盈建科YJK-Revit双向数据转换接口详解
需积分: 9 194 浏览量
更新于2024-07-21
收藏 9.87MB PDF 举报
"盈建科结构设计软件系统通过REGIT数据转换接口实现了与Autodesk Revit的双向数据转换,解决了结构专业在BIM应用中的协同难题。该接口基于Revit API进行二次开发,能处理复杂模型,包括特殊截面、斜构件、跃层结构等,并具备强大的纠错机制,适合大规模模型的转换。转换过程包括YJK模型导出数据、启动Revit导入数据以及在Revit中应用转换结果,如生成立、剖面图和构件统计。通过多个复杂模型转换实例,如老虎窗屋顶、塔状模型、桥梁模型和大型展馆,展示了接口在实际项目中的高效应用。"
详细说明:
"REGIT数据转换"是一个专为结构设计软件YJK和Autodesk Revit之间构建的数据接口,目的是实现两个软件之间的数据双向互转,消除结构专业在BIM(建筑信息模型)流程中的信息孤岛。Revit是一款广泛使用的建筑信息建模工具,而YJK则专注于结构设计。由于国内BIM技术的快速发展,结构计算模型与设计模型的协同成为了一个挑战,盈建科软件以用户需求为导向,开发了此数据转换接口。
接口利用Revit的API进行二次开发,适应Revit Structure 2012版本,作为Revit的一个插件运行。它创建与结构计算模型截面一致的参数族,自动调整模型规则,确保两平台间的数据一致性。在转换过程中,接口能处理各种复杂情况,例如特殊截面(如复杂截面柱、梁)、斜撑、斜柱、斜梁、斜板、跃层构件、层间梁、剪力墙、墙洞、楼板、板洞、弧墙和弧梁。此外,接口还具备良好的纠错机制,能自动处理模型截面重复定义、翼缘长度为零、复杂相交关系、偏心、偏轴等问题,即使在处理大量高层模型时也能保持高效。
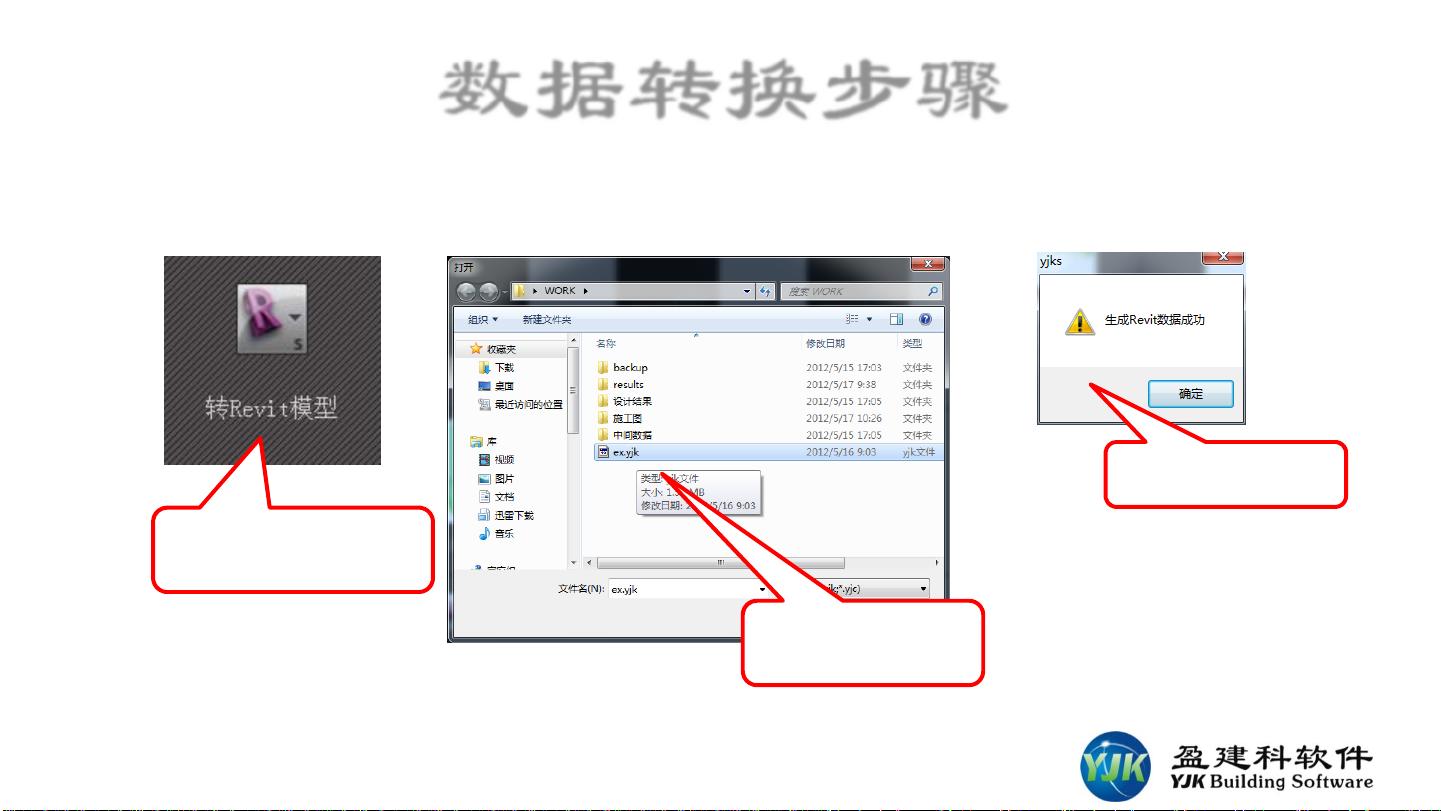
数据转换步骤分为三步:首先,用户在YJK启动页面选择模型文件并导出数据;其次,启动Revit并导入生成的数据文件;最后,用户可以选择转换的构件和楼层,对于复杂模型可以分次或按楼层导入。转换完成后,用户可以在Revit中进一步操作,如生成立面和剖面图,进行构件统计,以验证和利用转换结果。
通过一系列复杂模型转换实例,如老虎窗屋顶、塔状结构、桥梁模型和大型展馆等,展示了接口在实际工程项目的实用性。这些实例证明了REGIT数据转换接口能够有效地将YJK的结构设计模型转换为Revit的建筑信息模型,实现了结构专业在BIM环境中的无缝协作。


点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

cj1289036286
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Canteen-Automation-App:一个食堂自动化应用程序,用于使手动食堂管理系统自动化
- zxing-cpp:ZXing的C ++端口
- Windows server2008R2 补丁kb4474419-v3-x64
- CognitiveRocket:此存储库主要用于Bot,Power Platform,Dynamics 365,Cognitive Services和ML.NET的研发。
- pouchdb-all-dbs:PouchDB的allDbs()插件
- FromJson
- Dahouet-Repository
- Cyclist
- endlessArrayPromise
- GEO82_5_HE
- workberch-tolopogy:由 Taverna Workbench 上的工作流文件创建的动态 Apache Storm 拓扑
- Surface-Crack-Detection-CNN:使用CNN对Kaggle上可用的图像数据进行表面裂纹检测。 该存储库将在Streamlit中同时具有“模型实现”和“ Web应用程序”,用于检测裂缝
- AppiumTest
- COMP397-W2021-Lesson8a
- 使用TensorFlow.js进行AI聊天机器人:训练Trivia Expert AI
- bdmap
