Python正则表达式入门指南
47 浏览量
更新于2024-08-30
收藏 208KB PDF 举报
"Python正则表达式的使用方法和常见技巧"
在Python中,正则表达式(Regular Expression)是一种强大的文本处理工具,尤其在处理字符串时。它虽然可能比Python内置的字符串处理方法效率略低,但其灵活性和功能强大,能够处理复杂的数据检索和替换任务。下面将对Python中的正则表达式进行详细讲解。
首先,要使用正则表达式,你需要导入`re`模块。例如:
```python
import re
```
正则表达式的运行原理是制定一个匹配规则,然后应用到目标字符串上,通过正则表达式引擎来找到符合规则的子串。
### 1. `re.findall()`函数的使用
`re.findall()`是正则表达式中最常用的函数之一,它能返回字符串中所有匹配的子串,并以列表形式返回。基础用法如下:
```python
matches = re.findall(r'匹配的规则', '要检索的字符串')
```
例如,找出字符串中所有"bi":
```python
matches = re.findall(r'bi', '某个字符串')
```
### 2. 正则符号的含义与用法
- `^`:匹配字符串的开始。例如,`^abi`会匹配以"abi"开头的字符串。
- `$`:匹配字符串的结束。例如,`gbi$`会匹配以"gbi"结尾的字符串。
- `[...]`:字符集,匹配其中任意一个字符。如`[abcdef]`匹配'a'、'b'、'c'、'd'、'e'或'f'。
- `\d`:匹配0到9之间的数字。`\d{3}`匹配连续的3位数字。
- `\D`:匹配非数字字符。
- `\w`:匹配字母、数字或下划线。相当于[a-zA-Z0-9_]。
- `\W`:匹配除字母、数字和下划线之外的字符。
- `()`:分组,用于捕获和提取特定部分的匹配结果。`.`匹配任意字符,`*`表示前面的字符可以重复任意次(包括0次)。
### 3. 贪婪与非贪婪匹配
默认情况下,正则是贪婪的,会尽可能多地匹配字符。例如,`.+`会匹配尽可能多的任意字符。要进行非贪婪匹配,可以在量词后加上`?`,如`.+?`。
### 4. 其他正则表达式操作
- `re.search()`: 查找第一个匹配项,返回一个匹配对象,如果没有匹配则返回None。
- `re.match()`: 从字符串开头开始匹配,只匹配整个字符串的开始部分。
- `re.sub()`: 替换匹配到的部分,例如`re.sub(r'\d+', 'NUMBER', '123abc')`会将数字替换为'NUMBER'。
- `re.split()`: 使用正则表达式作为分隔符拆分字符串。
掌握这些基本的正则表达式操作和符号,你就能解决大部分字符串处理问题了。不过,正则表达式还有更深入的内容,如零宽断言、反向引用等,需要在实践中不断学习和熟练。在编写代码时,记得根据需求选择最合适的正则表达式,避免过于复杂的规则导致效率下降。
python中正则的使用指南中正则的使用指南
上一次很多朋友写文字屏蔽说到要用正则表达,其实不是我不想用(我正则用得不是很多,看过我之前爬虫的都知道,我直接用
