,特别是在大数据和机器学习领域。
Flink支持Python API的主要原因有以下几点:
1. **流行度高**:Python是继Java和JavaScript后的第三大受欢迎的编程语言,这使得大量开发者熟悉并愿意使用Python。
2. **生态系统完善**:许多知名的大数据开源项目,如Hadoop、Spark、Hive等,都提供了Python支持,构建了一个完整的Python大数据生态。
3. **机器学习的首选**:在机器学习领域,Python占据了重要的地位,许多机器学习岗位的需求都倾向于使用Python。
4. **易用性**:Python的简洁语法和单一实现方式使其成为开发者首选的语言,尤其对于新进开发者而言,Python降低了学习和使用的门槛。
Apache Flink的Python API(PyFlink)旨在提供与Java API相当的功能,并且让Python开发者能够充分利用Flink的流批处理能力。PyFlink的架构设计考虑了性能和兼容性,允许用户利用Python的生态系统,如pandas库进行数据处理。
在开发环境搭建方面,通常需要安装Flink的Python SDK,配置环境变量,以及设置Python版本和依赖库。用户可以通过PyFlink提供的接口创建流处理或批处理作业,定义数据源、转换操作和数据Sink。
PyFlink的核心算子包括数据源(Source)、转换操作(Transformation)和数据Sink(Sink)。数据源可以是各种数据流,如Kafka、HDFS等;转换操作涵盖过滤、窗口、聚合等多种数据处理功能;数据Sink则负责将处理后的结果输出到目标系统,如数据库、文件系统等。
在未来规划中,Apache Flink将继续优化Python API,提高性能,增强对Python生态系统的支持,以及提供更丰富的机器学习和数据科学工具集成。随着Flink社区的不断发展,PyFlink将成为Python开发者进入实时大数据处理领域的重要桥梁。
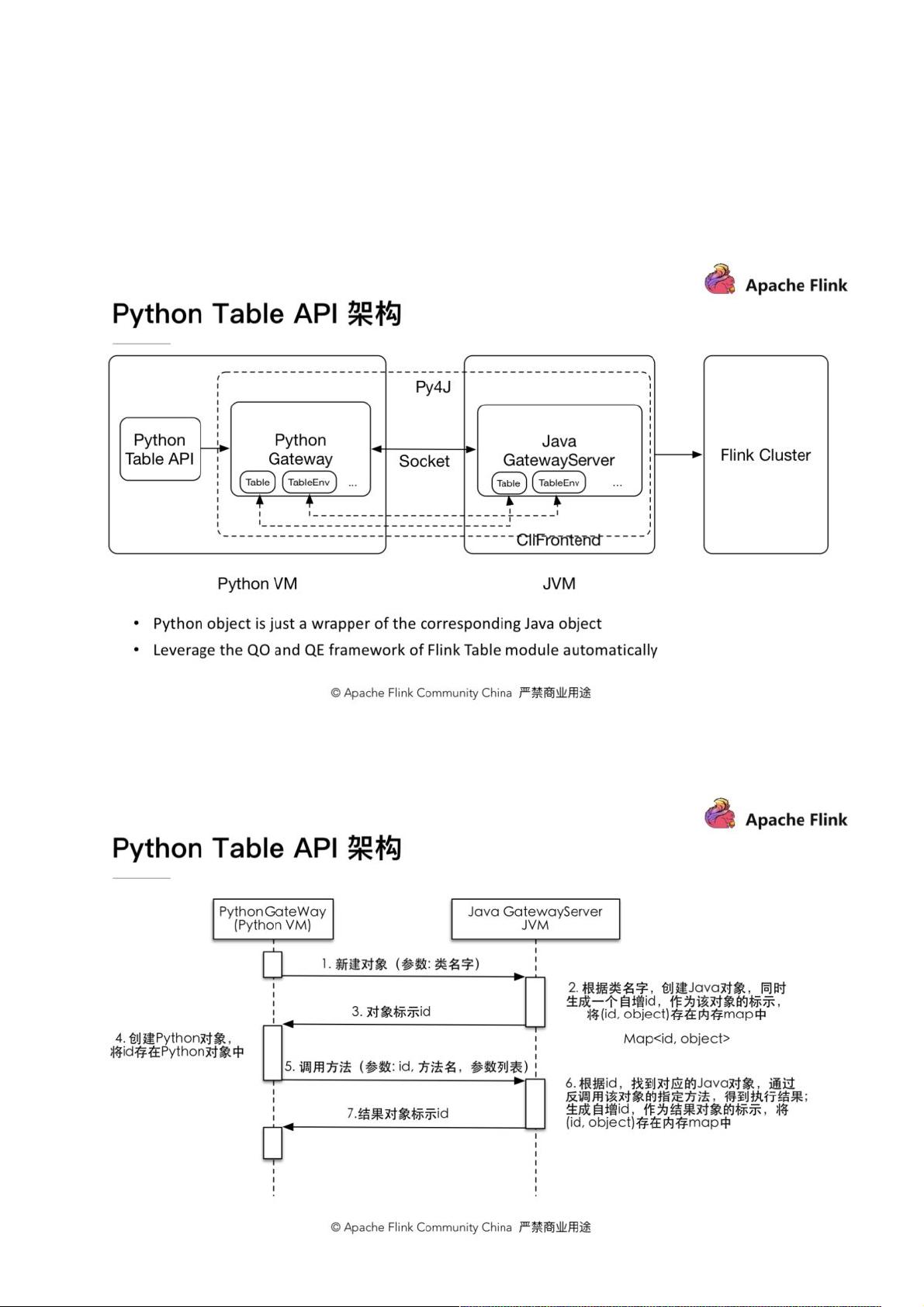
两套不同的 API。
对于 Flink 这样一个流批统一的流式计算引擎来讲,统一的架构至关重要。并且对于已有的 Python DataSet API 和 DataStream API 而言,采用了
JPython 的技术体系架构,而 JPython 本身对目前 Python 的 3.X 系列无法很好的支持,所以所以 Flink 1.9 发布后,决定将原有的发布后,决定将原有的 Python API 体系架构废体系架构废
弃,以全新的技术架构出现。弃,以全新的技术架构出现。这套全新的 Python API 基于 Table API 之上。
Table API 和 Python API 之间的通讯采用了一种简单的办法,利用 Python VM 和 Java VM 进行通信。在 Python API 的书写或者调用过程中,以某种方
式来与 Java API 进行通讯。操作 Python API 就像操作 Java 的 Table API一样。新架构中可以确保以下内容:
不需要另外创建一套新的算子,可以轻松与 Java 的 Table API 的功能保持一致;
得益于现有的 Java Table API 优化模型,Python 写出来的API,可以利用 Java API 优化模型进行优化,可以确保 Python 的 API 写出来的 Job 也能够具
备极致性能。
如图,当 Python 发起对Java的对象请求时候,在 Java 段创建对象并保存在一个存储结构中,并分配一个 ID 给 Python 端,Python 端在拿到 Java 对象
的 ID 后就可以对这个对象进行操作,也就是说 Python 端可以操作任何 Java 端的对象,这也就是为什么新的架构可以保证Python Table API 和 Java
Table API功能一致,并且能过服用现有的优化模型。
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-12-23 上传
2015-10-30 上传
2021-05-14 上传
点击了解资源详情
2023-06-07 上传
点击了解资源详情

weixin_38670529
- 粉丝: 3
- 资源: 927
 我的内容管理
展开
我的内容管理
展开







