Python dropna()函数详解与参数应用
需积分: 47 61 浏览量
更新于2024-09-02
收藏 2KB MD 举报
Python中的`dropna()`函数是Pandas库中用于处理缺失值(NaN)的重要工具,它允许数据分析师和开发者在DataFrame中清洗数据,确保分析的准确性。本文将详细介绍`dropna()`函数的各个参数及其用法。
首先,我们来看一下`dropna()`的基本语法:
```python
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
```
**参数详解:**
1. **axis** (默认值:0):
- `0`:按照行(rows)进行操作,即删除含有缺失值的行。
- `1`:按列(columns)进行操作,即删除含有缺失值的列。
2. **how** (默认值:'any'):
- `'any'`:如果一行或一列中任何位置有缺失值,则该行或列被删除。这是默认行为。
- `'all'`:如果一行或一列中所有位置都是缺失值,则该行或列被删除。这意味着只有完全为`NaN`的行或列才会被删除。
3. **thresh** (可选):
- 如果提供一个整数,仅保留含有至少`thresh`个非`NaN`值的行或列。如果某行或列的非缺失值数量少于`thresh`,则会被删除。
4. **subset** (可选):
- 如果提供了列表或数组,`dropna()`仅对指定列进行操作,删除这些列中包含缺失值的行。这可以用来针对特定列进行定制化处理。
5. **inplace** (默认值:False):
- 如果设置为`True`,则在原DataFrame上进行操作,直接删除缺失值,而不会返回一个新的DataFrame。如果设置为`False`(默认),则返回一个新的DataFrame,保留原始数据不变。
**示例应用:**
下面是一系列示例,展示了如何使用这些参数来处理DataFrame `df`:
- 原始DataFrame `df`:
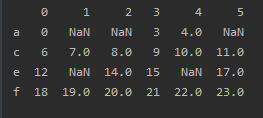
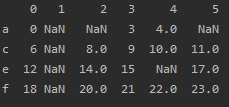
- 删除所有包含`NaN`的行(默认参数):
```python
df = df.dropna()
```
结果:
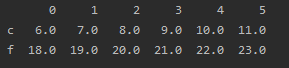
- 删除所有包含`NaN`的列:
```python
df = df.dropna(axis=1)
```
结果:
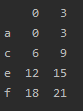
- 将第二列(索引为1)设置为`NaN`后,删除一整列都是`NaN`的列:
```python
df.iloc[:, 1] = np.nan
df = df.dropna(axis=1, how='all')
```
结果:
通过理解并灵活运用`dropna()`函数及其参数,你可以有效地清理和管理数据集中缺失值,确保数据质量和分析的准确性。在实际的数据分析项目中,根据具体需求选择合适的参数组合是至关重要的。
594 浏览量
238 浏览量
102 浏览量
205 浏览量
451 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
129 浏览量

bamboo_128
- 粉丝: 5
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- kangle-vhms-2.6.8.zip
- 雪山攀登背景的团队凝聚力PPT模板
- key-by-val:通过对象中的值查找键
- emonpi:基于Raspberry Pi的能源监控器。 PI的硬件,固件和相关软件
- my-portfolio
- ProjetoVendas:Primeiro Projeto em C#
- Siminov Framework-Connect-Android RESTful框架
- 黄金矿工HTML5游戏源码
- Angrily_Learn_Java_8
- numi:适用于macOS的精美计算器应用程序
- ROS机器人代码包.rar
- 清新绿色竹林PPT模板
- SCART接口 EMC设计标准电路与技术资料-综合文档
- man子手
- asciidoctor-diagram, Asciidoctor图扩展,支持 PlantUML,Graphviz和 ditaa.zip
- 高清HDR贴图:室内全景
