正则表达式完全指南:语法、示例与最佳实践
需积分: 1 171 浏览量
更新于2024-08-03
收藏 408KB PDF 举报
"正则表达式是用于处理文本的强大工具,它通过特殊的语法来描述字符串的模式。本文将深入解析正则表达式的语法和常见用法。"
正则表达式,全称为正则(规)表达式或正则元字符序列,是一种用于匹配和操作文本字符串的模式匹配语言。它在编程、数据分析、文本处理和自动化任务中广泛使用。正则表达式的核心概念包括元字符、字符类、转义序列、捕获组和零宽断言。
1. **元字符**:元字符是具有特殊含义的字符,它们在正则表达式中起到特殊作用。例如:
- `.` 表示任意单个字符,除了换行符。
- `*` 表示前面的字符可以出现零次或多次。
- `+` 表示前面的字符必须出现一次或多次。
- `?` 表示前面的字符可以出现零次或一次。
- `^` 在字符串开始处表示匹配,而在字符类内部表示非该字符。
- `$` 在字符串结束处表示匹配。
2. **字符类**:字符类是用方括号`[]`包围的一组字符,表示匹配其中任意一个字符。例如,`[aeiou]`匹配所有元音字母。
3. **转义序列**:转义序列以`\`开始,用于表示特定的字符。`\d`代表任意数字字符,`\s`代表空白字符(如空格、制表符等),`\b`表示单词边界,`\A`表示字符串的开始,`\Z`表示字符串的结束。
4. **捕获组**:通过使用圆括号`()`,我们可以创建捕获组,捕获匹配的子串,这对于提取或替换特定部分的文本非常有用。
5. **零宽断言**:这些特殊符号不消耗字符,而是检查当前位置是否满足特定条件。例如,`\b`匹配单词边界,`\A`和`\Z`分别表示字符串的开始和结束,而`(?=pattern)`和`(?!pattern)`是前瞻断言,分别表示接下来的字符应匹配和不应匹配`pattern`。
在使用正则表达式时,需要注意以下几个方面:
- 避免过于复杂的表达式,这可能会影响性能并增加维护难度。
- 根据所使用的编程语言或环境,选择适当的正则表达式语法和元字符,因为不同语言对正则表达式的支持可能略有不同。
- 对于复杂表达式,建议分步骤构建,逐步测试和调试,以确保其符合预期功能。
了解这些基础知识后,你可以创建各种正则表达式来处理和验证文本,例如查找特定格式的电子邮件地址、验证电话号码格式或从大量文本中提取特定信息。正则表达式的灵活性和强大功能使其成为任何开发者工具箱中的必备武器。
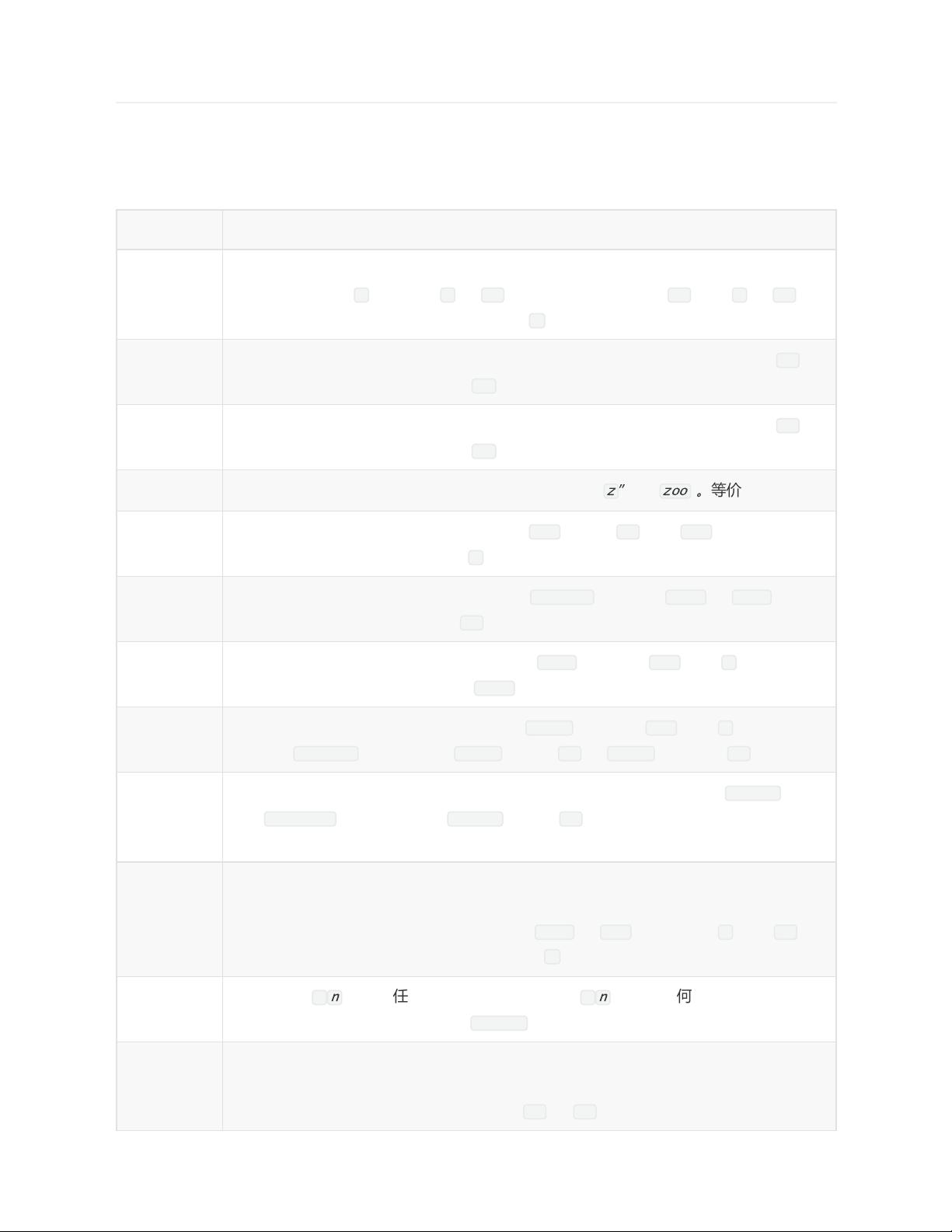
字符 描述
\
将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制
转义符。例如,“ n ”匹配字符“ n ”。“ ”匹配一个换行符。串行“ \ ”匹配“ \ ”而“ \( ”则
匹配“ ( ”。
^
匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“ ”或
“ ”之后的位置。
$
匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“ ”或
“ ”之前的位置。
* 匹配前面的子表达式零次或多次。例如,zo
能匹配
“
z
”
以及
“
zoo
”
。
等价于{0,}。
+
匹配前面的子表达式一次或多次。例如,“ zo+ ”能匹配“ zo ”以及“ zoo ”,但不能匹配
“ z ”。+等价于{1,}。
?
匹配前面的子表达式零次或一次。例如,“ do(es)? ”可以匹配“ does ”或“ does ”中的
