Numba:加速Python数据并行编程的高性能解决方案(2014年)
110 浏览量
更新于2024-07-14
收藏 628KB PDF 举报
在2014年3月24日的演讲"Extending Python for High-performance Data-Parallel Programming"中,Siu Kwan Lam探讨了如何利用Python进行高效的数据并行编程,尽管Python以其高级脚本语言特性如动态类型、垃圾回收和快速开发而闻名,但在处理大规模数据处理和并行计算时存在挑战。Python的库丰富多样,包括用于数组操作的NumPy和Blaze,科学计算的SciPy和Scikit-Learn,以及数据可视化工具Matplotlib和Bokeh,使其成为数据分析的理想选择。然而,全局解释器锁(GIL)限制了Python的并发性能,导致执行速度较慢。
为了解决这些问题,演讲者提出了Numba,一个针对CPython的开源即时编译器。Numba的关键在于将数值循环转换为快速的原生代码,使得Python程序能够绕过Python运行时环境,从而消除GIL的限制。Numba与NumPy无缝集成,允许编写无需依赖Python解释器的代码,显著提升了性能。
Numba的编译流程包括将Python字节码转化为低级中间表示(LLVM),然后进一步优化和转换为机器特定的原生代码。这个过程涉及到高阶分析和本地类型推断,确保了在编译期间确定变量类型,从而实现高效的并行执行。Numba的一个核心优势是可以根据参数类型进行特殊化,例如,针对变量`a`指定特定的类型,以进一步提升代码的性能。
