SparkSQL 1.3.0:DataFrameAPI提升易用性,兼容扩展能力强
122 浏览量
更新于2024-08-30
收藏 219KB PDF 举报
Spark SQL 1.3.0版本的发布标志着该工具在易用性和兼容性方面取得了重大进步。首先,DataFrame API的引入是其核心亮点。相比于传统的RDD API,DataFrame显著提升了易用性,尤其对没有MapReduce和函数式编程经验的开发者来说,降低了学习曲线。DataFrame的设计灵感来源于R和Pandas这样的数据科学框架,提供了类似的数据操作接口,不仅支持Scala、Java和Python等多种语言,而且非常适合大规模分布式数据处理。
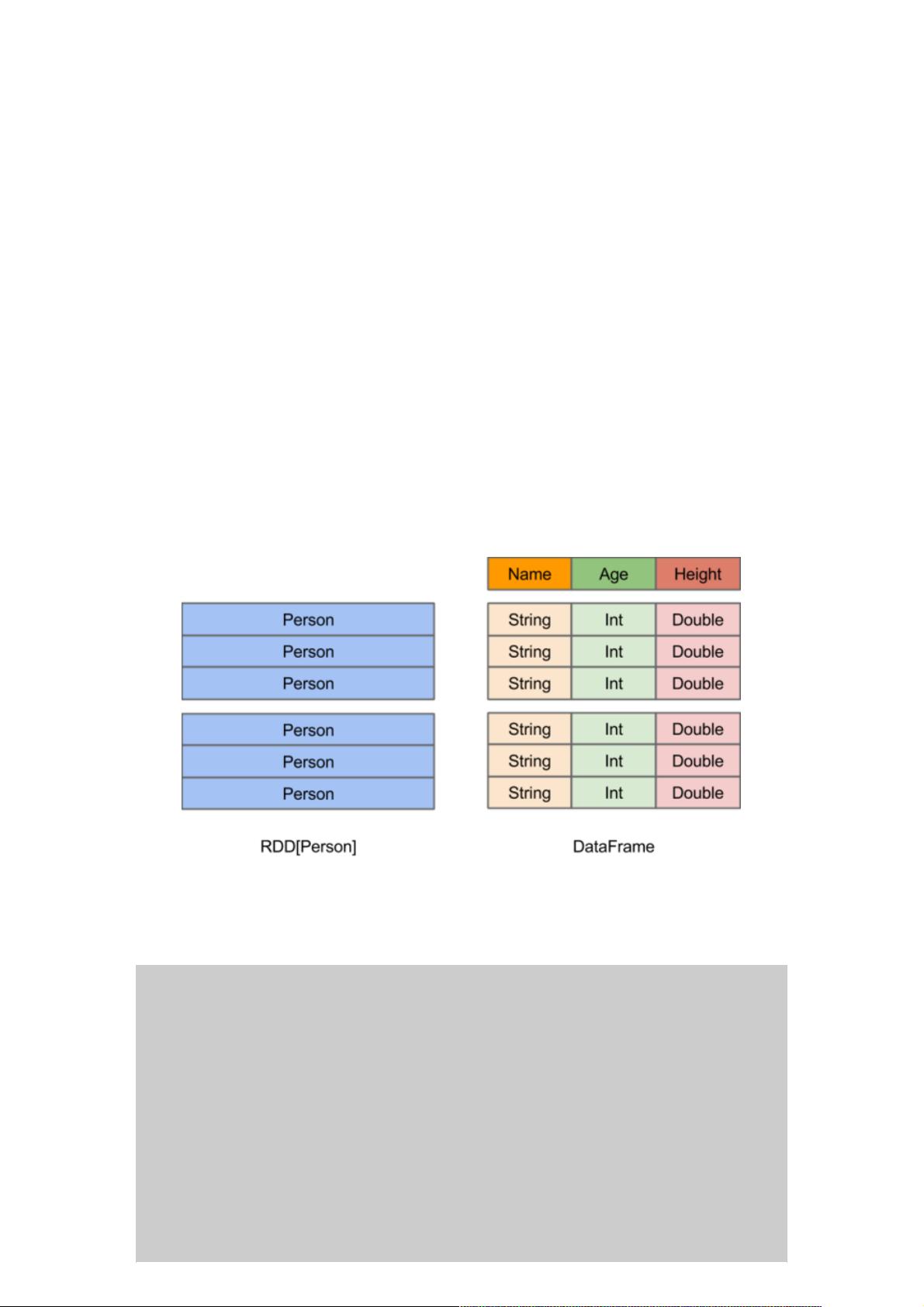
DataFrame在Spark中扮演了关键角色,它是基于RDD的结构化数据集合,每列都有明确的名称和类型(schema),这使得Spark SQL能够理解和优化数据处理过程。DataFrame的schema特性使得Spark SQL能够更好地理解和处理数据,从而提升查询性能,特别适合大数据环境下的复杂操作。相比于RDD,DataFrame提供了更丰富的结构化数据处理能力,这对于数据科学家和开发人员来说是一大福音。
此外,1.3.0版本中,Spark SQL继承了Shark的部分功能,继续为用户提供高性能的SQL on Hadoop解决方案。这表明Spark SQL致力于提供一个全面的结构化数据处理平台,不仅满足SQL查询的需求,还能够无缝集成到Spark的生态系统中,与其他Spark组件如Spark Core协同工作。
作者连城,作为Databricks的工程师和Spark Committer,他在SparkSQL领域有着深厚的技术背景。他在2015年的Spark技术峰会上,通过主题演讲“四两拨千斤——SparkSQL结构化数据分析”,分享了Spark SQL在1.3.0版中的创新和改进,进一步展示了其在大数据分析领域的潜力和价值。
Spark SQL 1.3.0通过DataFrame API的易用性提升和外部数据源API的兼容性增强,展示了其在结构化数据处理上的强大实力和日益增长的实用性,使得Spark成为一个更加易于使用且强大的大数据处理工具。
平易近人、兼容并蓄平易近人、兼容并蓄——SparkSQL1.3.0概览概览
DataFrame API的引入一改RDD API高冷的FP姿态,令Spark变得更加平易近人。外部数据源API体现出的则是兼容并
蓄,Spark SQL多元一体的结构化数据处理能力正在逐渐释放。
关于作者:连城,Databricks工程师,Spark committer,Spark SQL主要开发者之一。在4月18日召开的 2015 Spark技术峰会