“ do ”。?等价于{0,1}。
{n}
n是一个非负整数。匹配确定的n次。例如,“ o{2} ”不能匹配“ Bob ”中的“ o ”,但是能匹
配“ food ”中的两个o。
{n,}
n是一个非负整数。至少匹配n次。例如,“ o{2,} ”不能匹配“ Bob ”中的“ o ”,但能匹配
“ foooood ”中的所有o。“ o{1,} ”等价于“ o+ ”。“ o{0,} ”则等价于“ o* ”。
{n,m}
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“ o{1,3} ”将匹
配“ fooooood ”中的前三个o。“ o{0,1} ”等价于“ o? ”。请注意在逗号和两个数之间不能
有空格。
?
当该字符紧跟在任何一个其他限制符(,+,?
,
{n}
,
{n,}
,
{n,m*})后面时,匹配模式是
非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多
的匹配所搜索的字符串。例如,对于字符串“ oooo ”,“ o+? ”将匹配单个“ o ”,而“ o+ ”将
匹配所有“ o ”。
.
匹配除“ \
n
”之外的任何单个字符。要匹配包括“ \
n
”在内的任何字符,请使用像
“ (.|) ”的模式。
(pattern)
匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在
VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字
符,请使用“ \( ”或“ \) ”。
1. 正则表达式的基础知识
正则表达式是一种由普通字符(例如字母和数字)以及特殊字符组成的字符串,这些特殊字符用来指示模式
或者规则。例如,"^a" 表示以字母"a"开头的字符串,"a$" 表示以字母"a"结尾的字符串,"a*" 表示包
含"a"的任意长度的字符串等。
下载后可阅读完整内容,剩余9页未读,立即下载
2013-09-13 上传
2018-11-07 上传
2010-05-10 上传
2024-05-08 上传
2023-03-31 上传
2024-08-08 上传
2023-06-06 上传
2024-10-26 上传
2024-10-27 上传

孤蓬&听雨
- 粉丝: 2w+
- 资源: 400
 我的内容管理
展开
我的内容管理
展开







最新资源
- NeuMedia:一个简单易用的高级媒体播放器-开源
- 行业分类-设备装置-跨分布式控制系统服务器的实时事件查看.zip
- techsith-redux
- 飞翔的小鸟java源码-java:Java
- 30daysofdev:开发30天的官方网站
- 约会管理系统
- 华为简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- EDGER:创建用于测量恒星流出腔的半张角的算法
- 数据可视化驾驶舱-07.zip
- shop:商家和客户的Payngolinky前端
- 自己常用shader(自连).zip
- 21本搜索书
- snippits
- ndef-tools-for-android:从 code.google.compndef-tools-for-android 自动导出
- mw1utils:mw1utils:Waldorf微波工具-开源
- Andersnormal.us
