Python变量拷贝与作用域:理解浅复制与引用陷阱
102 浏览量
更新于2024-08-29
收藏 300KB PDF 举报
在深入探究Python中的变量拷贝和作用域问题时,首先要明确Python的赋值行为与大多数面向对象(Object-Oriented, OO)语言如C++和Java的不同。在Python中,赋值操作实际上是创建对象的引用,而非复制对象。这意味着当我们说"变量",实际上是指向内存中对象的指针,而非独立的数据存储单元。
举个例子,当你执行`values = [0, 1, 2]`时,Python会创建一个新的列表对象 `[0, 1, 2]`,并为其分配一个标签"values"。如果接着做`values[1] = values`,这并不意味着将`values`的元素值复制给其自身,而是将`values`标签所指向的列表对象的第二个元素设置为指向整个`values`对象。因此,执行后`values`标签仍然指向原始列表,但它的结构已经发生了改变,形成一个循环引用。
要理解这个问题的关键在于,Python中没有像其他语言那样的"值拷贝"概念。例如,如果你想创建一个与`values`对象相同的副本,以便`values[1]`指向的是一个独立的列表,你应该使用切片操作`values[:]`,这会生成一个新的列表对象,而不是共享的引用。这样做的结果就是:
```python
values = [0, 1, 2]
# 使用切片复制列表
copied_values = values[:]
values[1] = copied_values
```
执行这段代码后,你会得到预期的结果`[0, [0, 1, 2], 2]`,因为`values[1]`指向的是一个独立的列表副本,而非原列表本身。
总结来说,Python中的变量更像是标签或引用,而不是存储值的容器。理解这一点对于处理复杂的数据结构和避免意外的行为至关重要。在处理大规模数据或需要确保数据独立性的场景中,熟悉Python的深拷贝和浅拷贝机制(尽管Python默认情况下倾向于深拷贝序列类型)是非常重要的。
深入探究深入探究Python中变量的拷贝和作用域问题中变量的拷贝和作用域问题
在 python 中赋值语句总是建立对象的引用值,而不是复制对象。因此,python 变量更像是指针,而不是数据存储区域,
这点和大多数 OO 语言类似吧,比如 C++、java 等 ~
1、先来看个问题吧:、先来看个问题吧:
在Python中,令values=[0,1,2];values[1]=values,为何结果是[0,[…],2]?
>>> values = [0, 1, 2] >>> values[1] = values
>>> values
[0, [...], 2]
我预想应当是
[0, [0, 1, 2], 2]
但结果却为何要赋值无限次?
可以说 Python 没有赋值,只有引用。你这样相当于创建了一个引用自身的结构,所以导致了无限循环。为了理解这个问题,
有个基本概念需要搞清楚。
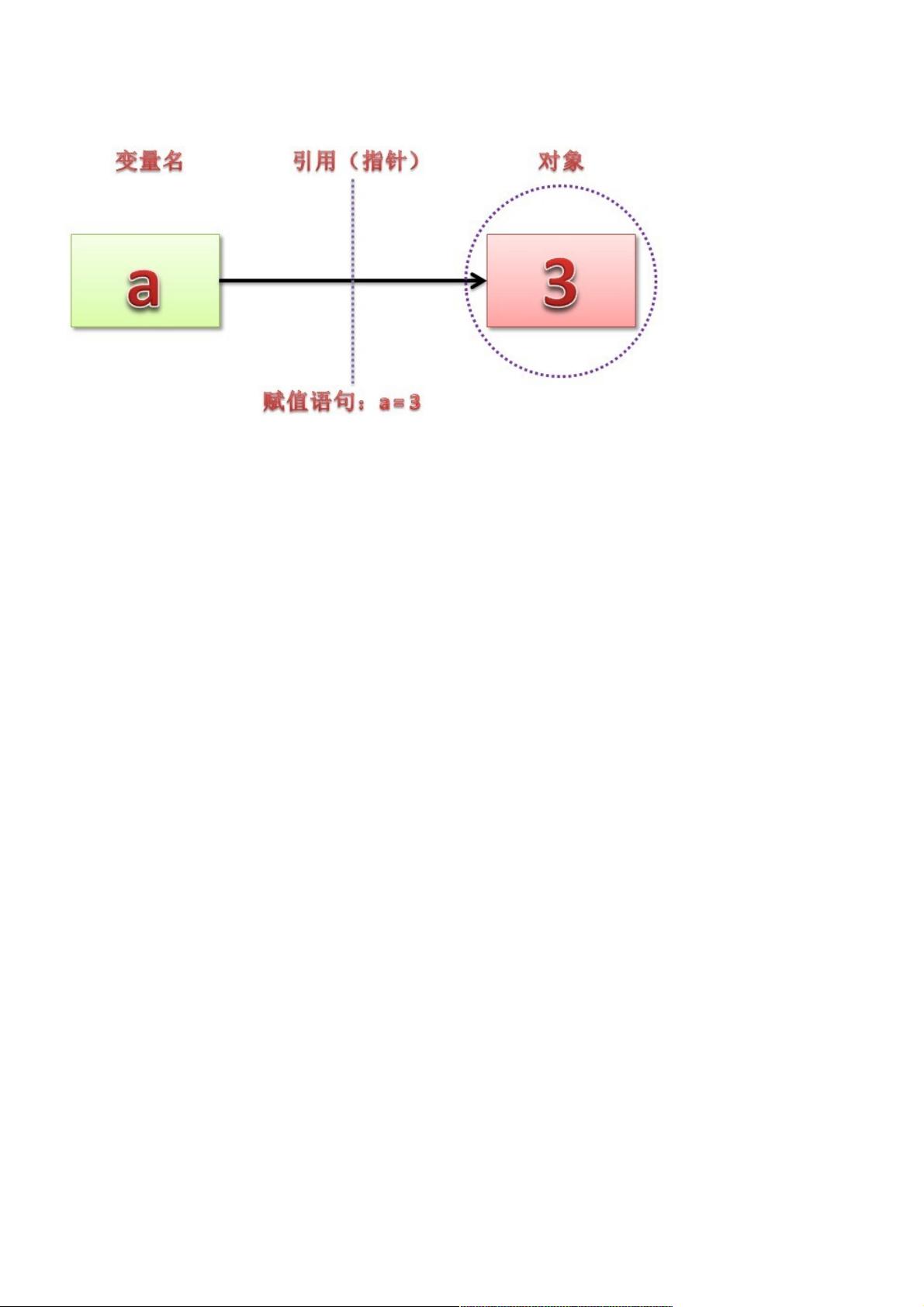
Python 没有「变量」,我们平时所说的变量其实只是「标签」,是引用。
执行
values = [0, 1, 2]
的时候,Python 做的事情是首先创建一个列表对象 [0, 1, 2],然后给它贴上名为 values 的标签。如果随后又执行
values = [3, 4, 5]
的话,Python 做的事情是创建另一个列表对象 [3, 4, 5],然后把刚才那张名为 values 的标签从前面的 [0, 1, 2] 对象上撕下
来,重新贴到 [3, 4, 5] 这个对象上。
至始至终,并没有一个叫做 values 的列表对象容器存在,Python 也没有把任何对象的值复制进 values 去。过程如图所示:
下载后可阅读完整内容,剩余5页未读,立即下载
2021-01-20 上传
2020-09-21 上传
2024-04-12 上传
2023-09-28 上传
2023-09-05 上传
2023-03-14 上传
2023-05-13 上传
2024-04-13 上传
2023-06-07 上传

weixin_38615397
- 粉丝: 6
- 资源: 895
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
