Hadoop入门指南:分布式文件系统与MapReduce解析
需积分: 10 121 浏览量
更新于2024-07-27
收藏 1.09MB PDF 举报
"Hadoop 教程 - OSSEZ.COM"
Hadoop 是一个开源框架,主要用于存储和处理大数据。本教程由 OSSEZ LLC (USA) 和 OSSEZ (中国) 信息技术有限公司提供技术支持,旨在帮助读者理解并掌握 Hadoop 的核心组件——Hadoop 分布式文件系统 (HDFS) 和 MapReduce 模型。
1. **Hadoop 的背景与挑战**
- **适用问题范围**: Hadoop 适用于处理和存储海量非结构化数据,如日志、图像和文本。
- **大规模的挑战**: 随着数据量的爆炸式增长,传统的单机处理方式已无法满足需求,Hadoop 提供了一种分布式解决方案。
- **摩尔定律**: 随着计算能力的提升,数据处理的需求也在同步增长,Hadoop 应运而生,以应对不断膨胀的数据规模。
- **Hadoop 方法**: 通过分布式计算模型,Hadoop 可以在多台廉价硬件上并行处理数据,实现高可用性和可扩展性。
- **与现有方法比较**: 相比传统的数据库和并行计算系统,Hadoop 更加灵活且成本效益高。
- **数据分布**: Hadoop 使用分布式文件系统,将大文件分割成块,分散存储在集群中的不同节点上。
- **MapReduce**: 这是 Hadoop 的核心计算模型,通过“映射”和“化简”阶段处理数据。
2. **Hadoop 分布式文件系统 (HDFS)**
- **分布式文件系统基础**: HDFS 设计为容错性高,能处理硬件故障,保证数据的可靠存储。
- **配置 HDFS**: 用户需要配置 HDFS 参数以适应特定的集群环境。
- **集群配置**: 包括节点设置、网络拓扑和存储策略等。
- **启动 HDFS**: 通过一系列命令启动 NameNode 和 DataNodes。
- **与 HDFS 交互**: 用户可以通过命令行或编程接口读写文件。
- **常用操作示例**: 如列出文件、上传数据、下载数据以及停止 HDFS 服务。
- **HDFS 命令参考**和**DFSAdmin 命令参考**: 提供了管理和维护 HDFS 的工具。
3. **MapReduce 基础**
- **函数式编程概念**: MapReduce 基于函数式编程思想,简化分布式计算。
- **列表处理**: 数据以列表形式输入,MapReduce 将其作为基本操作单元。
- **映射 (Mapping)**: 将输入数据转换为键值对,预处理数据。
- **化简 (Reducing)**: 对映射阶段产生的键值对进行聚合,生成最终结果。
- **应用例子 - 词频统计 (WordCount)**: 一个经典的 MapReduce 示例,统计文本中单词出现的次数。
- **驱动方法**: 控制整个 MapReduce 工作流程,包括数据读取、映射、化简和结果写回。
- **MapReduce 数据流**: 映射、排序、化简的执行过程,确保正确性和顺序。
- **近距离观察**: 揭示 MapReduce 的内部工作机制,如数据分区和任务调度。
