Indigo诊断工具:智能车辆诊断解决方案
版权申诉
140 浏览量
更新于2024-06-18
收藏 3.33MB PPTX 举报
"Indigo_EN.pptx - 一个关于车载诊断工具Indigo的演示文稿,涵盖Indigo的功能、诊断场景以及车辆数据访问等主题。"
Indigo是Vector公司的一款高级车载诊断工具,专为诊断现代汽车的电子控制单元(ECU)而设计。它在车载诊断领域扮演着重要角色,支持多种通信协议,如统一诊断服务(UDS)、 Keyword Protocol 2000(KWP)、GMW3110、OBD-II和J1939等。Indigo不仅适用于CAN(控制器局域网络)协议,还支持CAN Flexible Data-Rate(CAN FD)和DoIP(诊断_over_IP)等高级通信标准。
1. **自我配置与数据供应**:
Indigo具备自我配置能力,可以根据车辆的具体需求自动调整设置。它通过ODX(Open Diagnostic Data Exchange)、CDD(Common Data Dictionary)或MDX(Mobile Diagnostic Exchange)等标准格式获取和交换车辆数据,确保诊断过程的高效性和准确性。
2. **车辆识别**:
工具提供直接访问车辆识别数据的功能,快速洞察车辆的详细信息,如软件版本、硬件供应商等。这使得用户能够迅速了解车辆配置,为后续的诊断工作奠定基础。
3. **故障记忆诊断**:
在故障记忆场景下,Indigo能即时显示全车的故障码(DTC),提供清晰的ECU故障记忆状态概览。用户可以深入查看单个ECU的详细故障信息,包括确认的故障码、状态以及相关的环境数据和错误条件,有助于快速定位问题。
4. **车辆数据访问**:
为了便于工程师获取特定的车辆参数,Indigo允许用户轻松地从多个ECU中选择并合并参数,形成一个统一视图。在写入服务参数之前,工具会进行读取操作,确保数据的完整性,防止潜在的错误写入。
5. **易用性与灵活性**:
Indigo设计为用户友好且灵活的诊断工具,无论是ECU诊断还是复杂的数据分析,都能适应各种技术水平的用户,简化了诊断流程,提高了工作效率。
通过Indigo,专业技术人员能够更高效地诊断和解决车辆电子系统的问题,同时保证与不同制造商车辆的兼容性。这款工具的全面功能和直观界面使其成为车载诊断领域的得力助手。
5
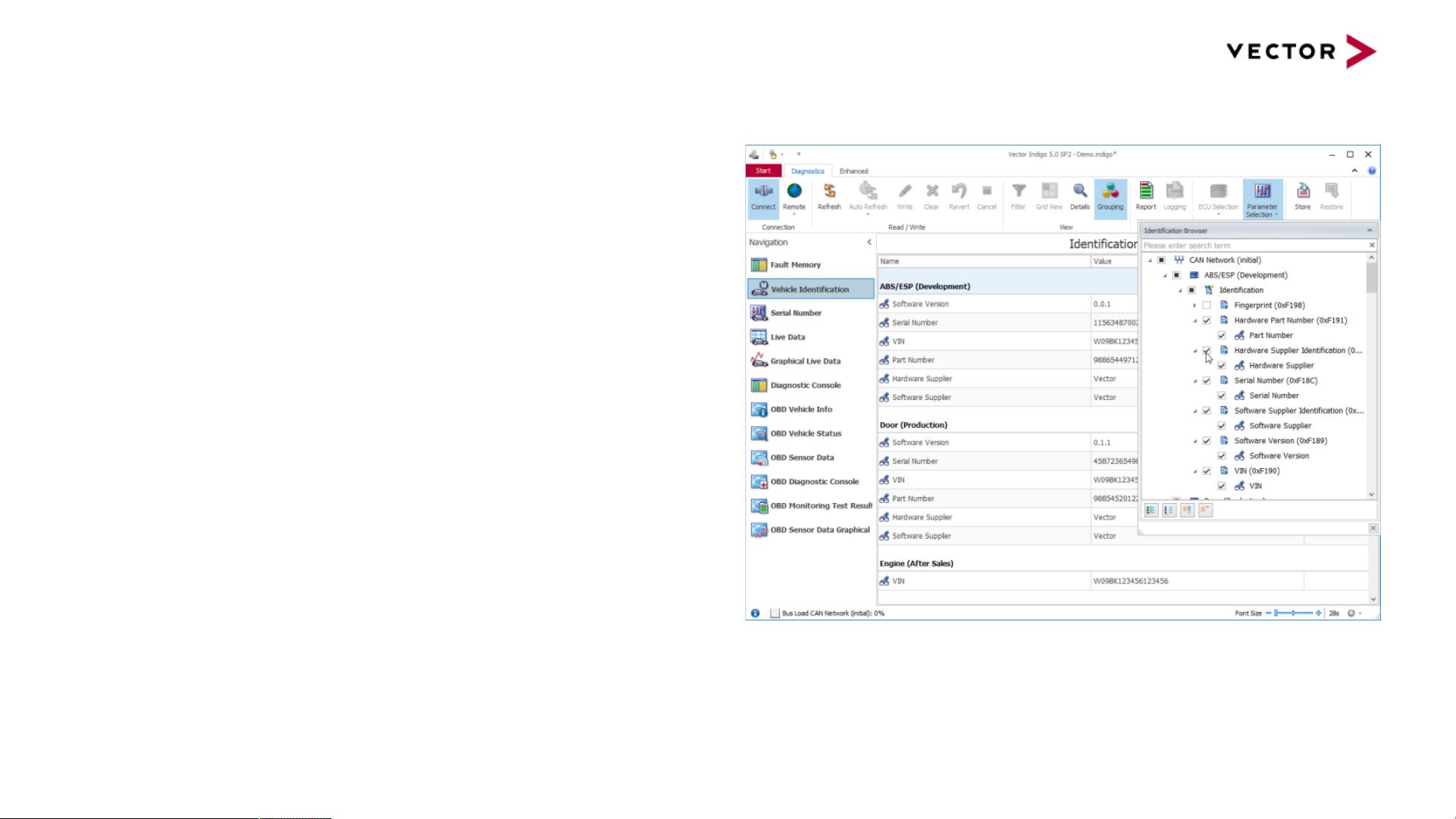
Vehicle Identification
Scenario
Direct access to vehicle identification data
Solution
Quick insight in vehicle to get vehicle
identification overview
> SW version, HW supplier, …
Direct presentation of identified ECU variants
Diagnostic Use Cases
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-12-20 上传
2019-08-07 上传
2023-12-20 上传
2018-01-12 上传
2022-07-14 上传
2020-07-23 上传

车载诊断技术
- 粉丝: 6975
- 资源: 753
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