BeautifulSoup的网页标签去找内容,因为容易理解也方便,),而是正则用好用精通的很难(看过正则表的应该都知道,里
面符号对应的方法规则有很多,很灵活),对于接触编程不久的朋友们来说很可能在编程的过程上浪费很多时间,今天我把经
常会用到正则简单介绍下,如果不是很特殊基本都覆盖使用。
1.正则的简单介绍正则的简单介绍
首先你得导入正则方法 import re正则表达式是用于处理字符串的强大工具,拥有自己独立的处理机制,效率上可能不如str自
带的方法,但功能十分灵活给力。它的运行过程是先定一个匹配规则(”你想要的内容+正则语法规则”),放入要匹配的字符
串,通过正则内部的机制就能检索你想要的信息。
2.findall的常用几种姿势的常用几种姿势
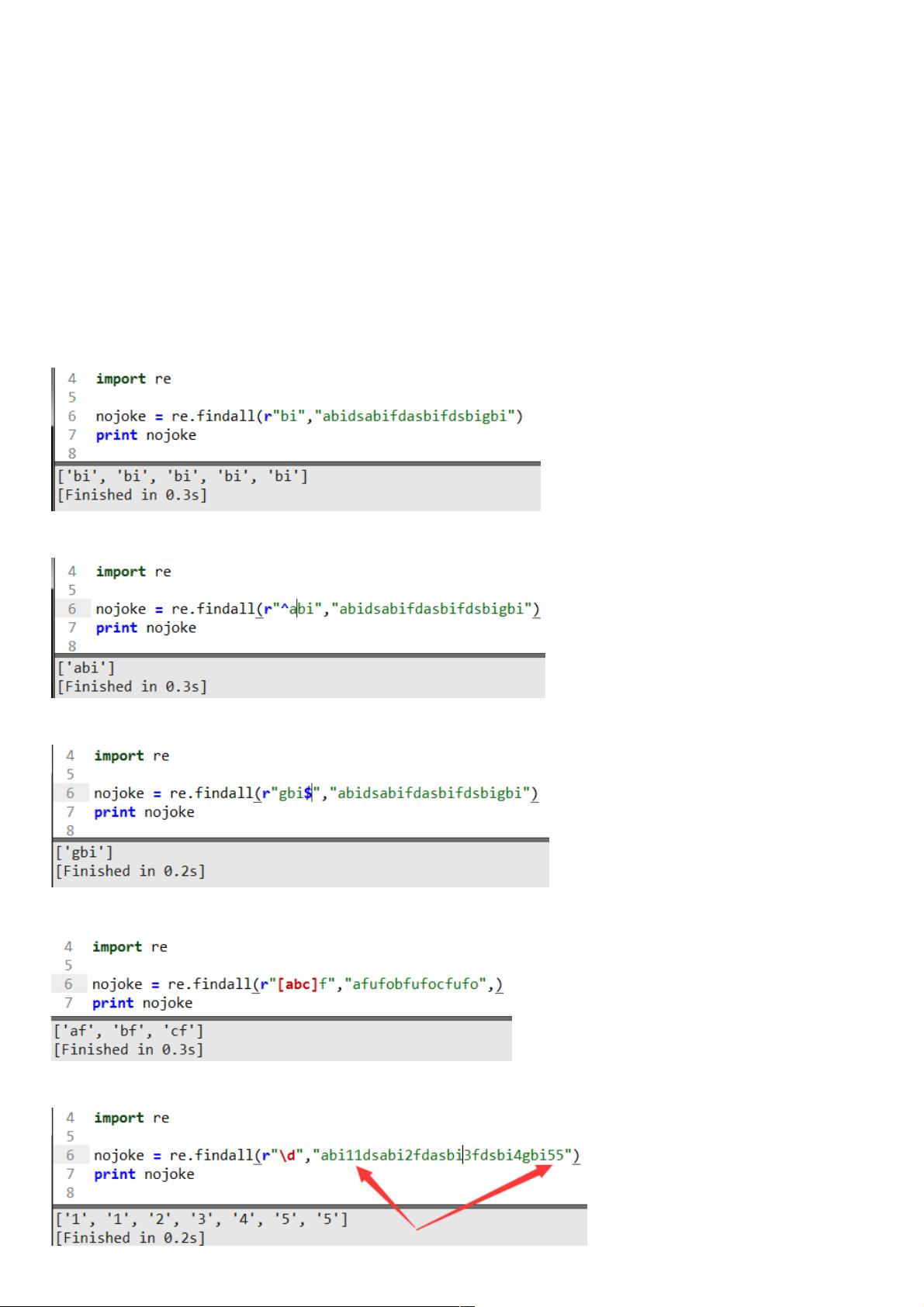
基本结构大致: nojoke = re.findall(r’匹配的规则’,’要检索的愿字符串’) nojoke就是我们最后通过正则返回的结果,re正则findall
查找全部r标识代表后面是正则的语句(这样在代码多的时候好查阅),下面我们看看几个例子好深入了解
这段代码是找出检索字符串中所有的bi并以列表的形式返回,这个会经常用到计算统一字符出现的次数。继续看下一个
这里加了个符号^表示匹配以abi开头的的字符串返回,也可以判断字符串是否以abi开始的。
这里在的用$符号表示以gbi结尾的字符串返回,判断是否字符串结束的字符串。
这里[…]的意思匹配括号内a和f,或者b和f,或者c和f的值返回列表。
下载后可阅读完整内容,剩余3页未读,立即下载
2024-07-07 上传
点击了解资源详情
点击了解资源详情
2020-10-23 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38610012
- 粉丝: 3
- 资源: 866
 我的内容管理
展开
我的内容管理
展开







最新资源
- Voice-User-Interface:LaunchTech支持助理
- school-ms-netcorewebapi:学校管理系统-使用.NET Core构建的Web API
- OLgallery-开源
- 用于在Python中构建功能强大的交互式命令行应用程序的库-Python开发
- ThreatQ Extension-crx插件
- GeoDataViz-Toolkit:GeoDataViz工具包是一组资源,可通过设计引人注目的视觉效果来帮助您有效地传达数据。在此存储库中,我们正在共享资源,资产和其他有用的链接
- SQL-IMDb:关于IMDb数据集的各种约束SQL查询
- AlgaFoodAPI:藻类食品原料药
- wikiBB-开源
- 参考资料-基于SMS的单片机无线监控系统的设计.zip
- emptyproject-pwa:空项目:PWA + jComponent + Total.js
- React计算
- ux_ui_hw_17
- tamarux-开源
- pytest框架使编写小型测试变得容易,但可以扩展以支持复杂的功能测试-Python开发
- StellarTick-crx插件