- **容错性**: Hadoop 的 MapReduce 具有内置的容错机制,如数据备份和任务重试。
- **额外的 MapReduce 功能**: 包括 Combiner、Partitioner 和 JobTracker 等高级特性。
本教程深入浅出地介绍了 Hadoop 的核心概念和操作,对于想要了解或使用 Hadoop 的初学者来说,是一个宝贵的资源。通过学习 HDFS 的管理与 MapReduce 的编程模型,读者可以构建自己的大数据处理系统,解决实际业务中的大数据挑战。

1.4 Hadoop 方法
Hadoop 方法设计目的是将许多普通计算机连接起来并行地处理大量信息。一个上
面提到的 1000-CPU 的机器,比之 1000 个单核或 250 个四核机器的价格要高出许
多,Hadoop 将会将这些小型的低廉的机器连接起来成为一个性价比高的计算机集
群。
1.5 与现有方法比较
在大规模数据上进行分布式计算以前也是有的。Hadoop 的独特之处在于它简单的
编程模型,它可使用户很快地编写和测试分布式系统,和它高效,自动分布数据和
工作到不同机器的方式,以及利用多核并行处理。
计算机的网络调度可以用其它系统,比如 Condor,但 Condor 不能自动分布数据:
必须管理一个单独的 SAN,不止如此,多个结点的协作也必须管理交互系统,如
MPI,这种编程模型极难掌握,并且会引起一些难以理解的错误。
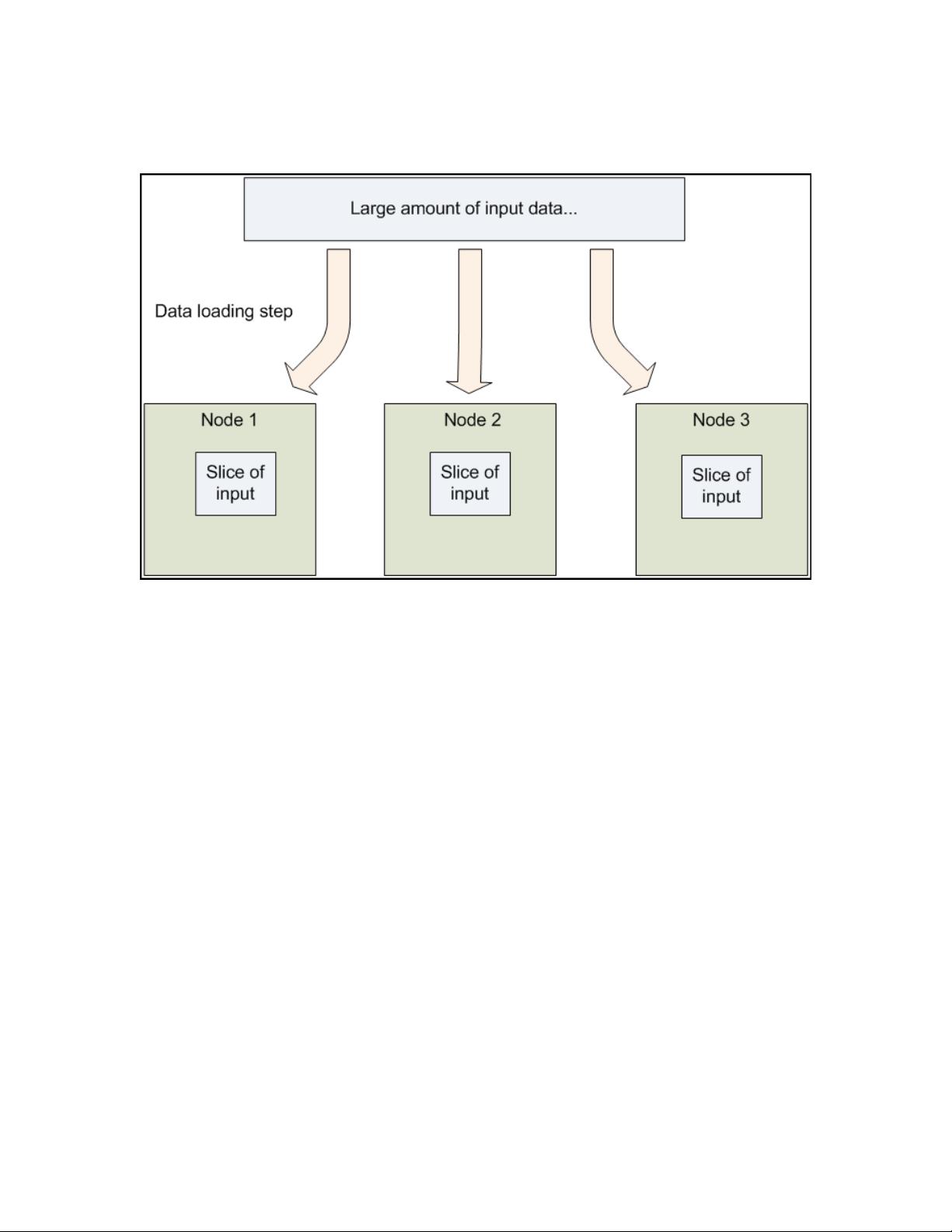
1.6 数据分布
在 Hadoop 集群中,数据被分布到集群的各个结点,Hadoop Distributed File
System (HDFS)将大的数据文件分成块,将这些块交由集群中的结点处理,并且每
个块都会复制到不同的几个机器上,所以一台机器崩溃不会导致数据丢失,监测系
统会对结点崩溃做出反应,重新复制数据,即部分存储(partial storage)。即便文件
块被复制分布到不同的机器,但它们形成了一个单一的命名空间,所以它们的内容
还是全局可访问的。
在 Hadoop 的编程框架中,概念上来说,数据是面向记录的。每个输入文件都被以
行或其它特定的应用逻辑格式分开。集群中的每个结点的每个进程都会处理这分开
文件的一部分,Hadoop 框架再根据分布式文件系统的信息调试进程到数据/记录
的位置,因为文件以块的形式存在于分布式文件系统中,每个结点上的每个计算进
程处理数据的一个子集。哪些数据要被一个结点处理是由数据本身的存放位置决定
的。大部分数据是直接地从磁盘读入 CPU,这减少了网络带宽的限制,也防止了
OSSEZ.COM-v1.0-技术模板简易版.ott 2012-09-10
版权所有 © OSSEZ LLC 2006 - 2012 7 / 38
剩余37页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-11-16 上传
2010-07-11 上传
2017-01-12 上传
2017-12-08 上传

HoneyMoose
- 粉丝: 1792
- 资源: 271
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