Numba提供了两种主要的接口:低级别的CUDA Python,适用于GPU加速,最近已经发布了开源版本;以及高层次的面向数组的接口,使得Python程序员可以更方便地利用并行计算资源。通过Numba,开发者得以在Python中实现真正的并行编程,极大地扩展了其在高性能数据处理场景中的应用潜力。
总结来说,该演讲介绍了如何通过Numba技术克服Python在并行计算上的局限,使Python成为了一个更适合高性能数据处理的工具,并强调了它在提升性能、支持多种编程入口点(包括GPU支持)方面的价值。这不仅提高了Python在大数据和科学计算领域的实用性,也展示了如何通过扩展语言来适应不断增长的性能需求。
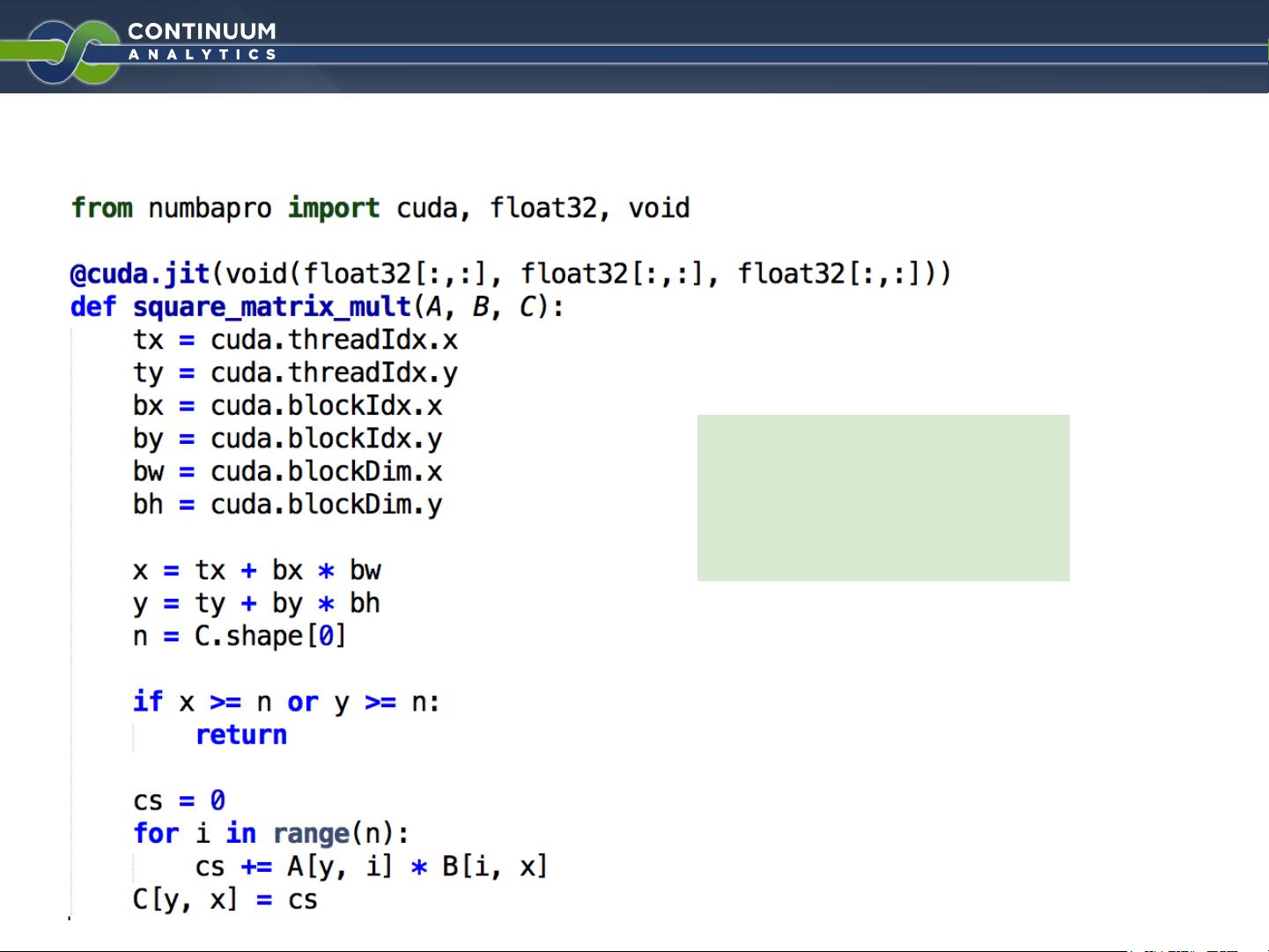
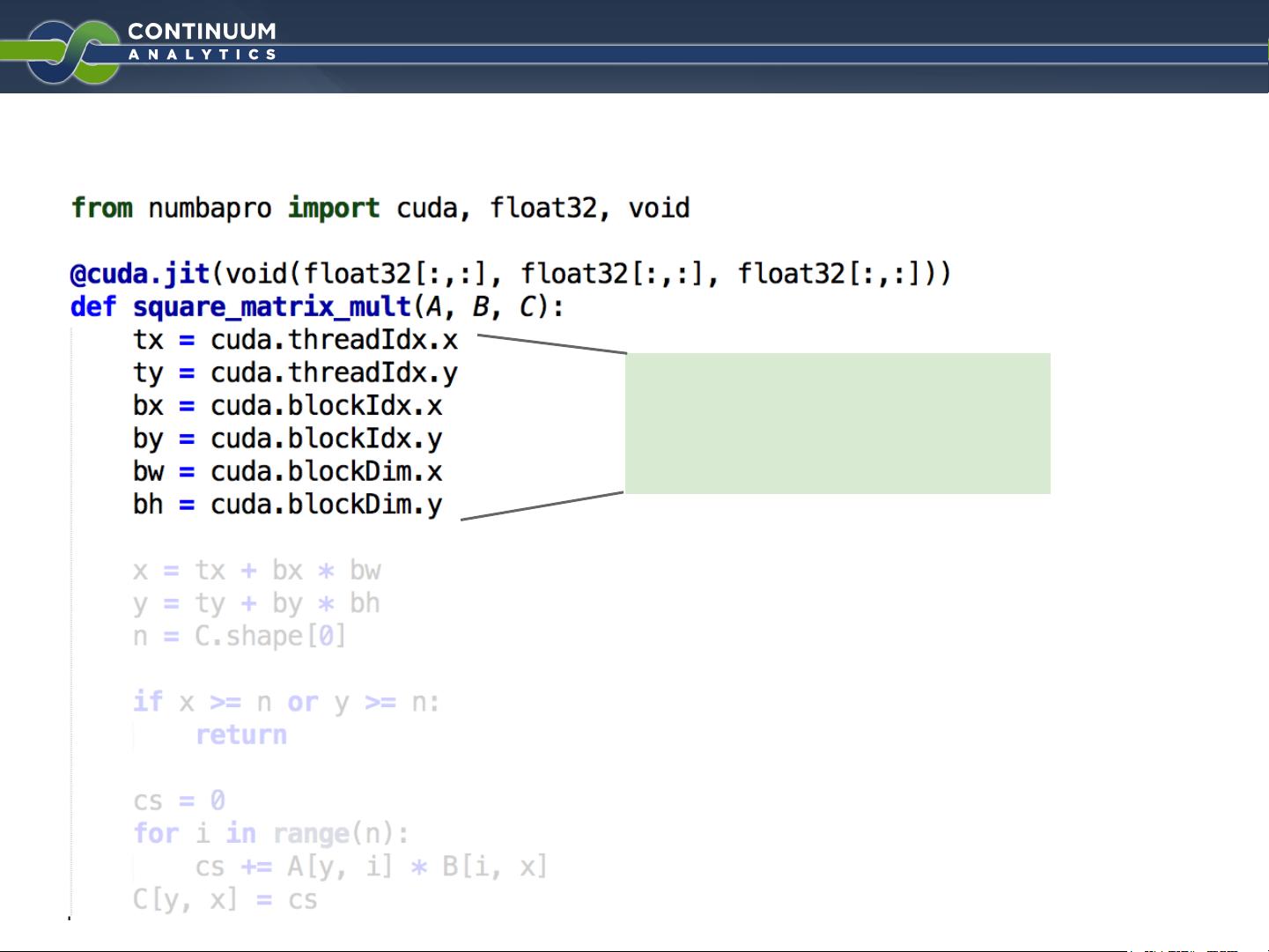
NumbaPro “CUDA Python”
Square matrix
multiplication
剩余48页未读,继续阅读
2024-07-03 上传
2021-08-07 上传
2021-04-12 上传
2009-05-14 上传
2019-02-12 上传
2009-06-28 上传
2020-05-28 上传
2021-04-22 上传
2021-05-08 上传

weixin_38726441
- 粉丝: 4
- 资源: 907
 我的内容管理
展开
我的内容管理
展开