上,连城将做名为“四两拨千斤——Spark SQL结构化数据分析”的主题演讲。
自2013年3月面世以来,Spark SQL已经成为除Spark Core以外最大的Spark组件。除了接过Shark的接力棒,继续为Spark用
户提供高性能的SQL on Hadoop解决方案之外,它还为Spark带来了通用、高效、多元一体的结构化数据处理能力。在刚刚发
布的1.3.0版中,Spark SQL的两大升级被诠释得淋漓尽致。
DataFrame
就易用性而言,对比传统的MapReduce API,说Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce
和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。另一方面,数据科学家们所熟悉的R、Pandas等传统数据
框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。为了解决这一矛盾,Spark SQL 1.3.0在原有
SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。新的DataFrame AP不仅可以大幅度降低普通开发者
的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分
布式大数据场景。
DataFrame是什么?是什么?
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区
别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以
洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到
大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简
单、通用的流水线优化。
创建创建DataFrame
在Spark SQL中,开发者可以非常便捷地将各种内、外部的单机、分布式数据转换为DataFrame。以下Python示例代码充分体
现了Spark SQL 1.3.0中DataFrame数据源的丰富多样和简单易用:
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-17 上传
2021-10-17 上传
2021-09-14 上传
2021-10-09 上传
2014-06-26 上传
2008-04-13 上传

weixin_38744778
- 粉丝: 7
- 资源: 917
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
